
Metoda morfémové analýzy založená na aplikaci teorie pravděpodobnosti
Eleonora Slavíčková
[Articles]
Метод анализа морфем, основанный на применении теории вероятности / Méthode de l’analyse des morphèmes basée sur l’application de la théorie de la probabilité
Tradiční jazyková analýza si volila za výchozí jednotku výzkumu slovo. Ovšem slova můžeme ještě členit na menší významové elementy jazykové struktury — morfémy. Metodika morfémové analýzy je však dosud velmi málo propracována, třebaže není nová. Pokládáme proto za nutné objasnit nejprve naše pojetí základních pojmů, o něž se pak opírá vlastní návrh metody morfémové analýzy.
I. VYMEZENÍ ZÁKLADNÍCH POJMŮ
a) Pojem morfému. Definovat morfém je nesnadné vzhledem k rozdílným aspektům jeho interpretace u různých autorů a k různým názorům na klasifikaci morfémů. Definicí morfému se zabývali již v třicátých létech někteří lingvisté strukturálního směru pražského a pak amerického, kteří první aplikovali strukturní metody na výzkum jazykového materiálu.
V pražské škole se obvykle vycházelo z definice uvedené v „Návrhu standardní fonologické terminologie“ Pražského lingvistického kroužku.[1] Otázkami definice morfému a jeho klasifikace se na sklonku třicátých let zabývaly některé práce Skaličkovy a Trubeckého.[2] Definice jsou shrnuty s uvedením literatury u J. Vachka v jeho Dictionnaire de linguistique de l’école de Prague 1960, 49.
Z novější literatury jsme se mohli opřít pouze o práce zkoumající problémy morfému z hlediska tvoření slov, a to jednak naše (Horecký, Dokulil, Poldauf),[3] jednak sovětské (Vinokur, Smirnickij, Šanskij, Levkovskaja, Kovalyk.)[4]
[95]Hlavní představitelé amerického strukturalismu dodnes v podstatě vycházejí z definice Bloomfieldovy:[5] morfém je řada fonémů mající význam. Tak Bloch a Trager[6] v duchu koncepce „volných“ a „vázaných“ forem (free forms, bound forms) definují morfém jako volnou nebo vázanou formu, kterou není možno dále členit na menší části mající význam. Gleason[7] se nejprve vzdává přesné definice morfému a argumentuje tím, že nejlépe by bylo definovat morfém jako nejmenší gramatickou jednotku. Ovšem v tom případě bychom definovali gramatiku jako nauku o morfémech a jejich kombinacích, což by znamenalo zřejmou tautologii. Proto Gleason, podobně jako Nida,[8] pouze popisuje některé charakteristické rysy morfémů a podává obecné zásady pro jejich identifikaci.
V této práci vycházím z Dokulilovy definice morfému: „Morfém je nejmenší dále nedělitelná část slova, která má přímý nebo nepřímý vztah k významu“ (op. cit. v pozn. 3, 162).
Pro úplnost pokládám za nutné vysvětlit též své stanovisko k pojmům „rozštěpeného“ morfému (morphème brisé) a „spojovacího“ morfému. Jako „rozštěpený“ morfém hodnotí někteří lingvisté případy typy ná-dvoř-í, po-břež-í, kde ná- + -í, popříp. po- + -í považují za jeden „rozštěpený“ morfém. Podle našeho názoru není nutné tento pojem zavádět, jde zde prostě o dva funkčně spjaté morfémy, o prefixálně sufixální tvoření, které probíhá současně, tvar tvořený pouze prefixálně, ani pouze sufixálně nemůže existovat samostatně. „Spojovacím“ morfémem se rozumí část morfologicky rozčleněného slova (vesměs jde o slova složená), která zbývá po vyčlenění morfémů majících přímý vztah k významu. Při morfologickém rozboru složených slov se totiž vyděluje část, která není nositelem ani lexikálního ani gramatického významu. Např. spojovací vokál -o- ve vlastních slovech složených: vod-o-vod, život-o-pis apod. Ačkoli tedy spojovací morfém není nositelem významu, může mít určitou funkci, např. v našem případě spojuje dva pojmenovávací základy.
