
Kvantitativní vlastnosti soustavy českých fonémů
Marie Ludvíková, Jiří Kraus
[Články]
Количественные свойства системы чешских фонем / Propriétés quantitatives du système des phonèmes tchèques
V této práci předkládáme výsledky další etapy poznávání informačněteoretických charakteristik současné češtiny, navazující na stať L. Doležela Předběžný odhad entropie a redundance psané češtiny (SaS 24, 1963, 165—175). Náš průzkum se opírá o fonologický přepis textů psané řeči; jeho pokračováním bude zjišťování charakteristik textů mluvených, zachycených magnetofonem. Přes relativní nezakončenost této první části popisu fungování českého fonologického systému jsme přesvědčeni o jisté užitečnosti uvedených údajů, které mohou sloužit prvnímu porovnání fonologické a grafematické soustavy současné češtiny i srovnání s některými výsledky uváděnými pro jiné jazyky.
Důležitým předpokladem pro provedení celé, poměrně rozsáhlé statistiky (počet zkoumaných jednotek dosáhl téměř 187 000) bylo stanovení zásad jednotného přepisu textů.
A) Inventář obsahuje 10 fonémů vokalických (a, e, i, o, u s příslušnými délkami), 25 fonémů konsonantických (p, b, t, d, ť, ď, k, g, f, v, s, z, š, ž, h, ch, c, č, m, n, ň, l, r, ř, j), tři fonémy dvojhláskové (ou, au, eu) a symbol pro hranici mezi slovy (—).
Fonémy g a f jsou zahrnuty do soupisu proto, že se podle našeho názoru zařadily do systému fonologických opozic z hlediska synchronního a také v oblasti lexika není důvodu považovat slova za cizí proto, že obsahují g a f; zejména to platí pro texty odborné.[1]
Dvojhlásky au a eu byly zařazeny jako zvláštní jednotky pro svůj výskyt v některých frekventovaných přejatých slovech. Soudíme, že tyto případy, které se ne vždy shodují s českou fonologickou tradicí, neovlivní podstatněji výsledky uváděných statistik.
B) Pravidla přepisu se řídila výslovností uváděnou v Pravidlech českého pravopisu (Praha 1957) a ve Výslovnosti spisovné češtiny (Praha 1955). Důsledně jsme respektovali znělostní asimilaci, a to i na slovní hranici. Protože naším cílem bylo získat fonologický přepis pečlivé výslovnosti, zachovali jsme konsonantické skupiny nezjednodušené (jmění, půjčit, tloušťka) s výjimkou prézentních tvarů slovesa být [sem, si sme, ste] a slova dcera [cera]. Geminované souhlásky se přepisovaly jako jeden foném s výjimkou případů, kde se jimi rozlišuje význam [babičin, ale: raci × racci].
Vedle stránky kvantitativní, jakou je statistická reprezentativnost vybíraných souborů, jsme považovali za užitečné přihlédnout i k stránce kvalitativní, tj. k stylovému zaměření materiálu. I když soudíme, že rozložení fonémů není závislé na charakteru textů, jsou-li výběry dostatečně veliké,[2] přece jen byla stylová různorodost jistým předpokladem zobecnění získaných výsledků pro jazyk jako celek. Výběr různých stylů byl potřebný i proto, že mezi zkou[335]manými jednotkami je také symbol pro slovní hranici, jehož rozložení odpovídá rozložení délky slov a je tedy ovlivněno sémantickou výstavbou textu.
Podkladem statistiky je soubor textů z řady různých stylových oblastí. V deseti výběrech, které jsme zvolili, je zastoupen styl odborný (Wolfova Učebnice histologie a kuchařská kniha Úlehlové Vaříme zdravě a účelně), styl publicistický (Rudé právo a Večerní Praha), umělecká próza (Hrubín, U stolu a Fried, Časová tíseň), poezie (Hrubín, Romance pro křídlovku a Florian, Na každém kroku, Otevřený dům a Blízký hlas) a drama (Hrubín, Křišťálová noc a Topol, Jejich den). Hrubín byl do tří stylových oblastí zařazen záměrně se zřetelem k tomu, aby bylo možno poznávat styl autora píšícího v různých uměleckých žánrech.
Fonologický soubor vycházel v podstatě ze stejných textů jako uvedený soubor grafematický, liší se však metodou statistického výběru. Zatímco Doležel využíval v citovaném článku souborů pořízených pomocí mechanického oblastního výběru ze sedmi textů, opírá se naše statistika o 10 souborů po 250 větách vybraných na základě tabulky náhodných čísel. Tento způsob výběru odstraňuje nebezpečí, že výsledek bude zkreslen tematicky podmíněným výskytem slov opakujících se v souvislém textu. Vybrané věty byly fonologicky přepsány na lístky a naděrovány na pásku,[3] takže jsou použitelné pro různé účely kvantitativního zpracování češtiny. Materiál je statisticky reprezentativní téměř pro všechny fonémy a pro skupinu nejčetnějších digramů. Za jednotku výběru jsme zvolili větu, kterou chápeme jako sled symbolů mezi dvěma tečkami.
Vedle Mathesiova, Trnkova, Vachkova a Krámského[4] kvantitativního zpracování některých oblastí fonologie byla zvuková podoba češtiny soustavně zpracována dvakrát. První statistiku českých hlásek uveřejnila Mázlová.[5] Vedle cíle porovnat češtinu s jinými jazyky si kladla ještě cíl druhý — zhodnocení libozvučnosti projevující se hlavně ve vokalické složce jazyka; neomezila se jen na údaje o českých hláskách, ale zachytila i výskyt různých typů slabik a typy a délku nejfrekventovanějších slov. Relativní četnosti českých fonémů zjišťoval H. Kučera[6] na základě fonologické analýzy textu prováděné samočinným počítačem. Kučerova práce je součástí rozsáhlého projektu informačněteoretické analýzy slovanských i některých neslovanských jazyků prováděné na Brownově universitě v USA a může být pro nás užitečným porovnávacím materiálem.
Naše fonologická statistika byla zpracována zčásti ručně, zčásti na samočinném počítači, kterého bylo využito zvl. pro zjišťování četností digramů a při výpočtu entropie. Statistický soubor obsahuje 186 641 fonémů obsažených v 30 976 slovech. Relativní četnosti fonémů zaměřené na odhad informačněteoretických charakteristik a k srovnání fonologické a grafematické soustavy se počítaly včetně symbolu pro slovní hranici (tab. I). Vedle toho byly stanoveny relativní četnosti fonémů bez pauzy; uvedli jsme je v tabulce II ve srovnání s výsledky dosavadních fonologických statistik. V pořadí jednotek se všechny tři statistiky v podstatě shodují.
