
O vztahu mezi délkou slova a jeho polohou ve větě
Ludmila Uhlířová
[Články]
On a relationship between word length and word placement in the clause
1. Otázka, jak dlouhá jsou slova či slovní tvary, z nichž se skládají věty, stejně jako otázka, jak dlouhé jsou věty, z nichž mluvčí tvoří text, patří k tradičním otázkám kvantitativní lingvistiky. Úloha zjistit, jak jsou nějaké lingvistické jednotky dlouhé, at už je konkrétní zadání takové úlohy (např. rozsah analyzovaného textu, konkrétní jazyk, účel šetření apod.) jakékoli, je zpravidla formulována tak, že náhodnou veličinou je délka lingvisticky definovaného lineárního řetězce (slabiky, slova, věty,…) při dané měrné jednotce (např. délka slova v grafémech, slabikách,…) a pozorovaným jevem neboli vstupními daty jsou četnosti délek měřeného řetězce v textu, korpusu textů apod. Je-li analyzovaný jazykový materiál statisticky reprezentativní a podmínky měření dostatečně zřetelně formulovány (např. je-li definováno, co se považuje za slovo, jsou-li delimitovány větné hranice apod.), zpravidla se podaří vhodným matematickým postupem dospět k rozumnému výsledku, například nalézt typ pravděpodobnostního rozdělení, kterým může být empirické rozdělení četností vhodně modelováno. Není přitom vyloučeno, že v některých případech se podaří nalézt více než právě jeden vyhovující typ modelu.
Lze například ukázat, že rozdělení slovní délky měřené počtem slabik se v češtině řídí určitým druhem binomického rozdělení, a to tzv. rozšířeným pozitivním binomickým rozdělením, jehož vzorec má tvar
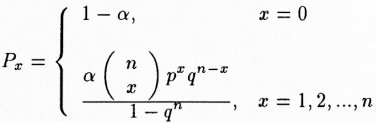
kde x značí délku slova. Toto rozdělení platí pro texty různých stylů a žánrů, napsané různými autory, pro texty o různém rozsahu i pro soubory textů; specifické shody a rozdíly mezi texty (autory, žánry, styly…) lze pak popsat pomocí shod a rozdílů v parametrech tohoto rozdělení (viz Uhlířová, 1994, 1995, 1996, v tisku). Lze rovněž ukázat, že vlastnost řídit se tímto rozdělením sdílí čeština s řadou dalších, typologicky příbuzných i vzdálených jazyků, jinými slovy že jev rozdělení slovních délek vykazuje značně obecný typ statistické zákonitosti (Altmann – Erat – Hřebíček, 1996; Altmann – Best, 1996; Wimmer – Altmann, 1996; Wimmer – Köhler et al., 1994).
Histogramy empirických a teoretických hodnot pro slovní délky v počtu slabik, které byly zjištěny na materiále soudobých českých povídek pro mládež o rozsahu přes deset tisíc slov (Miloš Macourek, Žofka ředitelkou zoo, Praha 1991), uvádějí obr. 1 a tab. 1 včetně hodnot χ2 testu.
|
| [175]x |
| fx |
| NPx |
|
| |
|
|
| 0 |
| 18 |
| 18.00 |
|
|
|
|
| 1 |
| 371 |
| 369.56 |
|
|
|
|
| 2 |
| 392 |
| 391.74 |
|
|
|
|
| 3 |
| 218 |
| 221.47 |
|
|
|
|
| 4 |
| 71 |
| 70.43 |
|
|
|
|
| 5 |
| 13 |
| 11.94 |
|
|
|
|
| 6 |
| 1 |
| 0.86 |
|
|
x = délka slova v počtu slabik[1]
fx = empirické četnosti slov o dané délce
NPx = teoretické četnosti: aproximace rozšířeným pozitivním binomickým rozložením s parametry a = 6,000 a b = 0,298.
P(χ2) = 0,9142
χ2 = 0,1794
Tab. 1. Rozdělení slovních délek v textu povídky M. Macourka Jak Žofka odhalila zloděje z povídkové knížky Žofka ředitelkou zoo.
