
Významný příspěvek k srovnávací kvantitativní fonologii
Marie Ludvíková
[Kronika]
Важная работа по сопоставительной количественной фонологии / Une contribution importante à la phonologie comparée quantitative
V monografii H. Kučery a G. K. Monroea A Comparative Quantitative Phonology of Russian, Czech and German (New York 1968, 113 s.) studují autoři statistickými metodami oblast fonologie a jazykové typologie. Výsledky fonologické analýzy vyhodnocené kvantitativně mají sloužit k zjištění rozdílů mezi jazyky na fonologické rovině a k posouzení jejich genetické příbuznosti. Náročnost na materiál při takovém pokusu je zřejmá; v tomto případě šlo o tři paralelní statistické soubory z různých jazyků. Autoři si vytkli úkol opravdu obsáhlý, který ovšem nebyl řešen najednou. Některé dílčí problémy byly zpracovány a publikovány H. Kučerou knižně i v časopisech již v minulých letech, např. fonologická analýza češtiny, mechanický fonologický přepis textu, statistické určení izotopie aj.[1] Kučera vy[211]pracoval metodu výzkumu a podrobil analýze oba slovanské jazyky; Monroe provedl analýzu němčiny a pomáhal při automatickém zpracovávání materiálu. Oba autoři se podíleli na přípravě programu.[2]
Práce byla podnícena na jedné straně zájmem o fonologickou typologii, na druhé straně možností vyzkoušet v širokém měřítku použitelnost kvantitativních metod v srovnávací lingvistice. Pozornost autorů se soustředila na otázku, do jaké míry podobnost fonémových vzorců jazykových jednotek, především slabik, v různých jazycích obráží stupeň jejich genetické příbuznosti a zda je tato příbuznost měřitelná. Jako objekty srovnání byly zvoleny dva jazyky příbuzné, čeština a ruština, a němčina jako jazyk z jiné genetické skupiny. Po stránce matematické bylo k řešení daného problému užito některých pojmů z oblasti teorie informace a dále byl zkonstruován tzv. index izotopie, který kvantitativně vyjadřuje stupeň příbuznosti jazyků. Srovnávací studii tohoto druhu si lze těžko představit bez pomoci samočinných počítačů a také v této práci jich bylo s výhodou užito při analýze, třídění a řazení materiálu.
Podkladem analýzy jsou literární texty reprezentativních autorů 20. stol. z oblasti románové prózy, žurnalistiky, odborné literatury a poezie. Výběry byly pořízeny po 100.000 fonémech pro každý zkoumaný jazyk. Fonologický přepis textu byl svěřen počítači. V češtině a ruštině byla transkripce plně automatická; protože v němčině jsou korespondence mezi grafickou a fonologickou reprezentací jazyka mnohem složitější, byl pro ni zvolen postup poloautomatický, sestávající z řady dílčích podprogramů. Tento přepis pak sloužil jako vstup pro další programy strukturní a statistické analýzy na rovině fonémů a slabik.
Inventář fonémů byl stanoven na základě Jakobsonovy teorie distinktivních rysů. Fonémový inventář spisovné češtiny obsahuje 35 jednotek, pro ruštinu byl vzat za základ spisovné výslovnosti Avanesovův tzv. nový spisovný standard, podle něhož má ruština repertoár 41 fonémů. Podkladem fonologické analýzy němčiny byla zvolena tzv. Hochsprache, standardní mluvená forma srozumitelná po celém německém území; její fonologický inventář je nejmenší ze všech tří jazyků: 10 distinktivních rysů odlišuje 33 fonémů. (Diftongy a afrikáty jsou považovány za řetěz dvou fonémů.) Při popisu fonologického systému jazyků pomocí distinktivních rysů byli autoři poněkud omezováni zřetelem k porovnávacímu zaměření práce. Matici distinktivních rysů by bylo možno pro jednotlivé jazyky sestavit i jinak, uvedený způsob se však jevil autorům jako nejvýhodnější.
Statistická analýza udává v tabulkách četnosti fonémů v češtině, ruštině a němčině a srovnávací indexy akustických a artikulačních vlastností fonémů (např. poměr znělých a neznělých konsonant, znělých a neznělých explozív a frikativ atd.). Z hodnot dvojí směrodatné odchylky — mezi češtinou a ruštinou a mezi slovanskými jazyky a němčinou — lze usuzovat na zřetelnou korelaci mezi kvantitativními fonologickými vlastnostmi jazyků a jejich genetickým příbuzenstvím.