[336]Tab. I. Relativní četnosti fonologických symbolů v češtině
| podle abcedy | podle klesajících četností | ||
| a á b c č d ď e é f g h ch i í j k l m n ň o ó p r ř s š t ť u ú v z ž ou au eu pauza | 0,05561 0,02000 0,01530 0,01149 0,00801 0,02284 0,00400 0,08163 0,01039 0,00610 0,00339 0,01062 0,00997 0,05014 0,03362 0,02412 0,03354 0,03622 0,03093 0,03800 0,01665 0,05754 0,00055 0,02592 0,03015 0,01006 0,03920 0,01028 0,03973 0,00713 0,02298 0,00485 0,03235 0,01622 0,00697 0,00732 0,00021 — 0,16597 | pauza e o a i t s n l í k v m r p j u d á ň z b c h é š ř ch č ou ť ž f ú ď g ó au eu | 0,16597 0,08163 0,05754 0,05561 0,05014 0,03973 0,03920 0,03800 0,03622 0,03362 0,03354 0,03235 0,03093 0,03015 0,02592 0,02412 0,02298 0,02284 0,02000 0,01665 0,01622 0,01530 0,01149 0,01062 0,01039 0,01028 0,01006 0,00997 0,00801 0,00732 0,00713 0,00697 0,00610 0,00485 0,00400 0,00339 0,00055 0,00021 — |
| 1,00000 | 1,00000 | ||
Pozn.: Relativní četnost eu je nižší než 10-5.
Relativní četnosti fonémů podávají kvantitativní obraz obecných strukturních vlastností a vztahů fonologického systému. Nejfrekventovanější jsou v češtině nejjednodušší zvukové prvky soustavy, krátké vokály. Maximální četnost vo-
Příloha k článku M. Ludvíková - J. Kraus: Kvantitativní vlastnosti soustavy českých fonémů (ke s. 339).
Tab. IV
|
| A | Á | B | C | Č | D |
| A | 0,00002 | — | 0,00095 | 0,00085 | 0,00083 | 0,00203 |
| Á | — | — | 0,00015 | 0,00061 | 0,00029 | 0,00094 |
| B | 0,00122 | 0,00026 | — | — | — | 0,00006 |
| C | 0,00004 | 0,00002 | — | — | — | — |
| Č | 0,00052 | 0,00022 | — | 0,00007 | — | — |
| D | 0,00131 | 0,00144 | 0,00022 | — | — | — |
| Ď | 0,00005 | 0,00002 | — | — | — | — |
| E | 0,00006 | 0,00006 | 0,00184 | 0,00093 | 0,00142 | 0,00285 |
| É | — | — | 0,00004 | 0,00002 | 0,00003 | 0,00009 |
| F | 0,00019 | 0,00009 | — | 0,00015 | 0,00015 | — |
| G | 0,00033 | 0,00015 | — | — | — | 0,00133 |
| H | 0,00066 | 0,00025 | — | — | — | — |
| CH | 0,00029 | 0,00040 | — | 0,00011 | 0,00003 | — |
| I | 0,00003 | — | 0,00078 | 0,00221 | 0,00098 | 0,00083 |
| Í | — | — | 0,00033 | 0,00127 | 0,00027 | 0,00037 |
| J | 0,00279 | 0,00090 | 0,00003 | 0,00009 | 0,00007 | 0,00042 |
| K | 0,00348 | 0,00132 | — | 0,00012 | 0,00003 | — |
| L | 0,00574 | 0,00184 | 0,00008 | 0,00014 | 0,00007 | 0,00002 |
| M | 0,00213 | 0,00113 | 0,00024 | 0,00007 | 0,00002 | — |
| N | 0,00774 | 0,00289 | 0,00003 | 0,00082 | 0,00014 | 0,00050 |
| Ň | 0,00002 | 0,00003 | — | 0,00007 | — | — |
| O | 0,00010 | 0,00002 | 0,00278 | 0,00087 | 0,00096 | 0,00351 |
| Ó | — | — | 0,00001 | — | — | — |
| P | 0,00224 | 0,00050 | — | 0,00012 | 0,00010 | — |
| R | 0,00482 | 0,00273 | 0,00011 | 0,00007 | 0,00021 | 0,00015 |
| Ř | 0,00025 | 0,00025 | 0,00005 | — | 0,00001 | — |
| S | 0,00080 | 0,00030 | — | 0,00013 | 0,00005 | — |
| Š | 0,00055 | 0,00003 | — | 0,00005 | — | — |
| T | 0,00485 | 0,00132 | — | 0,00036 | 0,00010 | — |
| Ť | 0,00004 | 0,00011 | — | — | — | — |
| U | 0,00003 | — | 0,00044 | 0,00023 | 0,00026 | 0,00121 |
| Ú | — | — | 0,00009 | 0,00002 | 0,00014 | 0,00005 |
| V | 0,00382 | 0,00234 | 0,00010 | — | — | 0,00010 |
| Z | 0,00321 | 0,00123 | 0,00046 | — | — | 0,00099 |
| Ž | 0,00013 | 0,00013 | 0,00005 | — | — | 0,00055 |
| OU | — | — | 0,00015 | 0,00015 | 0,00018 | 0,00009 |
| AU | — | — | — | — | — | — |
| Pauza | 0,00815 | 0,00002 | 0,00637 | 0,00196 | 0,00167 | 0,00675 |
| Σ | 0,05561 | 0,02000 | 0,01530 | 0,01149 | 0,00801 | 0,02284 |
|
| Ď | E | É | F | G | H |
| A | 0,00053 | 0,00002 | — | 0,00032 | 0,00043 | 0,00069 |
| Á | 0,00009 | — | — | 0,00008 | — | 0,00030 |
| B | 0,00007 | 0,00106 | — | — | — | — |
| C | — | 0,00395 | 0,00005 | — | — | — |
| Č | — | 0,00219 | — | — | — | — |
| D | 0,00007 | 0,00327 | 0,00041 | — | 0,00001 | 0,00005 |
| Ď | — | 0,00147 | — | — | — | — |