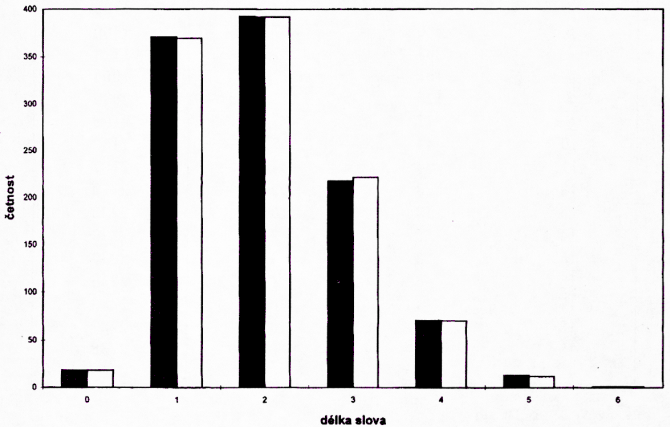
■ – empirické četnosti slovních délek, □ – teoretické četnosti slovních délek
Obr. 1. Histogram rozdělení slovních délek (podle dat v tab. 1).
[176]Podobně lze například ukázat, že rozdělení větných délek měřené počtem slov (přesněji slovních tvarů ve větě užitých) se v češtině řídí jedním z typů Poissonova rozdělení, a to tzv. smíšeným Poissonovým rozdělením, že tedy jeho tvar lze matematicky popsat jako
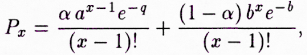
kde x = 1, 2, … a kde a, b > 0 a 0 < α < 1. Hodnoty jsou uvedeny v tab. 2 a v obr. 2.
Tímto způsobem lze popisovat frekvenční chování různých lingvistických proměnných (= náhodných veličin) v textu. Protože zpravidla jde o úlohy jasně vymezitelné, patří v kvantitativní lingvistice k úlohám základním. Odkazy na lineární rozměr lingvistických proměnných nechybějí například téměř v žádné kvantitativní
|
| x |
| fx |
| NPx |
|
| f'x |
|
|
| 1 |
| 65 |
| 67.89 |
|
| 65 |
|
|
| 2 |
| 238 |
| 225.56 |
|
| 303 |
|
|
| 3 |
| 375 |
| 376.72 |
|
| 678 |
|
|
| 4 |
| 422 |
| 424.40 |
|
| 1100 |
|
|
| 5 |
| 360 |
| 367.62 |
|
| 1460 |
|
|
| 6 |
| 263 |
| 267.78 |
|
| 1723 |
|
|
| 7 |
| 181 |
| 177.79 |
|
| 1904 |
|
|
| 8 |
| 128 |
| 115.74 |
|
| 2032 |
|
|
| 9 |
| 77 |
| 77.04 |
|
| 2109 |
|
|
| 10 |
| 44 |
| 52.19 |
|
| 2153 |
|
|
| 11 |
| 34 |
| 34.83 |
|
| 2187 |
|
|
| 12 |
| 23 |
| 22.23 |
|
| 2210 |
|
|
| 13 |
| 13 |
| 13.34 |
|
| 2223 |
|
|
| 14 |
| 6 |
| 7.47 |
|
| 2229 |
|
|
| 15 |
| 3 |
| 3.91 |
|
| 2232 |
|
|
| 16 |
| 3 |
| 1.91 |
|
| 2235 |
|
|
| 17 |
| 1 |
| 0.88 |
|
| 2236 |
|
|
| 18 |
| 1 |
| 0.38 |
|
| 2237 |
|
|
| 19 |
| 1 |
| 0.32 |
|
| 2238 |
|
x = délka věty v počtu slov
fx = empirické četnosti vět o délce x slov
NPx = teoretické četnosti: aproximace smíšeným Poissonovým rozložením s parametry a = 7.360, b = 3.307 a c = 0.174.