Spojovací morfém je třeba odlišovat např. od tematického vokálu u sloves, který má určitý vztah k významu, jak můžeme vidět na dvojicích děl-á-m, děl-í-m; vol-á-m, vol-í-m. Tematický vokál tedy nezahrnujeme pod pojem spojovacího morfému, jako to činí např. Ružička.[9]
b) Pojem distribuce a variantnosti morfémů. Vzájemné seskupování morfémů je podmíněno především dvěma aspekty: 1. významem (v jeho poněkud mlhavém smyslu), 2. distribucí. Z těchto dvou aspektů je objektivnější distribuce. Distribuce libovolného morfému je souhrn všech typů morfémů, v jejichž okolí se může daný morfém vyskytovat. Vedle toho je nutno vyjasnit si pojem varianty morfému.[10]
[96]Elementárnost morfému (tedy nemožnost jeho členění na menší jednotky) neznamená jeho neměnnost. Morfém může mít varianty. Jako varianty hodnotíme všechny obměny morfému, jejichž výskyt je podmíněn určitými fonologickými nebo morfologickými faktory okolí.
Toto kritérium lze však aplikovat různě, poněvadž existují různé typy distribuce. V podstatě rozlišujeme dva typy kritérií pro přiřazování variant k jednomu morfému. Dva elementy (nebo více) můžeme považovat za jeden morfém, a) mají-li nějaký společný význam a b) jsou-li ve vztahu komplementární distribuce, podmíněné nějakým fonologickým nebo morfologickým faktorem. O dvou elementech možno říci, že jsou ve vztahu komplementární distribuce, jestliže se jeden z nich vyskytuje v takovém okolí, v jakém se nikdy nevyskytuje druhý, tj. jestliže neexistuje okolí, v kterém by se mohly vyskytovat oba.
Většinou jde o změny hláskového skladu morfému v určitých pozicích. Nejčastější jsou tyto hláskové alternace u variant kořenových morfémů, např. such-o × suš-i-t, kouř × kuř-ák, hrad × hrád-ek atd., v menší míře varianty, nepodmíněné fonologicky: nes-u × nos-ím, švec × ševc-e.
Naopak varianty afixálních morfémů vznikají často jako výsledky morfologických procesů (např. tzv. perintegrace nebo absorpce). Jejich variantní formy jsou úplně shodné funkčně, ale liší se svým zvukovým složením tak, že určitá část zvukového komplexu morfému zůstává stále nezměněna a morfém se jen různě rozšiřuje. Např. varianty morfému -ík: kadeř-ník, roh-lík, kulomet-čík, uč-edník.
Aplikace těchto pojmů nám umožňuje uspořádat složitou vnitřní strukturu slov zkoumaného jazyka do určitých tříd morfémů, z nichž každá má svou charakteristickou distribuci. Např. morfémy čaj-, -dobr-, -přá- mohou představovat určitou třídu morfémů — nazveme ji např. A. Právě tak morfémy -ník, -ým, -t můžeme seskupit do určité třídy, nazvané např. B. Ty se však mohou vyskytovat jen bezprostředně za jedním z morfémů třídy (A) nebo za libovolnou ekvivalentní konstrukcí. Morfémy třídy (A) pak mohou bezprostředně předcházet morfémy třídy (B), ovšem ne kterýkoli morfém třídy (A) se může spojovat s kterýmkoli morfémem třídy (B) — čaj-ník, ale ne dobr-ník, přá-ník apod.
c) Pojem morfémové analýzy. Při morfémové analýze nám jde o zkoumání vnitřní struktury slov. Opíráme se přitom o systémovost jazykových jevů, která nám skýtá možnost porovnávání modelů jednotlivých slov. Slova mají komplexní povahu — jsou složena z opakovatelných a kombinovatelných elementů, které lze třídit, popsat a hodnotit.