| E | 0,00058 | 0,00001 | — | 0,00054 | 0,00040 | 0,00090 |
| É | — | — | — | 0,00010 | — | 0,00128 |
| F | — | 0,00020 | 0,00002 | — | — | — |
| G | — | 0,00026 | 0,00002 | — | — | — |
| H | — | 0,00023 | 0,00015 | — | — | — |
| CH | — | 0,00018 | 0,00006 | — | — | — |
| I | 0,00037 | — | — | 0,00024 | 0,00038 | 0,00032 |
| Í | 0,00008 | — | — | 0,00010 | 0,00002 | 0,00053 |
| J | 0,00002 | 0,01147 | 0,00003 | 0,00001 | — | 0,00001 |
| K | — | 0,00089 | 0,00184 | — | — | — |
| L | — | 0,00590 | 0,00129 | — | 0,00005 | 0,00008 |
| M | — | 0,00436 | 0,00052 | 0,00003 | — | 0,00002 |
| N | 0,00005 | 0,00777 | 0,00277 | 0,00005 | 0,00007 | — |
| Ň | — | 0,00624 | — | — | — | — |
| O | 0,00068 | 0,00003 | — | 0,00059 | 0,00026 | 0,00152 |
| Ó | — | — | — | — | — | — |
| P | — | 0,00115 | 0,00006 | — | — | — |
| R | 0,00006 | 0,00172 | 0,00054 | 0,00005 | 0,00026 | 0,00023 |
| Ř | — | 0,00420 | — | — | — | — |
| S | — | 0,00683 | 0,00002 | 0,00001 | — | — |
| Š | — | 0,00155 | — | — | — | — |
| T | — | 0,00506 | 0,00092 | — | — | — |
| Ť | — | 0,00234 | — | — | — | — |
| U | 0,00014 | — | — | 0,00003 | 0,00003 | 0,00044 |
| Ú | — | — | — | 0,00003 | — | — |
| V | 0,00005 | 0,00339 | 0,00166 | — | — | 0,00003 |
| Z | 0,00018 | 0,00268 | 0,00002 | — | — | 0,00023 |
| Ž | 0,00011 | 0,00263 | — | — | — | 0,00003 |
| OU | 0,00004 | — | — | 0,00005 | — | 0,00028 |
| AU | — | — | — | — | — | — |
| Pauza | 0,00088 | 0,00058 | 0,00001 | 0,00387 | 0,00148 | 0,00368 |
| Σ | 0,00400 | 0,08163 | 0,01039 | 0,00610 | 0,00339 | 0,01062 |
|
| CH | I | Í | J | K | L |
| A | 0,00036 | 0,00001 | — | 0,00154 | 0,00465 | 0,00424 |
| Á | 0,00045 | — | — | 0,00023 | 0,00056 | 0,00159 |
| B | — | 0,00306 | 0,00081 | 0,00091 | — | 0,00074 |
| C | — | 0,00231 | 0,00137 | — | 0,00123 | 0,00005 |
| Č | — | 0,00107 | 0,00078 | — | 0,00094 | 0,00020 |
| D | — | 0,00238 | 0,00032 | 0,00004 | — | 0,00135 |
| Ď | — | 0,00108 | 0,00127 | — | — | — |
| E | 0,00171 | 0,00002 | 0,00003 | 0,00319 | 0,00326 | 0,00505 |
| É | — | — | — | 0,00001 | 0,00025 | 0,00003 |
| F | — | 0,00031 | — | — | 0,00036 | 0,00004 |
| G | — | 0,00020 | — | — | — | 0,00009 |
| H | — | 0,00048 | 0,00017 | — | — | 0,00157 |
| CH | — | 0,00030 | 0,00006 | — | 0,00007 | 0,00050 |
| I | 0,00116 | — | — | 0,00198 | 0,00156 | 0,00373 |
| Í | 0,00323 | — | — | 0,00019 | 0,00085 | 0,00068 |
| J | 0,00001 | 0,00201 | 0,00295 | 0,00003 | 0,00008 | 0,00007 |
| K | — | 0,00279 | 0,00106 | — | — | 0,00169 |
| L | 0,00003 | 0,00564 | 0,00170 | 0,00004 | 0,00073 | — |
| M | 0,00001 | 0,00375 | 0,00138 | — | 0,00008 | 0,00059 |
| N | 0,00003 | 0,00175 | 0,00197 | — | 0,00094 | 0,00003 |
| Ň | — | 0,00261 | 0,00670 | — | 0,00057 | — |
| O | 0,00056 | 0,00007 | 0,00004 | 0,00136 | 0,00196 | 0,00318 |
| Ó | — | — | — | — | — | 0,00005 |
| P | 0,00005 | 0,00098 | 0,00050 | 0,00058 | 0,00023 | 0,00164 |
| R | 0,00022 | 0,00229 | 0,00077 | — | 0,00059 | 0,00006 |
| Ř | — | 0,00216 | 0,00234 | — | 0,00008 | 0,00002 |
| S | 0,00025 | 0,00214 | 0,00092 | 0,00005 | 0,00368 | 0,00212 |
| Š | — | 0,00072 | 0,00139 | — | 0,00082 | 0,00028 |
| T | 0,00005 | 0,00163 | 0,00063 | — | 0,00125 | 0,00067 |
| Ť | — | 0,00237 | 0,00143 | — | 0,00003 | — |
| U | 0,00035 | — | — | 0,00140 | 0,00109 | 0,00092 |
| Ú | 0,00003 | — | — | 0,00017 | 0,00005 | 0,00026 |
| V | — | 0,00458 | 0,00364 | 0,00261 | — | 0,00109 |
| Z | — | 0,00093 | 0,00045 | 0,00006 | — | 0,00046 |
| Ž | — | 0,00120 | 0,00092 | — | — | 0,00014 |
| OU | 0,00006 | — | — | — | 0,00027 | 0,00002 |
| AU | — | — | — | — | 0,00002 | — |
| Pauza | 0,00141 | 0,00130 | 0,00002 | 0,00973 | 0,00734 | 0,00307 |
| Σ | 0,00997 | 0,05014 | 0,03362 | 0,02412 | 0,03354 | 0,03622 |
|
| M | N | Ň | O | Ó | P |
| A | 0,00198 | 0,00268 | 0,00071 | 0,00003 | — | 0,00104 |
| Á | 0,00179 | 0,00091 | 0,00091 | — | — | 0,00022 |