f'x = kumulativní četnost vět o dané délce
P(χ2) = 0,9323
χ2 = 6.3546
Tab. 2. Rozdělení větných délek v knize M. Macourka Žofka ředitelkou zoo
[177]
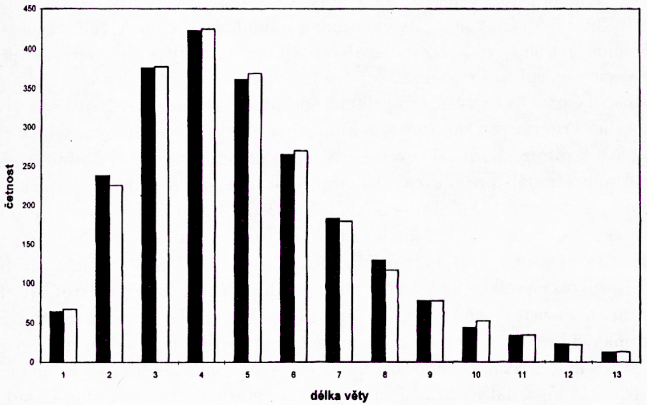
■ – empirické četnosti slovních délek, □ – teoretické četnosti slovních délek
Obr. 2. Histogram rozdělení větných délek (podle tab. 2)
stylistické studii, velmi často se délkových charakteristik využívá jako jedné z měr čtivosti apod. Techniku práce s daty usnadňuje dnes již existující programové vybavení (např. Altmann, 1994), jehož pomocí lze na základě optimalizačních metod proložit empirickými daty nejlépe vyhovující typ diskrétního pravděpodobnostního rozdělení.
Z příkladů rozdělení, které jsme uvedli, je zřejmé, že podstata využití statistických metod v lingvistice nespočívá pouze v tom, že tyto metody umožňují popsat soubor jazykových dat v běžných statistických termínech, jakými jsou např. průměr, modus, medián, rozpětí, rozptyl atd., nýbrž v tom, že umožňují na základě konkrétních empirických dat (tj. na základě omezeného počtu pozorování) dospět k zobecňujícím závěrům, totiž posoudit, do jaké míry se empirické hodnoty nějaké náhodné lingvistické veličiny shodují s pravděpodobnostmi náhodné veličiny s určitým rozdělením. Využití teorie pravděpodobnosti v lingvistice má přitom své charakteristické rysy, jimiž se odlišuje od statistického modelování v různých jiných oblastech lidské činnosti. O řadě aplikačních oblastí totiž platí, že praktická znalost toho, jakým rozdělením se určitá náhodná veličina řídí, je dána dlouhodobou zkušeností. Je například známo, že dobu životnosti v teorii spolehlivosti nebo čekání na zákazníka v teorii obsluhy lze vhodně modelovat exponenciálním rozdělením, dále že pro modelování průtoků v řekách se hodí logaritmicko-normální rozdělení, popř. Pearsonovo rozdělení typu III apod. (srov. Jarušková a kol., 1995, zejm. s. 25–34). Naproti tomu v lingvistice podobnými dlouhodobými zkušenostmi disponujeme jen pro určité konkrétní případy. Víme například, že vztah mezi četností slova a jeho pořadím při uspořádání podle klesajících četností se řídí Zipfovým-Mandelbrotovým rozdělením (o Zipfově-Mandelbrotově funkci viz též dále v této [178]stati). V mnoha případech jsou však statistické hypotézy v lingvistice orientovány právě na zjišťování toho, zda zkoumaná náhodná veličina se řídí, anebo neřídí rozdělením určitého typu. Formulace statistické hypotézy a její ověření je přitom vždy vázáno na splnění matematických i lingvistických předpokladů. Předpoklady matematické povahy se týkají například podmínek, za nichž lze užít testu χ2 jako testovacího kritéria pro dobrou aproximaci empirických dat daným typem rozdělení (patří k nim rozhodnutí o volbě hladiny významnosti testu, dostatečný počet stupňů volnosti, dále požadavek, aby empirické četnosti dosahovaly alespoň hodnot 5 nebo vyšších apod.). Jedním ze základních předpokladů lingvistických je, aby byl statisticky zkoumán text, ev. jinak definovaný soubor dat jako celek, nikoli pouze náhodný výběr z něj. Bylo například dokázáno, že některé statistické zákonitosti platné pro text vcelku neplatí pro náhodné výběry z textů (srov. Hřebíček, 1995, při popisu textové roviny tzv. agregátů). Filozofické zdůvodnění lingvistické podmínky, že pouze text jako celek může být statistickou populací, poskytuje synergetická lingvistika, formulovaná v pracích Altmanna, 1988, 1993; Köhlera, 1993; Hřebíčka, 1995, a dalších. Další zásadou je, že statistické chování například délky řetězců lze studovat jen tehdy, je-li mezi jednotkou měřenou a jednotkou, v níž měříme, lingvisticky definovatelná relace. Například délku slova měříme ve slabikách, délku věty jednoduché ve slovech, délku složitějších větných celků v počtu hlavních a vedlejších vět, jimiž jsou vytvářeny, atd. Avšak stejně jako neříkáme například, že „věta se skládá ze slabik“, nepodaří se pravděpodobně nalézt ani žádný typ statistického rozdělení, které by modelovalo rozdělení větných délek v počtu slabik.