Morfémová analýza bývá buď směšována s analýzou slovotvornou, anebo zase považována za čistě formální rozčlenění slova. Rozdíl metodiky analýzy morfémové a slovotvorné v podstatě objasnil M. Dokulil (op. cit. v pozn. 3, 160) tak, že zatímco analýza morfémová člení slova na řadu morfémů (ať už kratší nebo delší), dělí analýza slovotvorná slovo bez ohledu na počet morfémů na dva členy: slovotvorný kmen a slovotvorný formant (a to vždy na základě vztahu mezi útvarem výchozím a výsledným). Např. slovo pracovat člení slovotvorná analýza nejprve na slovotvorný kmen pracova- a slovotvorný formant -t a dále pak tento slovotvorný kmen pracova- dělí zase ještě na slovotvorný kmen prac- a slovotvorný formant -ova-, kdežto morfémová analýza člení toto slovo na morfémy: kořenový morfém -prac- a afixální morfémy -ova- a -t.
[97]V naší práci jsme při morfémové analýze vycházeli z klasifikace morfémů na morfémy kořenové — nositele významového jádra — a na morfémy afixální — modifikující význam. Funkce afixálních morfémů spočívá tedy v tom, že umožňují pohlížet na týž kořenový morfém z různých perspektiv, ovšem fungovat mohou právě jen ve spojení s nějakým morfémem kořenovým.
Načrtneme zde v krátkosti hlavní problémy, které se objevují v průběhu analýzy. Nejprve přistupujeme k vydělení kořenového morfému. Vodítkem při této analýze je nám „opakovatelnost“. Především zjistíme, zda je zkoumané slovo průzračně motivováno, zda lze jeho význam objasnit pomocí jiných slov obsahujících společný kořenový morfém. Existuje-li aspoň jedno takové slovo, lze kořenový morfém vydělit. Je-li zkoumané slovo z hlediska kořenového morfému zcela nemotivované, je možné zjistit, zda nelze identifikovat část slova formálně i významově jako morfém afixální. V kladném případě se nám vyčlení kořenový morfém jako tzv. morfém zbytkový, reziduální, jehož význam lze odvodit jen na základě analogie s jinými slovy, složenými podle téhož modelu, např. mal-in(a) podle ostruž-in(a), jeřab-in(a).
Toto kritérium je předmětem sporů a diskusí odborníků zabývajících se výzkumem tvoření slov. Tak např. Smirnickij (op. cit. v pozn. 4) soudí, že k tomu, abychom mohli členit kmen, obecně stačí, jestliže aspoň jedna z obou složek (připomeňme si, že z hlediska slovotvorné analýzy probíhá členění binárně) je identifikovatelná, tj. vchází-li kmen aspoň v jednu řadu s nějakým společným afixem (tak mal-in(a) lze členit proto, že -in(a) lze ztotožnit významově a formálně s řadou -in(a) v jiných názvech plodů tohoto druhu). Naproti tomu Vinokur (op. cit. v pozn. 4) má za to, že je možné oddělit jen takový fonematický úsek, po jehož odtržení má zbylý kořenový morfém určitý, v daném jazyce běžný význam. Vinokurův názor zastává též Horecký, zatímco v koncepci naší práce se stavíme za stanovisko Smirnického.
Setkáme se též s případy, kdy kořenový morfém může existovat pouze ve spojení s afixálními morfémy, např. ob-ou(t), z-ou(t). Namítá se, že v těchto případech nelze kořenový morfém vydělit, poněvadž v jazykovém povědomí existenci takového kořene nepociťujeme. Tento názor má jisté psychologické opodstatnění, ovšem z hlediska lingvistického jej nemůžeme bezvýhradně přijmout.
V některých případech jsme na vahách, máme-li v určité řadě příbuzných slov považovat za kořen nejmenší společný zvukový komplex nebo hodnotit rozdíly ve zvukovém složení jako rozšířené varianty kořene — poe-zi(e), poe-m(a), poe-t(a) nebo poez-i(e), poem(a), poet(a). V naší práci se přikláníme k druhé možnosti, tj. chápeme takové druhy morfémů jako rozšířené varianty kořenového morfému.