| B | 0,00001 | 0,00031 | 0,00023 | 0,00193 | — | — |
| C | — | 0,00013 | 0,00004 | 0,00091 | — | — |
| Č | 0,00001 | 0,00057 | 0,00059 | 0,00012 | — | 0,00002 |
| D | 0,00005 | 0,00177 | 0,00100 | 0,00397 | — | — |
| Ď | — | — | — | 0,00003 | — | — |
| E | 0,00575 | 0,00618 | 0,00244 | 0,00034 | 0,00002 | 0,00131 |
| É | 0,00107 | 0,00028 | 0,00010 | — | — | 0,00007 |
| F | — | — | 0,00002 | 0,00018 | — | — |
| G | 0,00009 | — | 0,00001 | 0,00011 | 0,00002 | — |
| H | 0,00015 | 0,00045 | 0,00003 | 0,00419 | — | — |
| CH | 0,00001 | 0,00039 | 0,00012 | 0,00074 | — | 0,00001 |
| I | 0,00082 | 0,00287 | 0,00034 | 0,00002 | — | 0,00080 |
| Í | 0,00455 | 0,00087 | 0,00013 | — | — | 0,00024 |
| J | 0,00036 | 0,00024 | 0,00011 | 0,00058 | 0,00007 | 0,00007 |
| K | 0,00015 | 0,00037 | 0,00019 | 0,00509 | 0,00002 | — |
| L | 0,00018 | 0,00065 | 0,00108 | 0,00359 | 0,00005 | 0,00001 |
| M | — | 0,00066 | 0,00217 | 0,00180 | — | 0,00017 |
| N | — | — | — | 0,00352 | 0,00002 | — |
| Ň | — | — | — | 0,00007 | — | — |
| O | 0,00240 | 0,00159 | 0,00038 | 0,00002 | — | 0,00185 |
| Ó | 0,00012 | 0,00011 | 0,00003 | — | — | — |
| P | 0,00001 | 0,00011 | 0,00005 | 0,00701 | 0,00007 | — |
| R | 0,00028 | 0,00076 | 0,00055 | 0,00655 | 0,00003 | 0,00020 |
| Ř | 0,00009 | 0,00001 | 0,00004 | 0,00007 | — | 0,00002 |
| S | 0,00116 | 0,00062 | 0,00038 | 0,00116 | 0,00003 | 0,00187 |
| Š | — | 0,00014 | 0,00012 | 0,00005 | — | 0,00012 |
| T | 0,00015 | 0,00054 | 0,00074 | 0,00549 | 0,00014 | 0,00027 |
| Ť | — | — | — | 0,00010 | — | — |
| U | 0,00056 | 0,00065 | 0,00105 | 0,00011 | — | 0,00089 |
| Ú | 0,00024 | 0,00005 | 0,00010 | — | — | 0,00017 |
| V | 0,00001 | 0,00042 | 0,00068 | 0,00241 | 0,00001 | — |
| Z | 0,00061 | 0,00096 | 0,00035 | 0,00075 | 0,00002 | — |
| Ž | — | 0,00026 | 0,00008 | 0,00012 | — | — |
| OU | 0,00002 | 0,00005 | — | — | — | 0,00024 |
| AU | — | 0,00002 | — | — | — | — |
| Pauza | 0,00831 | 0,01238 | 0,00188 | 0,00648 | 0,00005 | 0,01633 |
| Σ | 0,03093 | 0,03800 | 0,01665 | 0,05754 | 0,00055 | 0,02592 |
|
| R | Ř | S | Š | T | Ť |
| A | 0,00179 | 0,00063 | 0,00253 | 0,00076 | 0,00308 | 0,00048 |
| Á | 0,00058 | 0,00044 | 0,00112 | 0,00047 | 0,00151 | 0,00017 |
| B | 0,00134 | 0,00034 | — | — | — | — |
| C | — | — | — | — | 0,00017 | 0,00001 |
| Č | — | — | — | — | 0,00025 | 0,00003 |
| D | 0,00143 | 0,00019 | — | — | — | — |
| Ď | — | — | — | — | — | — |
| E | 0,00339 | 0,00051 | 0,00318 | 0,00153 | 0,00365 | 0,00059 |
| É | 0,00019 | 0,00002 | 0,00005 | 0,00010 | 0,00023 | 0,00001 |
| F | 0,00018 | — | 0,00048 | 0,00124 | 0,00006 | 0,00001 |
| G | 0,00017 | — | — | — | — | — |
| H | 0,00086 | 0,00019 | — | — | — | — |
| CH | 0,00033 | 0,00003 | 0,00002 | 0,00004 | 0,00014 | 0,00011 |
| I | 0,00042 | 0,00017 | 0,00262 | 0,00126 | 0,00333 | 0,00032 |
| Í | 0,00081 | 0,00033 | 0,00091 | 0,00066 | 0,00086 | 0,00036 |
| J | 0,00003 | — | 0,00022 | 0,00038 | 0,00005 | 0,00004 |
| K | 0,00203 | 0,00034 | 0,00017 | — | 0,00193 | 0,00002 |
| L | — | — | 0,00016 | 0,00019 | 0,00017 | 0,00002 |
| M | 0,00045 | 0,00003 | 0,00005 | 0,00008 | 0,00007 | — |
| N | 0,00002 | — | 0,00047 | 0,00011 | 0,00083 | 0,00004 |
| Ň | — | — | 0,00005 | 0,00001 | — | — |
| O | 0,00236 | 0,00062 | 0,00410 | 0,00045 | 0,00303 | 0,00047 |
| Ó | 0,00003 | — | 0,00001 | — | — | — |
| P | 0,00501 | 0,00355 | 0,00027 | 0,00011 | 0,00023 | 0,00001 |
| R | — | — | 0,00061 | 0,00019 | 0,00061 | 0,00015 |
| Ř | — | — | 0,00012 | — | — | — |
| S | 0,00027 | 0,00003 | — | 0,00005 | 0,00851 | 0,00158 |
| Š | 0,00001 | — | 0,00019 | — | 0,00019 | 0,00097 |
| T | 0,00298 | 0,00134 | 0,00048 | 0,00026 | 0,00002 | 0,00005 |
| Ť | — | — | — | — | 0,00002 | — |
| U | 0,00040 | 0,00004 | 0,00110 | 0,00104 | 0,00101 | 0,00028 |
| Ú | 0,00023 | 0,00006 | 0,00052 | 0,00003 | 0,00014 | 0,00001 |