2. Formulace statistické hypotézy se stane komplikovanější, pokud se rozhodneme sledovat chování dvou náhodných lingvistických veličin, například délky slova a jeho pozice ve větě, ve vzájemné souvislosti. Položme si otázku, jakých hodnot nabývá délka slova (resp. slovního tvaru) v i-té pozici ve větě skládající se z j slovních tvarů, kde pozice čítáme od 1 do j zleva doprava a kde za slovní tvar považujeme slovní útvar mezi dvěma mezerami.
Úloha se skládá alespoň ze dvou kroků:
První krok. Úloha má smysl pouze tehdy, podaří-li se nejprve empiricky dokázat, že délka slova (slovního tvaru) skutečně může sloužit jako jeden z kvantitativních ukazatelů, jehož pomocí lze indikovat sémantickou důležitost slova (slovního tvaru) při jeho užití ve větě. Lze přitom vyjít z obecně známého poznatku, že slova synsémantická bývají kratší než slova autosémantická, a ověřit hypotézu, že existuje statisticky významný vztah mezi délkou slova a jeho příslušností k slovnímu druhu. Jako jednoduchá veličina vhodná k popisu tohoto vztahu se nabízí aritmetický průměr: Můžeme se ptát, jak se vzájemně od sebe odlišují průměrné délky slovních tvarů náležejících k různým slovním druhům. Slovní druhy chápeme tak, jak je to běžné v současných výkladových slovnících spisovné češtiny, délku slovních tvarů měříme opět v počtu slabik, za větnou jednotku považujeme nikoli celek „od tečky k tečce“, nýbrž jednotlivé predikační jednotky (občas nazývané „klauze“), z nichž se větný celek skládá. Výsledky empirického pozorování jsou uvedeny
| [179] |
| Zipf-Mandelbrot | Altmann |
| pořadí | x̄ | f(x) | f(x) |
| 1. adjektiva | 2.85 | 2.85 | 2.85 |
| 2. substantiva | 2.49 | 2.33 | 2.49 |
| 3. slovesa | 2.13 | 2.11 | 2.18 |
| 4. příslovce | 1.88 | 1.91 | 1.93 |
| 5. číslovky | 1.77 | 1.73 | 1.72 |
| 6. částice | 1.67 | 1.57 | 1.54 |
| 7. spojky | 1.32 | 1.42 | 1.38 |
| 8. zájmena | 1.29 | 1.28 | 1.25 |
| 9. předložky | 1.06 | 1.16 | 1.13 |
x = průměrná délka slovního druhu (empirické hodnoty)
f(x) = teoretické hodnoty:
Zipfova-Mandelbrotova funkce (D = 0.98)
Altmannova funkce (D = 0.99)
Tab. 3. Průměrná délka slovních tvarů (v počtu slabik) podle jednotlivých slovních druhů
v tab. 3. Tyto výsledky ukazují, že průměrná délka slova (x̄) při jeho užití ve větě se u jednotlivých slovních druhů skutečně liší. V průměru nejdelší jsou tvary adjektiv, jejichž průměrná délka dosahuje 2,85 slabik, o něco kratší jsou v průměru tvary substantiv, 2,49 slabik, za nimi následují dále tvary slovesné, 2,13 slabik, po nich příslovce, 1,88 slabik, atd.; vůbec nejkratším slovním druhem jsou předložky s průměrnou délkou 1,06 slabik. Z tabulky lze vyčíst, o kolik jsou jednotlivé základní autosémantické slovní druhy v průměru delší než slovní druhy synsémantické. Slovní druhy jsou v tabulce seřazeny podle klesající hodnoty jejich průměrné délky. Lze ověřit, že vztah mezi takto stanoveným pořadím slovních druhů a jejich průměrnou délkou v textech se řídí Zipfovou-Mandelbrotovou závislostí neboli že je popsatelný vzorcem
f(x) = (b + x)–a
kde x = 1, 2, 3, …, a, b > 0.