Při vyčleňování afixálních morfémů není nutno aplikovat kritérium „opakovatelnosti“. Např. u slov pastucha, sekyra, přízeň můžeme vydělit afixální morfémy -tucha, -yra, -zeň, i když jsou to morfémy ojedinělé; jejich vyčlenění lze totiž odůvodnit významovým vztahem ke slovům pásti, sekati, přáti ap. Nebo varianta morfému -e u neuter (-e rozšířeno v sg. o -et-, v pl. o -at-) se objevuje pouze u názvů mláďat.
U afixálních morfémů narážíme také často na problémy hodnocení variantnosti těchto morfémů. Např. morfému deverbativ -dlo předchází většinou tematický vokál odvozovacího slovesa, např. struh-a-dl(o); ale vyskytnou se případy, kdy -a- nemůžeme hodnotit jako tematický vokál, poněvadž v slovese, z kterého odvo[98]zujeme, plní tuto funkci jiná hláska, např. drž-e-t, ale drž-adl(o). Zde je morfém -adl(o) variantou morfému -dl(o).
Při analýze slov navozujících představu o „složenosti“ takovýchto morfémů si však musíme opět uvědomit rozdíl mezi analýzou slovotvornou a morfémovou. Analýza slovotvorná vychází např. při analýze slova sborovna z faktu, že jde o slovo odvozené od substantiva sbor příponou -ovn(a) s významem „místa, kde se schází sbor“, podle analogické řady stroj-ovn(a) „místo, kde jsou stroje“, knih-ovn(a) „místo, kde jsou knihy“ atd. Při morfémové analýze musíme však respektovat jednak fakt, že existuje např. adjektivum sborový, jednak také fakt, že existují slovotvorné kategorie, v nichž slovotvorný formant má podobu pouhého -n(a), např. kůl-n(a). Z toho plyne, že morfémová analýza člení např. slovo sborovna na pět morfémů: s-bor-ov-n-a.
Ještě je třeba ujasnit si problém stanovení hranic mezi morfémy. Pro češtinu a ruštinu — jakožto jazyky flexívní — je charakteristická tendence k rozplývání hranic mezi morfémy. Jde zvláště o případy překrývání morfémů — jeden morfém je složkou morfému druhého, např. v slově čtvrteční můžeme chápat -eč- i jako samostatný morfém (vzhledem ke čtvrtek) i jako část morfému -eční (vzhledem ke střed-eční); dále o případy překrývání hlásek — při styku dvou morfémů, z nichž jeden končí a druhý začíná stejnou nebo foneticky blízkou hláskou. Dochází pak tedy k tomu, že jedna hláska je součástí obou morfémů, např. měšť-á→c←tv(í), kup-e→c←tv(í), rol-ni→c←tv(o) atd. V prvním případě — u slova čtvrteční — je pro naše účely vhodné vydělit obě složky „složeného“ morfému -eční zvlášť, tedy čtvrt-eč-n(í). V druhém případě je situace obtížnější, poněvadž hlásku v takové pozici (Dokulil užívá termínu „morfémový uzel“, op. cit. v pozn. 3) je možné přiřadit pouze k jednomu morfému. Vzhledem k našemu způsobu vyjádření složenosti slova (což bude uvedeno dále) považujeme za vhodnější přiřazovat tuto hlásku k morfému pozičně bližšímu, kořenovému morfému. V konečných výsledcích tím nedojde ke zkreslení, naopak tyto případy je možné kvantitativně zhodnotit a stanovit pravděpodobnost jejich výskytu.