| V | 0,00084 | 0,00020 | — | — | — | — |
| Z | 0,00025 | 0,00007 | — | — | — | — |
| Ž | 0,00002 | — | — | — | — | — |
| OU | — | 0,00005 | 0,00038 | 0,00023 | 0,00033 | 0,00014 |
| AU | 0,00003 | — | — | — | 0,00012 | — |
| Pauza | 0,00370 | 0,00088 | 0,01939 | 0,00109 | 0,00919 | 0,00126 |
| Σ | 0,03015 | 0,01006 | 0,03920 | 0,01028 | 0,03973 | 0,00713 |
|
| U | Ú | V | Z | Ž |
| A | 0,00003 | — | 0,00272 | 0,00116 | 0,00066 |
| Á | — | — | 0,00155 | 0,00068 | 0,00024 |
| B | 0,00249 | 0,00005 | 0,00005 | 0,00006 | 0,00007 |
| C | 0,00012 | 0,00017 | 0,00007 | — | — |
| Č | 0,00013 | — | — | — | — |
| D | 0,00119 | 0,00025 | 0,00072 | 0,00015 | 0,00003 |
| Ď | — | — | — | — | — |
| E | 0,00009 | 0,00001 | 0,00113 | 0,00152 | 0,00063 |
| É | — | — | 0,00009 | 0,00001 | 0,00002 |
| F | 0,00007 | — | — | — | — |
| G | 0,00007 | 0,00001 | — | 0,00008 | 0,00003 |
| H | 0,00062 | 0,00003 | 0,00012 | — | — |
| CH | 0,00042 | 0,00011 | 0,00037 | — | — |
| I | 0,00003 | — | 0,00135 | 0,00055 | 0,00020 |
| Í | — | — | 0,00093 | 0,00027 | 0,00025 |
| J | 0,00013 | 0,00005 | 0,00016 | 0,00003 | 0,00002 |
| K | 0,00286 | 0,00047 | 0,00029 | — | — |
| L | 0,00161 | 0,00023 | 0,00005 | 0,00012 | 0,00030 |
| M | 0,00156 | 0,00051 | 0,00002 | — | 0,00005 |
| N | 0,00136 | 0,00019 | 0,00005 | 0,00005 | 0,00004 |
| Ň | 0,00005 | — | — | — | — |
| O | 0,00015 | — | 0,00571 | 0,00172 | 0,00069 |
| Ó | — | — | — | 0,00012 | — |
| P | 0,00049 | 0,00029 | — | — | — |
| R | 0,00228 | 0,00055 | 0,00092 | 0,00017 | 0,00029 |
| Ř | 0,00004 | 0,00005 | 0,00001 | — | — |
| S | 0,00057 | 0,00017 | 0,00152 | — | — |
| Š | 0,00019 | 0,00001 | 0,00003 | — | — |
| T | 0,00206 | 0,00046 | 0,00154 | — | — |
| Ť | 0,00002 | — | — | — | — |
| U | — | — | 0,00027 | 0,00027 | 0,00037 |
| Ú | — | — | 0,00010 | 0,00010 | 0,00040 |
| V | 0,00055 | 0,00029 | — | 0,00057 | 0,00033 |
| Z | 0,00036 | 0,00015 | 0,00059 | — | 0,00005 |
| Ž | 0,00009 | 0,00003 | 0,00002 | — | — |
| OU | — | — | 0,00004 | 0,00015 | 0,00014 |
| AU | — | — | — | 0,00002 | — |
| Pauza | 0,00335 | 0,00077 | 0,01193 | 0,00842 | 0,00216 |
| Σ | 0,02298 | 0,00485 | 0,03235 | 0,01622 | 0,00697 |
|
| OU | AU | Pauza | Σ |
| A | — | — | 0,01786 | 0,05561 |
| Á | — | — | 0,00412 | 0,02000 |
| B | 0,00018 | — | 0,00005 | 0,01530 |
| C | 0,00002 | — | 0,00083 | 0,01149 |
| Č | — | — | 0,00030 | 0,00801 |
| D | 0,00047 | — | 0,00075 | 0,02284 |
| Ď | — | — | 0,00008 | 0,00400 |
| E | — | — | 0,02651 | 0,08163 |
| É | — | — | 0,00630 | 0,01039 |
| F | — | 0,00003 | 0,00232 | 0,00610 |
| G | — | — | 0,00042 | 0,00339 |
| H | 0,00037 | — | 0,00010 | 0,01062 |
| CH | 0,00005 | — | 0,00508 | 0,00997 |
| I | — | — | 0,02047 | 0,05014 |
| Í | — | — | 0,01453 | 0,03362 |
| J | 0,00002 | — | 0,00057 | 0,02412 |
| K | 0,00110 | — | 0,00529 | 0,03354 |
| L | 0,00076 | 0,00002 | 0,00368 | 0,03622 |
| M | 0,00025 | — | 0,00873 | 0,03093 |
| N | 0,00136 | 0,00005 | 0,00234 | 0,03800 |
| Ň | — | — | 0,00023 | 0,01665 |
| O | — | — | 0,01351 | 0,05754 |
| Ó | — | — | 0,00007 | 0,00055 |
| P | 0,00025 | — | 0,00031 | 0,02592 |
| R | 0,00039 | — | 0,00074 | 0,03015 |
| Ř | 0,00001 | — | 0,00024 | 0,01006 |
| S | 0,00086 | — | 0,00312 | 0,03920 |
| Š | 0,00001 | — | 0,00286 | 0,01028 |
| T | 0,00050 | — | 0,00587 | 0,03973 |
| Ť | 0,00001 | — | 0,00066 | 0,00713 |
| U | — | — | 0,00837 | 0,02298 |
| Ú | — | — | 0,00186 | 0,00485 |
| V | 0,00065 | — | 0,00198 | 0,03235 |
| Z | 0,00006 | — | 0,00110 | 0,01622 |
| Ž | — | — | 0,00046 | 0,00697 |
| OU | — | — | 0,00426 | 0,00732 |
| AU | — | — | — | 0,00021 |
| Pauza | — | 0,00011 | — | 0,16597 |
| Σ | 0,00732 | 0,00021 | 0,16597 | 1 |
[337]Tab. II. Relativní četnosti fonémů (bez symbolu pro hranici slova) u Mázlové, Kučery a Ludvíkové - Krause. Údaje Mázlové a Kučery značí průměrný výskyt symbolů na 1000. Všechny hodnoty × 100.