Teoretické hodnoty Zipfovy-Mandelbrotovy funkce jsou uvedeny v druhém sloupci tabulky 3.
Jak ukázal Altmann (1993), pracujeme-li s pořadím průměrných hodnot délek, a nikoli přímo s délkou jako náhodnou proměnnou, nejde o pravděpodobnostní rozdělení, nýbrž o funkci posloupnosti hodnot. Altmann (s. 61) odvodil (změnou diferenciální rovnice na diferenční) pro popis vztahu mezi pořadím a frekvencí
| [180] |
|
|
|
|
|
|
|
|
|
| délka | slovní druh | ||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| Su | Adj | Zá | Nu | Sl | Ad | Pr | Sp | Pa |
|
|
|
|
|
|
|
|
|
|
|
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 310 | 0 | 0 |
| 1 | 258 | 17 | 1357 | 42 | 625 | 310 | 496 | 829 | 238 |
| 2 | 1321 | 305 | 334 | 82 | 1045 | 382 | 42 | 304 | 195 |
| 3 | 914 | 212 | 76 | 9 | 567 | 116 | 3 | 33 | 49 |
| 4 | 301 | 110 | 7 | 1 | 162 | 42 | 0 | 0 | 12 |
| 5 | 30 | 46 | 1 | 0 | 15 | 2 | 0 | 1 | 0 |
| 6 | 10 | 7 | 0 | 0 | 1 | 0 | 0 | 0 | 0 |
| 7 | 0 | 2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 8 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 9 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
|
| 2834 | 699 | 1775 | 134 | 2415 | 852 | 851 | 1167 | 494 |
| % | 25,3 | 6,2 | 15,8 | 1,2 | 21,5 | 7,6 | 7,6 | 10,4 | 4,4 |
Tab. 4. Rozdělení četností délek jednotlivých slovních druhů (v počtu slabik)[2]
vlastní funkci, analogickou funkci Zipfově-Mandelbrotově. Tato funkce, popsaná vzorcem
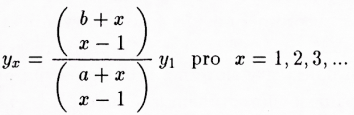
dává pro naše data stejně dobré výsledky jako funkce Zipfova-Mandelbrotova; viz tab. 3, sloupec třetí. Jako testu dobré shody bylo v obou případech použito koeficientu determinace (Altmann, 1993, s. 62).[3]
Můžeme se rovněž pokusit charakterizovat délku slovních druhů nikoli pomocí jediné elementární statistické veličiny, jakou je výše uvedený aritmetický průměr, nýbrž podle rozdělení četností jednotlivých délek u každého slovního druhu zvlášť. V takovém případě lze položit otázku, zda lze aproximovat rozložení délky substantiv, adjektiv atd. nějakými pravděpodobnostními rozděleními, a pokud ano, zda se taková rozdělení pro jednotlivé slovní druhy liší. Empirické četnosti délkových rozdělení pro jednotlivé slovní druhy uvádí tab. 4. K výpočtu optimálních typů teoretických rozdělení bylo použito Altmannova programového vybavení (Altmann, 1994). Výsledky (z prostorových důvodů je nelze v tabulce uvádět) ukázaly, že pro většinu slovních druhů je k proložení vhodný některý z typů Poissonova [181]rozdělení (ale nikoli týž typ pro všechny slovní druhy; poměrně širokou aplikabilitu má například Daceyho-Poissonovo rozdělení), popřípadě ještě některé další typy rozdělení. Jako testovacího kritéria bylo možno v některých případech použít testu χ2, v jiných případech však pouze koeficientu kontingence. U krátkých slovních druhů (spojky, předložky) vadí při pokusu o proložení vhodného rozdělení malý počet stupňů volnosti. U adverbií se jako u jediného slovního druhu nepodařilo najít žádné rozdělení, pravděpodobně pro velikou heterogennost tohoto slovního druhu.
