
Dva vzťahy z kvantitatívnej lingvistiky
Ema Danielová
[Rozhledy]
Два отношения из области количественной лингвистики / Deux rapports dans la linguistique quantitative
Pri hľadaní matematickej formy vzťahu, ktorý viaže rôzne veličiny, možno aj v kvantitatívnej lingvistike s výhodou používať rôzne funkčné papiere. V tomto článku ukážeme napr. použitie semilogaritmického a logaritmického papiera pri hľadaní dvoch vzťahov (na obr. 1 a 2 sú však tieto papiere naznačené iba príslušnými funkčnými stupnicami na osiach X a Y).
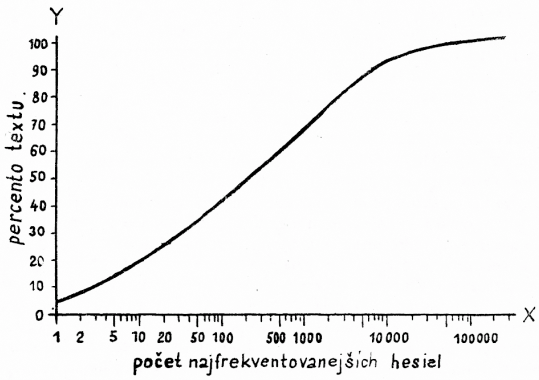
Prvý hľadaný vzťah je vzťah medzi počtom nejfrekventovanejších hesiel a percentom textu tvoreným týmito heslami. Nevychádzali sme pritom z konkrétnych textov, ale výpočty sme robili podľa údajov uvedených v diele Jelínek - Bečka - Těšitelová: Frekvence slov, slovních druhů a tvarů v čes. jazyce, Praha 1961 (v ďalšom texte ho budeme označovať skratkou FS).
[362]K zvolenému počtu najfrekventovanejších hesiel (x) bol vypočítaný podľa FS súčet frekvencií všetkých týchto hesiel (nx) a z tohto percento texu (px) podľa vzorca px = 100 . nx : N, kde N je dĺžka textu, t. j. v našom prípade súčet frekvencií všetkých hesiel vo FS (N = 1 623 527). Tak napr. pre prvých dvadsať najfrekventovanejších hesiel dostali sme podľa FS n20 = 398 529 a z tohto p20 = 100 . n20 : N = 100 . 398 529 : 1 623 527 = 24,5 %. Takto bolo vypočítané percento textu pre rôzne x. Nato sme vy-

niesli odpovedajúce si dvojice x a px na semilogaritmický papier, na ktorom bol na osi X vynesený desiatkový logaritmus počtu najfrekventovanejších hesiel (X = log x) a na osi Y percento textu (Y = px); získaná krivka (pozri obr. 1) sa ponáša na časť krivky pravdepodobnosti. Ukazuje sa však, že v intervale p = 25 % až p = 90 % možno tento úsek krivky nahradiť priamkou, ktorej rovnica je Y = 25 X — 8,6, čo po použití vzťahov zobrazených na osiach X a Y dáva
px = 25 . log x — 8,6 (1)
V tab. 1 uvádzame pre niekoľko x príslušné percento textu px určené podľa FS a vypočítané zo vzťahu (1). Vidíme, že v intervale p = 25 % až p = 90 % sú odchýľky pomerne malé, preto v tomto intervale možno vzťahom (1) nahradiť exaktný vzťah medzi x a px. Vzťah (1) sa vyčísľuje pomerne veľmi pohodlne a môže poslúžiť napr. pri výpočte počtu hesiel pre slovníky, prekladacie stroje a pod.
Pri hľadaní druhého vzťahu medzi veľkosťou frekvencie (f) a počtom hesiel (x), ktoré túto frekvenciu majú, sme taktiež vychádzali z údajov uvedených vo FS. Po vynesení odpovedajúcich si dvojíc f a x na logaritmický papier (na ktorého osiach sú vynesené stupnice X = log f, Y = log x) sme zistili, že body sú rozložené približne okolo priamky Y = Y1 — 1,4 X (pozri obr. 2, na ktorom je vynesených iba niekoľko
[363]Tabuľka 1
| Počet najfrekv. hesiel (x) | Percento textu (px) | |
| podľa FS | zo vzťahu (1) | |
| 20 30 40 50 60 70 80 90 100 200 300 400 500 600 700 800 900 1 000 2 000 3 000 4 000 5 000 6 000 7 000 8 000 9 000 10 000 | 24,5 % 28,7 % 31,7 % 33,9 % 35,7 % 37,3 % 38,8 % 40,0 % 41,1 % 48,2 % 52,4 % 55,3 % 58,0 % 60,0 % 61,9 % 63,5 % 64,9 % 66,1 % 74,5 % 79,3 % 82,4 % 84,8 % 86,6 % 88,1 % 89,3 % 90,4 % 91,3 % | 23,9 % 28,3 % 31,5 % 33,9 % 35,9 % 37,5 % 39,0 % 40,3 % 41,4 % 48,9 % 53,3 % 56,5 % 58,9 % 60,9 % 62,5 % 64,0 % 65,3 % 66,4 % 73,9 % 78,3 % 81,5 % 83,9 % 85,9 % 87,5 % 89,0 % 90,3 % 91,4 % |
Tabuľka 2
| Frekvencia (f) | Počet hesiel (x) | ||
| zo vzťahu (2) | zo vzťahu (3) | podľa FS | |
| 1 2 20 50 70 300 400 | 20 467 7 756 309 86 53 7 5 | 20 467 7 753 305 82 49 3 1 | 20 467 7 762 310 61 35 2 1 |
bodov). Po dosadení vzťahov, ktoré sú vynesené na osiach logaritmického papiera, do rovnice priamky, dostávame log x = log x1 — 1,4 . log f, alebo po úprave
[364]x = x1 . f—1,4 (2)
kde f znamená frekvenciu, x počet hesiel, ktoré majú túto frekvenciu, x1 počet hesiel majúcich frekvenciu f = 1 (podľa FS je x1 = 20 467). Ako vidieť, neide v prípade vzťahu (2) o exponenciálnu funkciu, ako sa často v literatúre uvádza, ale o funkciu mocninnú (resp. v prípade vzťahu 3 o funkciu algebraickú). Keďže hlavne pri vyššom x vychádzajú podľa vzťahu (2) hodnoty väčšie než udáva FS, bol vzťah (2) zmenený ešte na tvar
x = (x1 + 4) . f—1,4 — 4 (3)
V tab. 2 uvádzame pre niekoľko hodnôt f výsledky získané zo vzťahov (2) a (3) a hodnoty udané vo FS.
Slovo a slovesnost, ročník 27 (1966), číslo 4, s. 361-364
Předchozí Roman Mrázek: První dva svazky obnovených pražských lingvistických Travaux
Následující Pavel Vašák: Statistika a sporné autorství
© 2011 – HTML 4.01 – CSS 2.1