|
| Mázlová | Kučera | Ludvíková - Kraus |
| a á b c č d ď e é f g h ch i í j k l m n ň o ó p r ř s š t ť u ú v z ž ou au eu | 7,0 2,3 1,7 1,3 0,9 2,8 0,5 9,7 1,2 0,7 0,3 1,6 1,4 6,1 4,1 3,1 3,7 5,1 3,6 4,4 1,9 6,5 — 2,9 3,2 1,1 5,2 1,6 4,4 1,2 2,3 0,6 3,9 1,9 0,9 0,9 — — | 6,83 2,08 1,35 1,30 1,22 2,97 0,59 9,40 1,11 0,61 0,46 1,48 1,15 6,49 3,70 2,98 3,66 5,58 3,66 4,17 2,18 8,24 — 2,98 3,12 1,16 4,65 1,44 4,31 1,11 3,07 0,60 3,70 1,74 0,91 — — — | 6,66 2,40 1,83 1,35 0,96 2,74 0,48 9,79 1,25 0,73 0,40 1,27 1,20 6,00 4,00 2,89 4,02 4,35 3,71 4,56 1,99 6,91 0,05 3,11 3,66 1,19 4,71 1,24 4,76 0,87 2,76 0,59 3,89 1,94 0,85 0,87 0,02 — |
|
| 100,— | 100,— | 100,— |
kalických prvků a s tím související jejich vysoká prediktabilnost a nízká informační hodnota vyplývá z jejich funkce nositele slabiky. Schopnost tvořit slabiku přispívá nepochybně i k vysoké frekvenci fonémů sonantických. Další [338]skupinu podle četnosti — ve shodě s Jakobsonovým principem maximálního kontrastu — tvoří ražené konsonanty neznělé. Z hlediska místa artikulace je nejvíce využito pozice alveodentální. Neznělá dentála t je nejčetnější souhláskový foném vůbec, její znělý protějšek d stojí na prvním místě mezi znělými párovými fonémy. Výskyt s na jednom z předních míst vyplývá zvl. z vysoké četnosti předpon s- a z-. V téže frekvenční kategorii se objevuje i v a j. Postavení těchto fonémů v soustavě není zcela jednoznačné, protože k jejich konsonantickému charakteru přistupují některé vlastnosti sonantů. Foném v se řadí k párovým konsonantům, protože hlavně vlivem slov přejatých našel fonematický protějšek ve f, s nímž tvoří znělostní dvojici. Pokud jde o jeho distribuci, chová se v často jako sonant (např. vyskytuje se za znělými i neznělými konsonanty), a to je pravděpodobně rozhodující pro jeho poměrně vysokou četnost. U konsonantického fonému j nelze opět přehlédnout jeho těsný vztah k i; z tohoto důvodu je někteří autoři (např. Kučera) klasifikují jako polosamohlásku a řadí je k sonantám. Funguje-li vedle toho j jako vsuvný element v kombinaci „i + vokál“, můžeme odtud vysvětlit jeho hojnější výskyt.
Dolní polovina tabulky II obsahuje znělé párové fonémy, afrikáty a fonémy palatalizované a závěrem jsou uvedeny fonémy, které strukturně nejsou v systému plně integrovány.[7] Je to především foném g, jemuž přisuzujeme fonologickou platnost na základě té části českého lexika, která byla během vývoje přejata z jiných jazyků, když i jinak g je vhodným znělostním protějškem k. Foném ó má charakter obdobný.
Poučné jsou i rozdíly v relativních četnostech fonémů a grafémů, které jsou dány už repertoárem jednotek. Krátkému i, y a dlouhému í, ý v grafematické soustavě odpovídá jeden foném s příslušnou délkou; podobně navíc je v grafematické soustavě ů. Grafému ě odpovídá jednak spojení fonémů j + e (po retnicích), jednak ň + e (po m) nebo jen e, je-li předcházející d, t, n palatalizováno. Naopak inventář obsahuje navíc jednotky ou, au, eu. Posuny relativních četností souhláskových fonémů vyplývají především z asimilačních tendencí a z neutralizace znělosti před pauzou. I když je znělostní asimilace ve výslovnosti párových konsonantů procesem oboustranným, lze pozorovat, že ztráta znělosti je jevem častějším. Opačnou tendenci jsme nalezli pouze u páru retnic p - b, kde znělý korelát vzhledem ke grafémům vykazuje relativní přírůstek četnosti, neznělá úbytek. Tento zajímavý jev si ovšem žádá samostatného zpracování. Zvláštní případ představují fonémy f a g; značný vzrůst jejich četnosti ve srovnání s příslušnými grafémy je dán tím, že se staly znělostními protějšky fonémů v a k.
Srovnáme-li naše výsledky s Kučerovými, shledáme, že začátek a konec rozložení se shoduje — nejčetnější a nejméně četné fonémy mají stejné pořadí a jejich četnosti si vcelku odpovídají. Některé rozdíly vystupují u středně frekventovaných souhláskových fonémů, např. l a j; příčinu je nutno hledat v použitém materiálu. — Srovnání s výsledky Mázlové je poněkud méně snadné. U Mázlové jde o přepis fonetický, nikoli fonologický, přihlédneme-li však k vzájemným korespondencím, bude srovnání přece jen možné. Repertoár Mázlové obsahuje navíc dz, dž a neznělé ř. [339]Avšak ř stojí v pořadí podle klesajících četností téměř až na konci a průměrný výskyt dz a dž v 1000 hláskách je nulový. Podobně v našem repertoáru jsou navíc jednotky au, eu, jejichž relativní četnost je zanedbatelná. V zařazení ou je shoda, v obou statistikách vystupuje jako samostatná jednotka (na rozdíl od Kučery) s přibližně stejnou četností. Celkově ukazuje tabulka II poměrně dobrou shodu v četnostech zkoumaných jednotek u všech autorů.
Pokud jde o poměr vokalických a konsonantických prvků v textech, zjistili jsme v našem souboru 41,30 % vokalických fonémů a 58,70 % konsonantických, to je hodnota, která se téměř úplně shoduje s údaji Mázlové (40,7 a 59,3 %) a Kučery (41,52 a 58,48 %). Shodný výsledek různých statistik potvrzuje, že poměr vokalického a konsonantického elementu je v jazyce stabilní a že jej lze považovat za typologickou charakteristiku jazyka. Mázlová též studovala výskyt samohlásek podle druhu textu a proti svému očekávání zjistila, že básně jsou na samohlásky chudší než próza. Podobný rozdíl se jeví i v našich výběrech. Poměrně „nejvokaličtější“ jsou texty odborné (42 %), minimální počet samohláskových fonémů vykazuje poezie Hrubínova (39 %). Přechod tvoří umělecká próza a dramata. Rozložení fonémů podle typů udávají tabulky III a, b, c.