Tím lze hypotézu o tom, že délka slova je charakteristickou vlastností jednotlivých slovních druhů, považovat za kvantitativně dostatečně prokázanou. Nyní lze přistoupit k druhému kroku, který je vlastním řešením výše formulované úlohy o kvantitativním vztahu mezi délkou slova a jeho pozicí ve větě.
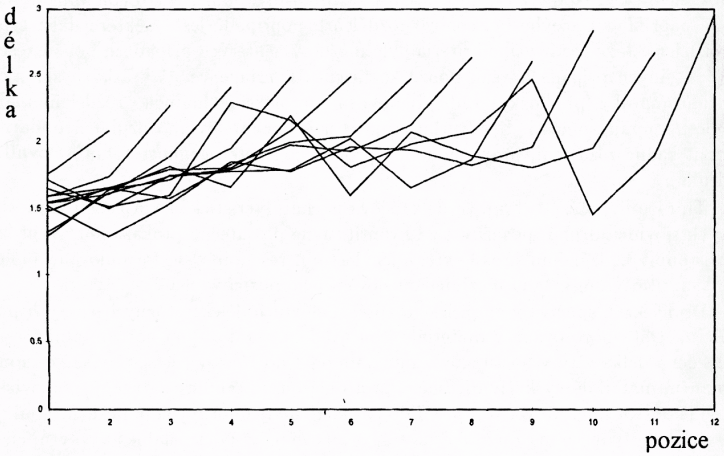
Druhý krok spočívá v empirickém zjištění slovních délek v různých větných pozicích. Data pozorovaná v materiále jsou uvedena v tab. 5; na horizontální ose je uvedena délka věty v počtu slov v intervalu od 1 do 15 slov (delší věty se ve zkoumaném materiále vyskytly ojediněle, proto nejsou do tabulky zařazeny), na svislé ose je pozice slova ve větě od první do patnácté a v jednotlivých políčkách tabulky jsou hodnoty průměrné délky slov (měřené v počtu slabik) vyskytujících se v dané pozici ve větách o dané délce. Grafickým obrazem této tabulky je obr. 3. V tomto obr. je na horizontální ose uvedena délka věty (= počet pozic ve větě), z technických důvodů useknutá zde u délky 12 slov, a na svislé ose průměrná délka slova v příslušných pozicích. Graf tedy obsahuje jedenáct křivek pro větné délky od 2 do 12 slov.
O čem svědčí data uvedená v tab. 5? (a) Pokud jde o celkovou charakteristiku průběhu hodnot, ukazuje se zcela zřetelně, že nejkratší průměrnou délku mají slova vždy v počáteční větné pozici – viz hodnoty v prvním řádku tabulky. U slov zaujímajících druhou, třetí, čtvrtou a každou další pozici hodnoty průměrných délek

Tab. 5. Průměrná délka slova v jednotlivých pozicích ve větách různých délek
[182]
Obr. 3. Průměrná délka slova v jednotlivých pozicích ve větách různých délek
postupně vzrůstají – viz sloupce hodnot pro jednotlivé větné délky. Nejvyšší hodnoty jsou vždy v poslední větné pozici; v tabulce jsou těmito hodnotami hodnoty na diagonále. Vzrůst průměrné slovní délky podle větných pozic ve směru zleva doprava je velmi pravidelný u vět o dvou až osmi slovech, tedy u vět, které jsou v textu nejčetnější. Podíl těchto vět na struktuře textu činí 88 % (viz tab. 3 výše, údaj fx o kumulativních četnostech). Pouze ve větách delších než osm slov je ve středních pozicích mírné kolísání, to znamená, že jistá tendence k střídání dlouhých a krátkých slov se tedy projevuje jen v poměrně malém počtu velmi dlouhých vět. Výlučnost hodnot průměrů v počáteční větné pozici stejně jako v koncové větné pozici se však projevuje ve větách všech délek bez výjimky: Počáteční pozice je pozicí „krátkých“ slovních druhů, zatímco koncová pozice je pozicí „dlouhých“ slovních druhů. (Zvlášť je třeba posuzovat věty o délce 1, v nichž počáteční a koncová pozice splývají.)