Hlavním předmětem zkoumání recenzované práce je vyšší jednotka fonologické roviny — fonologická slabika. Pro identifikaci slabiky bylo použito Hockettovy analýzy na bezprostřední složky,[3] jíž se řetěz jazykových jednotek segmentuje na řadu hierarchicky uspořádaných konfigurací. Metoda byla doplněna Haugenem[4] o segmentaci fonémových řetězů uvnitř slova mezi dvěma slabičnými jádry (interludes) a autoři k ní připojili další strukturní a statistická kritéria pro jednoznačné vymezení slabičné hranice. Kritéria vycházejí z fonologické struktury počátků první slabiky (onset) [212]a konců poslední slabiky (coda) v polysylabických slovech daného materiálu; tyto struktury byly předem tabelovány i s příslušnými četnostmi a představují repertoár přípustných struktur pro dělení konsonantických řetězů mezi dvěma jádry. Podle nich se tento řetěz dělí tak, aby jeho segmentací nevznikaly nové struktury slabičných počátků a konců a nerozšiřovaly již stanovený repertoár. Je-li více takových možností, přijímá se řešení buď nejfrekventovanější, anebo vytvářející nejkratší konsonantické řetězy, což je prakticky totéž, protože z hlediska ekonomie jazykového kódování se kratší strukturní jednotky obecně vyskytují s vyšší četností než jednotky delší. Výsledkem analýzy jsou pak seznamy strukturních typů slabiky a obecné schéma slabičné struktury pro tři zkoumané jazyky. Všechny typy slabik předpokládané schématem se ovšem nemusí vyskytnout; jde pouze o teoretické zobrazení strukturních možností v rámci slabiky. Porovnáním tohoto vzorce s realizovanými strukturami zjišťují autoři další charakteristické rozdíly mezi jazyky (např. slovanské jazyky mají tendenci k rovnovážné struktuře slabiky, kdy jádro předchází a následuje přibližně stejný počet konsonantů, němčina však tuto tendenci nemá). Strukturní vzorce doprovázejí statistické údaje o frekvenčním rozložení typů monosylab, o frekvenci jednotlivých typů slabičných počátků a konců a četnosti fonémů ve všech slabičných pozicích.
Kvantitativních údajů je využito v teoretickoinformační analýze slabiky; se slabikou se tu pracuje jako s nezávislou sdělovací jednotkou. Zajímavá je úvaha o efektivnosti slabičného systému. Výsledky svědčí o tom, že slabika je v zásadě efektivní útvar — relativní četnost slabik klesá v obráceném poměru k jejich délce ve všech jazycích. Zároveň však frekvenční data ukazují, že rozložení slabičné délky není v žádném případě optimální, delší slabiky mají někdy vyšší četnost, zatímco některé krátké slabiky se vyskytují méně často. Příčinou toho jsou zákonitosti fonologické stavby slabiky, které omezují kombinační možnosti fonémů a tím působí proti ekonomii jazyka. Bez těchto omezení by každý jazyk vystačil se slabikami o jednom, dvou a třech fonémech. Nepřítomnost omezení v slabice je ovšem nereálná, protože už sama její existence je podmíněna nutností vokalického jádra. V tomto oddíle jsou rovněž vyloženy známé základní pojmy teorie informace a jejich aplikace v jazyce, jsou uvedeny různé způsoby výpočtu entropie a redundance. Autoři zastávají názor, že usilovat o odhad entropie jazyka je z hlediska lingvistiky i teorie informace pochybné; není totiž nikterak prokázáno, že jazyk je systém s konečným počtem stavů, a lze pochybovat o tom, zda je možné statisticky postihnout všechna omezení v hierarchicky uspořádaných jazykových rovinách. Tato charakteristika je spíše vhodná jako nástroj k měření některých kvantitativních vlastností uzavřených lingvistických celků (roviny fonémů, slabik, slov atd.). V této souvislosti připomeňme analogický názor projevený na první československé konferenci o kybernetice,[5] kde J. Nedoma položil otázku, zda má smysl mluvit o entropii jazyka nebo jen o entropii textu.