Tab. III. a) Rozložení fonémů podle typů:
| krátké vokály dlouhé vokály diftongy znělé konsonanty neznělé konsonanty sonanty (l, m, n, ň, r, ř, j) | 32,12 % 8,29 % 0,89 % 13,40 % 22,95 % 22,35 % |
b) Kvantitativní zastoupení souhláskových fonémů podle způsobu a místa artikulace
|
| labiály | alveodentály | palatály | veláry | celkem | ||||
| ražené | p, b | 4,94 % | t, d | 7,50 % | ť, ď | 1,35 % | k, g | 4,42 % | 18,21 % |
| třené | f, v | 4,62 % | s, z | 6,65 % | š, ž | 2,09 % | ch, h | 2,47 % | 15,83 % |
| afrikáty |
|
| c | 1,35 % | č | 0,96 % |
|
| 2,31 % |
| nosové | m | 3,71 % | n | 4,56 % | ň | 1,99 % |
|
| 10,26 % |
| laterály |
|
| l | 4,35 % | j | 2,89 % |
|
| 7,24 % |
| jazyčné |
|
| r, ř | 4,85 % |
|
|
|
| 4,85 % |
| Celkem | 13,27 % | 29,26 % | 9,28 % | 6,89 % | 58,70 % | ||||
Na zjištěné relativní četnosti fonémů navazuje statistika dvojčlenných fonémových skupin (tab. IV[*]). Z abecedy symbolů o 39 prvcích (počet fonologických jednotek naší statistiky) lze vytvořit 392, tj. 1521 digramů. Z tohoto počtu teoreticky možných kombinací se v jazyce realizuje pouze část — podle našich údajů 896 digramů, tj. 58,91 % celkového počtu. Tato hodnota, udávající poměr počtu realizovaných skupin k počtu skupin teoreticky možných, se na-
[340]c) Četnosti neznělých a znělých párových fonémů (× 100)
|
| neznělé | znělé | ||
|
| t s k p š ch ť f | 4,76 4,71 4,02 3,11 1,24 1,20 0,87 0,73 | d z g p ž h ď v | 2,74 1,94 0,40 1,83 0,85 1,27 0,48 3,89 |
| Celkem |
| 20,64 |
| 13,40 |
zývá variační poměr a pro českou grafematickou soustavu dosahuje 58,27 % (z celkového počtu 422 = 1764 se realizuje 1028 dvojic).[8] Ukazuje se tedy, že ve fonologické soustavě se prvky mezi sebou poněkud snáze kombinují a jsou tak o něco ekonomičtěji využity než v soustavě grafematické.
Kombinační schopnosti jednotlivých fonémů ukazuje tab. V. Číslo před symbolem udává počet různých fonémů, které mohou daný foném předcházet, číslo za ním pak udává, kolik fonémů může následovat. Nazveme-li kombinační schopnost fonému valencí (srov. o. c. v pozn. 8), pak přední valenční pole dosahuje nejvyšších hodnot u slovní hranice (36), sonantu l (33), n (32), ň (32) a samohlásek a (31), o (31); zadní valenční pole u slovní hranice (36), samohlásek e (35), o (33) a sonantů j (35), r (34) a l (33). Největší rozdíly v kombinačních schopnostech v předním a v zadním poli mají palatály ď (17 — 7), ť (24 — 11) a ň (32 — 12).
Tab. V. Přední a zadní valenční pole fonémů
| 31 a 31 | 11 g 17 | 32 ň 12 | 29 u 28 |
| 28 á 25 | 18 h 18 | 31 o 33 | 22 ú 23 |
| 22 b 22 | 18 ch 26 | 13 ó 9 | 28 v 25 |
| 25 c 18 | 29 i 29 | 21 p 27 | 21 z 25 |
| 23 č 17 | 26 í 26 | 29 r 34 | 21 ž 18 |
| 20 d 25 | 18 j 35 | 22 ř 20 | 36 — 36 |
| 17 ď 7 | 28 k 24 | 25 s 29 | 19 ou 22 |
| 29 e 35 | 33 l 33 | 22 š 21 | 4 au 5 |
| 18 é 23 | 28 m 29 | 27 t 28 |
|
| 16 f 19 | 32 n 31 | 24 ť 11 |
|
Digramy obsahující symbol pro slovní hranici dovolují zjistit pořadí nejčetnějších fonémů na začátku a na konci slova — viz tab. VI a, b. Pořadí nejčetnějších fonémových dvojic je uvedeno v tab. VI c.
[341]Tab. VI. a) Pořadí nejčetnějších fonémů na začátku slova (digram: hranice slova + foném) a na konci slova (digram: foném + hranice slova)
| na začátku slova |
| na konci slova | ||||
| 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. | — s — p — n — v — j — t — z — m — a — k | 0,01939 0,01633 0,01238 0,01193 0,00973 0,00919 0,00842 0,00831 0,00814 0,00734 |
| 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. | e — i — a — í — o — m — u — é — t — k — | 0,02651 0,02047 0,01785 0,01453 0,01351 0,00873 0,00829 0,00630 0,00587 0,00529 |
b) Pořadí nejčetnějších fonémových dvojic
| 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14. 15. 16. 17. 18. 19. 20. | je st ne na po se ňí ro ňe en le em la ov li to ko te el pr | 0,01147 0,00851 0,00777 0,00774 0,00701 0,00683 0,00670 0,00655 0,00624 0,00618 0,00590 0,00575 0,00574 0,00571 0,00564 0,00549 0,00509 0,00506 0,00505 0,00501 |
Na základě uvedených výsledků je možno vypočítat informačněteoretické charakteristiky textů — entropii a redundanci (viz tab. VII). (Vzorec pro výpočet entropie — H — a redundance — R — je uveden v cit. práci Doleželově.)