(b) Z grafického znázornění je dobře patrné, že křivky mají analogický průběh pro věty všech délek. Jinak řečeno, tvar křivky není specifickou charakteristikou vět jednotlivých délek. Tento poznatek by se mohl ukázat užitečným vodítkem při dalších statistických úlohách týkajících se věty, např. při rozpoznávání větných hranic v textu. Víme-li zároveň, že rozdělení větných délek se řídí Poissonovým rozdělením (viz výše), bylo by možno například zkoumat otázku, s jakou pravděpodobností lze očekávat, že slovo o délce x slabik bude spíše zahajovat, či spíše ukončovat větu.
(c) Podobný graf týkající se vztahu mezi délkou slova a jeho pozicí ve větě byl sestrojen na základě dat o finštině, tedy o jazyce češtině typologicky vzdáleném. O finsky psané práci Niemikorpiho (1991) referoval anglicky Saukkonen (1994, s. 6) [183]v přehledové stati o finské kvantitativní lingvistice. Křivky Niemikorpiho grafu mají – přes rozdílné podmínky statistického šetření – průběh velmi podobný křivkám v grafu 3, který je sestrojen na základě poměrů v češtině. Lze vyslovit hypotézu, že empiricky zjištěná charakteristika vztahu mezi délkou slova a jeho pozicí ve větě může platit nejen pro češtinu či pro finštinu, ale i pro další jazyky; zdá se, že například též pro malajskou poezii (Altmann, 1963).
3. Lze říci, že statistická data, která jsme získali pozorováním českého jazykového materiálu, podporují hypotézu o tom, že vztah mezi délkou slova a jeho polohou ve větě je kvantitativně vyjádřitelný. To, že slova ve větě jeví tendenci následovat po sobě tak, aby pozice na počátku (resp. poblíž počátku) byla obsazována v průměru kratšími slovy než pozice koncová (resp. pozice poblíž konce), neboli že slova dlouhá mají tendenci se hromadit na konci věty, je možno interpretovat jako kvantitativní výraz realizace funkčního principu vzrůstající obsahové závažnosti slov (výrazů) ve směru zleva doprava. Už ze základních principů komunikační perspektivy výpovědi přirozeně vyplývá, že právě počátek věty je podstatně více zakotven v předešlém kontextu než její konec, a je proto přirozené, že se tu výrazněji uplatňují právě krátké slovní druhy synsémantické, signalizující textovou kohezi. Naproti tomu směrem ke konci věty se hromadí nejdůležitější informace, vyjadřovaná slovy autosémantickými, v prvé řadě substantivy. Lze tedy očekávat nejen velkou převahu substantiv na konci věty, ale i to, že v lineární distribuci slovních druhů bude mnohem větší shoda mezi texty (žánry, styly, …) na konci věty než na jejím počátku (potvrzují to i data Uhlířové, 1990), neboť právě využívání prostředků textové koheze a explicitnost či naopak implicitnost jejího vyjádření je do značné míry specifickou záležitostí jednotlivých textů či textových typů.
Zjištěný empirický vztah nemusí být, alespoň ve své obecné podobě, závislý ani na povaze konkrétního zkoumaného textu, ani na konkrétním jazyce.
Dalším krokem (Uhlířová, 1996) musí být podrobnější zjištění toho, které slovní druhy a s jakou četností obsazují počáteční a koncovou pozici ve větě a do jaké míry způsob obsazování pozic souvisí s délkou věty.
LITERATURA
ALTMANN, G.: Phonic structure of Malay pantun. Archiv orientální, 31, 1963, s. 274–286.
ALTMANN, G.: Wiederholungen in Texten. Bochum 1988.
ALTMANN, G.: Phoneme counts. Glottometrika, 14, 1993, s. 54–68.
ALTMANN, G.: Altmann-Fitter. Iterative Anpassung diskreter Wahrscheinlichkeitsverteilungen. Lüdenscheid 1994.