II. METODA MORFÉMOVÉ ANALÝZY ZALOŽENÁ NA APLIKACI TEORIE PRAVDĚPODOBNOSTI
Nový přístup k analýze jazykových faktů předpokládá vysoký stupeň formalizace a zavádění některých matematických metod. Neobejdeme se přitom bez aplikací teorie pravděpodobnosti. Při zavádění pravděpodobnostních metod v lingvistice je nutno především si uvědomit význam kategorie pravděpodobnosti — chápané v nejširším smyslu — pro objasnění vztahů ve struktuře jazyka. Uvnitř každého jazyka existují typická rozložení pravděpodobnosti, vyplývající ze vzájemného působení různých rovin hierarchické struktury jazykového systému. Jejich stanovení nám umožní vyjasnit stupeň determinace jednotlivých rovin co do jejich vzájemných vztahů. Význam aplikace teorie pravděpodobnosti pro analýzu systému jazyka je pak dán ještě tou důležitou okolností, že vztah mezi formou (např. v našem případě určitým komplexem hlásek tvořícím morfém) a významem této formy (tj. významem, který daný morfém v daném případě reprezentuje) má náhodný charakter. Přitom je možné nejen prostě konstatovat náhodnost jevu, ale i kvantitativně vyjádřit možnost jeho výskytu. Jinými slovy, běží zde o problémy gramatické polysémie nebo homonymie (z formálního hlediska se oba pojmy kryjí).
[99]Za určitých podmínek — např. bude-li se určitý afixální morfém A v dané pozici spojovat s určitým kořenovým morfémem K — nastane určitý náhodný jev, tj. morfém A nabude určitého významu, doplňujícího a zpřesňujícího význam kořenového morfému K, přičemž existuje pravděpodobnost p, že to bude určitý gramatický význam, např. význam koncovky 1. sg. feminin.
Např. morfém -i- může v ruštině[11] mít (kromě jiných) tyto „významy“: (1) jako tematický vokál sloves II. časování — govor-i-š’; (2) jako koncovka neuter skloňovaných podle vzoru sobranije v 6. sg.; (3) jako koncovka feminin skloňovaných podle vzoru armija a) v 2. sg., b) v 6. sg., c) v 1. pl., d) ve 4. pl.; (4) jako koncovka maskulin skloňovaných podle vzoru avtomobil’ a) v 1. pl., b) ve 4. pl.; (5) jako koncovka maskulin skloňovaných podle vzoru genij a) v 6. sg., b) v 1. pl.
Význam slova však závisí nejen na samém významu jednotlivých morfémů tvořících slovo, ale i na jejich vzájemném sledu. Každý jazyk má sice ustálený pořádek sledu morfémů v určitých konstrukcích, ale zároveň též určitý stupeň volnosti.
Podstata metody. Pro systemizaci těchto složitých vztahů byla navržena následující formulace — vyjádření slova jako množiny (M), jejímiž členy jsou morfémy, tvořící slovo (S):
MS {n̄k n̄k-1 … n̄1 K n'1 n'2 … n'm}
Slovo je vyjádřeno posloupností morfémů, v níž je vždy aspoň jeden morfém kořenový (K) a určitý počet morfémů připojených ke kořenovému morfému, nazývaných zde souborně morfémy nástavbovými (n). Přitom počet morfémů předcházejících kořenovému morfému (K), označených symbolem (n̄), je dán množinou
MK (n̄) {n̄1 n̄2 … n̄k-1 n̄k}
a počet morfémů následujících za kořenovým morfémem (K), označených symbolem (n'), je dán množinou
MK (n') {n'1 n'2 … n'm}
Každý člen těchto množin může mít libovolný počet variant, např.
MK (n'1) {a'1 b'1 … z'1}
Vycházíme zde tedy z principu seskupování slov vzhledem k jejich významovému jádru. To je charakteristická linie morfémové analýzy, nazveme ji horizontální. Výsledkem jejího zkoumání je zjištění produktivnosti jednotlivých kořenových morfémů, stanovení pravděpodobnosti výskytu určitých modelů spojování morfémů atd. Můžeme však sledovat ještě druhou linii — vertikální, která se projevuje ve shodě formy a funkce nástavbových morfémů a s jejíž pomocí lze stanovit pravděpodobnosti výskytu určitých druhů morfémů v určitých pozicích, např. vydělení množiny morfémů předponových rozdělené na podmnožiny podle pozic n̄1, n̄2 atd. Obě tyto linie vytvářejí řady morfémů, které se vzájemně kříží, přičemž všechny tyto vztahy lze přesně zachytit a zhodnotit kvantitativně.