Spolu s těmito charakteristikami fonologické soustavy lze pomocí nalezených údajů vypočítat i vztah hodnot entropie v mluveném a psaném jazyce pomocí koeficientu ω, který označuje průměrný počet písmen připadající na jeden foném podle vztahu[9]
[342]
![]()
Pro H1 v našem souboru platí
![]()
4,60915 = 4,6665 . ω
ω = 0,988
VII. Tabulka entropie a redundance
|
| Rudé právo | Večerní Praha | Učebnice histologie | Vaříme zdravě | Hrubín U stolu | Fried |
| H0 | —— | —— | —— | —— | 5,28 | —— |
| H1 | 4,6382 | 4,6351 | 4,6823 | 4,5980 | 4,5701 | 4,5618 |
| H2 | 3,5940 | 3,6570 | 3,6429 | 3,5189 | 3,5824 | 3,5487 |
| H3 | 2,7482 | — | — | 2,4893 | — | 2,3505 |
| R1 | 12,16 % | 12,22 % | 11,32 % | 12,92 % | 13,45 % | 13,60 % |
| R2 | 32,03 % | 30,73 % | 31,01 % | 33,36 % | 32,15 % | 32,79 % |
| R3 | 48,96 % | — | — | 52,86 % | — | 55,50 % |
|
| Florian | Hrubín Romance | Hrubín Křišť. noc | Topol | Soubor celkem |
| H0 | —— | —— | —— | —— | —— |
| H1 | 4,5984 | 4,5684 | 4,5006 | 4,5112 | 4,60915 |
| H2 | 3,6192 | 3,5825 | 3,4460 | 3,4416 | 3,58284 |
| H3 | 2,8148 | 2,7285 | 2,3611 | — | — |
| R1 | 12,91 % | 13,48 % | 14,76 % | 14,57 % | 12,71 % |
| R2 | 31,46 % | 32,15 % | 34,74 % | 34,81 % | 32,15 % |
| R3 | 46,59 % | 48,34 % | 55,29 % | — | — |
Pozn.: Hodnoty H3 a R3 byly zjištěny jen pro některé výběry.
[343]Střední informace fonému se rovná 0,988 informace písmene pro H1.
Pro H2 platí
![]()
3,5824 = 3,8710 . ω
ω = 0,922.
Střední informace fonému se rovná 0,922 informace písmene pro H2.
Vztah hodnot entropie pro fonologickou a grafematickou soustavu můžeme znázornit také graficky.
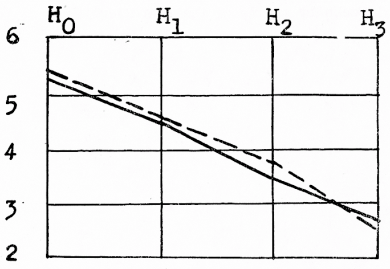
![]() graf.
graf.
![]() fon.
fon.
Pozn.: Údaje pro H3 jsou uvedeny pouze podle jednoho výběru.
Závěrem této studie bychom chtěli konstatovat, že předložené výsledky mají pomoci hlubšímu poznání kvantitativních vlastností české fonologické soustavy a tím i vytvoření předpokladů pro ucelenější výklad fonologických rysů strukturních. Vedle využití teoretického nechceme opomíjet ani možné závěry praktické, platné především pro ekonomický přenos sdělení, které se opírá o poznání informačněteoretických charakteristik — entropie a redundance mluvené češtiny.
R É S U M É
Quantitative properties of the system of Czech phonemes
The statistics of the Czech phonemes and phoneme digrams was made on the material of 10 samples from various literary texts representing the following styles: scientific and directive style, newspapers, artistic prose, poetry, theater play. The phonological transcription of the texts contains 186.641 units (including pause) belonging to 30.976 words and 2500 sentences.
The relative frequencies of phonemes (Table I) give a quantitative representation of the general structural properties and relations in the system. The ratio of the vocalic and consonantal element which appears to be stable in the language is 41,30 p.c. : 58,70 p.c. The data on the tables regard further the distribution of phonemes according to the manner and place of articulation, frequencies of the voiceless and [344]voiced paired phonemes, the most frequent phonemes in the initial and final positions of words etc. Out of the 1521 theoretically possible two-member combinations 896 digrams (58,91 p.c.) were realized (Table IV). The value compared with that for graphemes (58,27 p.c.) indicates that the units of the phonemic system are somewhat more easily combined and more economically utilized than those of the written language. The combinability of individual phonemes can be seen in Table V giving for each phoneme the number of units by which it may be preceded and followed. — The relative frequencies served as basis for the estimation of entropy and redundancy of the Czech phonological system: H0 = 5,28, H1 = 4,61, H2 = 3,58; R1 = 12,71 p.c., R2 = 32,15 p.c. As the material was practically the same as that of the statistics of graphemes it was possible to determine the relation between the phonemic and graphemic system of Czech by means of the coefficient ω.
[1] Jsme si ovšem vědomi, že na tuto otázku existují různé názory, např. F. Trávníček, Významotvorný úkon hlásek v češtině, Recueil linguistique de Bratislava, Bratislava 1948.
[2] Opačný názor zastává V. I. Perebejnos, Častota i sočetajemosť fonem sovremennogo ukrainskogo jazyka. Seminar: Avtomatizacija inform. rabot i voprosy prikl. lingvistiki. Kyjev 1965.
[3] Část výpočtů (především nalezení hodnot H2 a H3) byla zpracována na samočinných počítačích. Za všestrannou pomoc, zvláště při číselném zpracování údajů, děkujeme především prom. mat. P. Vašákovi z ÚJČ.
[4] V. Mathesius, La structure phonologique du lexique du tchèque moderne, TCLP I, 1929, 67—84. — B. Trnka, Pokus o vědeckou metodu a praktickou reformu těsnopisu, Praha 1935. — J. Vachek, Poznámky k fonologii českého lexika, LF 67, 1940, 395—402. — J. Krámský, Fonologické využití samohláskových fonémat, Linguistica slovaca 4—6, 1946—48, 39—43.
[5] V. Mázlová, Jak se projevuje zvuková stránka češtiny v hláskových statistikách, NŘ 30, 1946, 101—111 a 146—151.
[6] H. Kučera, Mechanical phonemic transcription and phoneme count of Czech, International Journal of Slavic Linguistics and Poetics 6, 1963, 36—50.
[7] Srov. J. Vachek, On the Integration of the Peripheral Elements into the System of Language, Travaux linguistiques de Prague II, 1966, s. 23-38. — Prof. J. Vachkovi děkujeme zároveň za zvláště cenné připomínky a pomoc poskytovanou v průběhu této práce.
[*] Tab. IV z technických důvodu je za str. 344.
[8] L. Doležel - J. Průcha, Kombinatorické vlastnosti soustavy českých grafémů, SaS 25, 1964, 166—174.
[9] Srov. A. M. Jaglom - I. M. Jaglom, Pravděpodobnost a informace, Praha 1964; odpovídající údaje týkající se grafematické soustavy uvádíme podle citované práce Doleželovy.
Slovo a slovesnost, ročník 27 (1966), číslo 4, s. 334-344
Předchozí Bohuslav Havránek: Ještě k poměru Máchova jazyka a obrozenské češtiny
Následující Roman Mrázek: První dva svazky obnovených pražských lingvistických Travaux
© 2011 – HTML 4.01 – CSS 2.1