ALTMANN, G. – ERAT, E. – HŘEBÍČEK, L.: Word length distribution in Turkish texts. Glottometrika, 15, 1996, s. 195–204.
ALTMANN, G. – BEST, K.-H.: Zur Lange der Wörter in deutschen Texten. Glottometrika, 15, 1996, s. 166–180.
HŘEBÍČEK, L.: Text as a construct of aggregations. In: R. Köhler – B. B. Rieger (ed.), Contributions to Quantitative Linguistics. Dordrecht – Boston – London 1993, s. 33–39.
HŘEBÍČEK, L.: Fractals in language. Journal of Quantitative Linguistics, 1, 1994, s. 82–86.
HŘEBÍČEK, L.: Text Levels. Language Constructs, Constituents and the Menzerath-Altmann Law. Quantitative Linguistics, vol. 56. Trier 1995.
HŘEBÍČEK, L. – ALTMANN, G.: Levels of order in language. Glottometrika, 15, 1996, s. 38–61.
[184]JARUŠKOVÁ, D. a kol.: Matematická statistika. ČVUT, Fakulta stavební, Praha 1995.
KÖHLER, R.: Synergetic linguistics. In: Contributions to Quantitative Linguistics. Proceedings of the First International Conference on Quantitative Linguistics, QUALICO, Trier 1991. Dordrecht – Boston – London 1993, s. 41–51.
NIEMIKORPI, A.: Suomen kielen sanaston dynamiikkaa. Acta Wasaensia No 26, Kielitiede 2. Vaasan yliopisto, Vaasa 1991.
SAUKKONEN, P.: Main trends and results of quantitative linguistics in Finland. Journal of Quantitative Linguistics, 1, 1994, s. 2–15.
UHLÍŘOVÁ, L.: The beginning and the end of sentence. A quantitative study in the Present-Day Czech. In: Prague Studies in Mathematical Lingustics, 10. Prague 1990, s. 65–73.
UHLÍŘOVÁ, L.: O jednom modelu rozložení délky slov. SaS, 56, 1994, s. 8–14.
UHLÍŘOVÁ, L.: On the generality of statistical laws and individuality of texts. A case of syllables, word forms, their length and frequencies. Journal of Quantitative Linguistics, 2, 1995, s. 238–247.
UHLÍŘOVÁ, L.: How long are words in Czech? Glottometrika, 15, 1996, s. 134–146.
UHLÍŘOVÁ, L.: Word length distribution in Czech. Glottometrika, 16, v tisku.
UHLÍŘOVÁ, L.: On the word length and clause length from the word order perspective. Referát na Kolokviu o kvantitativní lingvistice, Trier, říjen 1996.
WIMMER, G. – ALTMANN, G.: The theory of word length: Some results and generalizations. Glottometrika, 15, 1996, s. 112–133.
WIMMER, G. – KÖHLER, R. – GROTJAHN, R. – ALTMANN, G.: Towards a theory of word length distribution. Journal of Quantitative Linguistics, 1, 1994, s. 98–106.
R É S U M É
On a relationship between word length and word placement in the clause
The paper deals with statistical modelling of some properties of words and clauses in Czech. Models of probability distributions of word length (measured in number of syllables) and clause length (measured in number of words) are proposed, the hypothesis that the word length is a characteristic variable of each part of speech is tested, and the hypothesis that there is a close association between length of a word and its position in clause is empirically verified.
[1] Podrobný komentář ke způsobu počítání slabik v textu viz Uhlířová (1996).
[2] Při výpočtu průměrné délky předložek se neslabičné předložky počítají dohromady s jednoslabičnými.
[3] Článek vznikl s podporou projektu GA ČR 102/96/K087. Za matematickou konzultaci a pročtení rukopisu děkuji prof. Gabrielu Altmannovi.
Slovo a slovesnost, ročník 58 (1997), číslo 3, s. 174-184
Předchozí Jan Kořenský: Kam se vlna obrací aneb nikoli anti-Beaugrande
Následující Jaroslava Hlavsová: Čeština v České republice jako jazyk „nevlastní“
© 2011 – HTML 4.01 – CSS 2.1