Autoři soudí, že entropií nelze postihnout ani příbuznost jazyků. Je totiž možno si představit dva vzdálené jazyky s různým inventářem jednotek a touž entropií např. fonémů nebo slabik. Při studiu příbuznosti je nutno přihlížet i k fonetickým vlastnostem jazyků a k stupni jejich fonologické podobnosti. Podobností fonologických vzorců se rozumí nejen rozložení pravděpodobností fonémů, ale i skutečná fonologická podobnost segmentů. Tyto vlastnosti vyjádřili autoři matematickým vztahem, tzv. indexem izotopie, který udává míru, s níž se fonologicky podobné řetězy (např. slabiky) vyskytují s podobnou četností ve dvou jazycích; tato podobnost je v korelaci se stupněm genetické příbuznosti jazyků na fonologické rovině. Izotopií se rozumí identické nebo podobné rozložení fonémů v týchž distri[213]bučních pozicích. Izotopie je tím větší, čím pravděpodobnější je výskyt daných fonémů v těchto pozicích — udává tedy podobnost distribuční a kvantitativní. Kvalitativní podobnost řetězů vyjadřuje pojem izomorfie, což je podobnost mezi fonémy dvou jazyků, měřená počtem společných distinktivních rysů. Matematicky je izomorfie vyjádřena vzorcem
![]()
kde d je počet rysů, v nichž se skupiny fonémů od sebe odlišují, f je maximální počet rysů nutný k určení fonému v jednom z jazyků. Index izotopie, daný vztahem
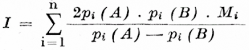
zahrnuje v sobě oba tyto aspekty, kvalitativní i kvantitativní. Obsahuje pak tyto faktory: (1) míru izomorfie, (2) rozdíl mezi pravděpodobností fonému v jazyce A a v jazyce B v dané pozici, (3) průměrnou pravděpodobnost, s níž se fonémy tzv. izomorfické množiny vyskytují v dané pozici. Index byl spočítán pro dvojice ruština — čeština, ruština — němčina a čeština — němčina a koreluje dobře se stupněm jejich příbuznosti:
I r/č — 0,759
I r/n — 0,474
I č/n — 0,616
(hodnota 1 značí identičnost, 0 úplnou odlišnost).
Svými výklady a výpočty autoři Kučera a Monroe ukazují, že některé matematické postupy z oblasti komunikačních systémů jsou v lingvistické analýze užitečné za předpokladu, že se jimi zkoumají specifické a přesně definované jevy přirozeného jazyka. Pojmy a postupy teorie informace jsou vhodné pro studium struktury jazykových prvků nižších rovin (slabik, morfémů), kde přinášejí nové poznatky o fonotaktice jazyka; těch pak lze dále použít při posuzování komplexních mezijazykových vztahů.
Předností knihy je důkladný výklad problematiky a explicitní popis pravidel a postupů analýzy; z toho je patrno, že autoři „psali pro počítač“. Nezůstávají však v oblasti čísel, ale vždy usilují o zasvěcenou lingvistickou interpretaci výsledků. Snaží se vypořádat i se zastánci jiných jazykových teorií (Chomsky) i se svými kritiky (Herdan). Snad bychom si jen přáli hlubší vhled do jazykového materiálu, pokud jde o jeho charakter i o těsnější sepětí strukturních vzorců s konkrétními jazykovými jednotkami. Kniha jistě najde čtenáře v řadě oborů — v slavistice i germanistice, ve fonetice, srovnávací jazykovědě a především v matematické lingvistice.
[1] The Phonology of Czech, The Hague 1961; srov. recenzi v SaS 25, 1964, 291 až 295. Mechanical Phonemic Transcription and Phoneme Frequency Count of Czech, International Journal of Slavic Linguistics and Poetics 6, 1963, 36—50; Statistical Determination of Isotopy, Proceedings of the Ninth International Congress of Linguists, The Hague 1964, s. 713—721; srov. též SaS 24, 1963, 67—76.
[2] Výzkum byl prováděn ve výpočtovém středisku Brownovy university v Rhode Islandu na počítačích IBM.
[3] Ch. F. Hockett, A Manual of Phology, Baltimore 1955.
[4] E. Haugen, The Syllable in Linguistic Description, sb. For Roman Jakobson, The Hague 1956, s. 213—221.
[5] Srov. Československá konference o kybernetice, SaS 24, 1963, 158—160.
Slovo a slovesnost, ročník 30 (1969), číslo 2, s. 210-213
Předchozí Ludmila Uhlířová: Místo pořádku slov v generativní gramatice
Následující Josef Štěpán: Studium vývojového pohybu současné němčiny (s využitím počítačů)
© 2011 – HTML 4.01 – CSS 2.1