Uveďme příklad: rozčleněním slova šroubek na morfémy šroub- a -ek můžeme vydělit jednak řadu slov seskupených kolem kořenového morfému šroub-, např. šroub-y, šroub-ov(ý), šroub-ova-t, [100]šroub-ov-ák atd., a jednak řadu slov seskupených kolem nástavbového morfému -ek, mající společný význam zdrobnělosti, např. kohout-ek, strom-ek, sloup-ek, džbán-ek atd.
Podobně rozčleněním slova přemístili vznikne jednak řada se společným kořenovým morfémem -míst- s lexikálním významem nějakého ohraničeného prostranství, jednak řady: (1) se společným morfémem pře- s významem „pohyb z jednoho místa na druhé“; (2) se společným morfémem -i- s významem tematického vokálu sloves; (3) se společným morfémem -l- s významem minulého času; (4) se společným morfémem -i- s významem množného čísla:
| pře- pře-dat pře-jít pře-stavit atd. | -míst- míst-o míst-ečko u-míst-it | -i- barv-i-t čist-i-t brod-i-t | -l- pi-l smá-l uči-l | -i jel-i nesl-i zpíval-i |
Vidíme, že pro pět morfémů slova přemístili nalézáme pět druhů různých vztahů, podle nichž může každý z těchto morfémů kolem sebe seskupovat určitou řadu slov, jak je obecně známo a vykládáno.
Výchozí materiál pro ověření metody. Zpracovat celou slovní zásobu daného jazyka z hlediska morfematické struktury, vypracovat kombinační hierarchii morfémů od kombinací s vysokou, potom stále menší a menší pravděpodobností výskytu až k hranici kombinací s nulovou pravděpodobností — vůbec v jazyce nemyslitelných — předpokládá obrovské množství excerpovaného materiálu. Proto byl pro ověření navržené metody vybrán jen omezený úsek slovní zásoby z oblasti jazykovědných textů, jejichž lexikální materiál není zdaleka tak rozmanitý jako např. v beletrii.
V první etapě byla provedena excerpce 3600 slov souvislého ruského textu z učebnice A. S. Čikobavy „Vvedenije v jazykoznanije“. V excerpci materiálu se pokračuje, poněvadž teprve soubor asi 10 000—15 000 slov lze považovat za dostatečně vyčerpávající pro popis morfologické struktury odborného textu.
Co se týče zpracování materiálu, bylo možné podle navržené formulace uspořádat jej velmi přesně a přehledně do diagramů. Z 3600 slov první etapy excerpce bylo sestaveno — v souhlasu s počtem kořenových morfémů — 270 diagramů; každý kořenový morfém se všemi kombinacemi nástavbových morfémů, které se v excerpovaném materiálu vyskytly, tvoří jeden diagram.
V diagramech nejsou zahrnuta slova morfematicky nerozložitelná, která nemají schopnost spojovat se s jinými morfémy. Jsou to neohebná slova, jako např. příslovce typu ještě, většina spojek apod. Tvoří 17 % textu, takže v diagramech je podchyceno zhruba 3000 slov. Zvlášť byla vydělena též kompozita, 1 % textu, a vlastní jména, 1,5 % textu.
V diagramech je možno rychle se orientovat a dedukovat nejrůznější druhy vztahů a závislostí mezi morfémy. Ovšem stále vzrůstající množství excerpovaného materiálu si vyžádá strojní zpracování na děrných štítcích. Zdlouhavé manuální třídění bude nahrazeno mnohem efektivnějším tříděním mechanickým.
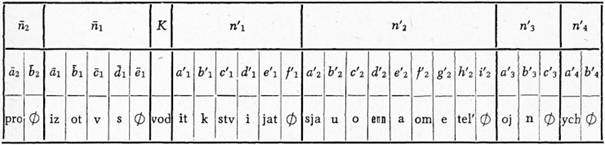
Vyčíslení podmíněných pravděpodobností. Při vyčíslování jsme vycházeli z předpokladu, že mezi sousedními elementy řeči — v našem případě mezi morfémy — existuje pravděpodobnostní závislost, že každý element nese určitou informaci o elementu bezprostředně následujícím. Především byla stanovena tzv. podmíněná pravděpodobnost přechodu morfémů, tj. podmíněná pravděpodobnost vztahů morfému a jeho pozice v slově, a potom vyčísleny hodnoty těchto podmíněných pravděpodobností u jednotlivých morfémů. Jako příklad si uvedeme pravděpodobnostní výpočet kombinací nástavbových morfémů [101]s kořenovým morfémem -vod-. Dolejší tabulka ukazuje poziční rozložení nástavbových morfémů vzhledem ke kořenovému morfému. V tabulce je zahrnuto 35 slov se společným kořenovým morfémem -vod-: proizvodstvo, proizvodstvennych, otvodit, vvodjatsja … atd.
Poziční rozložení nástavbových morfémů vzhledem ke kořenovému morfému -vod-
 Každou pozici s jejími variantami můžeme podle naší formulace vyjádřit jako množinu, tedy:
Každou pozici s jejími variantami můžeme podle naší formulace vyjádřit jako množinu, tedy:
| MK (n̄2) MK (n̄1) MK (n'1) MK (n'2) MK (n'3) MK (n'4) | {pro, ø} {iz, ot, v, s, ø} {it, k, stv, i, jat, ø} {sja, u, o, enn, a, om, e, tel’, ø} {oj, n, ø} {ych, ø} |
ø je symbol pro tzv. prázdnou množinu. Zde vyjadřuje vlastně prázdný člen množiny, tj. že v oné pozici nebyl žádný morfém.
Základní pravděpodobnostní vztah ukážeme např. na výpočtu pravděpodobnosti, že za kořenovým morfémem -vod- bude v pozici n'1 následovat varianta a'1, tj. nástavbový morfém -it:
![]()
tj. pravděpodobnost (za předpokladu, že v prvé pozici za kořenovým morfémem -vod- bude morfém -it) se rovná podílu počtu případů, kdy za kořenovým morfémem -vod- bude skutečně následovat morfém -it a celkového počtu výskytů kořenového morfému.
V našem případě se kořenový morfém -vod- vyskytl celkem 35×, z toho ve čtyřech případech po něm následoval v pozici n'1 nástavbový morfém -it. Dosadíme-li do hořejšího vzorce, dostaneme podíl 4 : 35 ≐ 0,11.
Totéž jsme provedli i u dalších variant — b'1, c'1, d'1, e'1, f'1, kde po zaokrouhlení na dvě desetinná místa jsme dostali hodnoty pravděpodobností:
| p (K | b'1) ≐ 0,03 p (K | c'1) ≐ 0,74 p (K | d'1) ≐ 0,09 p (K | e'1) ≐ 0,03 p (K | f'1) = 0 |
[102]V tomto souboru představoval kořenový morfém -vod- konstantu, pravděpodobnosti se měnily podle dosazovaných variant nástavbových morfémů v pozici n'1. Pro úplnost uvádíme i variantu f'1 — prázdnou množinu — ačkoli má v daném případě nulovou pravděpodobnost. Součet pravděpodobností všech nástavbových morfémů v určité pozici se totiž musí vždy rovnat jedné. Jak ukážeme dále, může nastat případ, kdy musíme brát v úvahu i hodnotu prázdné množiny.
Nyní budou postupně představovat konstantu varianty nástavbových morfémů v pozici n'1 a proměnné budou varianty nástavbových morfémů v pozici n'2:
| p (a'1 | a'2) ≐ 0,25 p (a'1 | i'2) ≐ 0,75 p (b'1 | b'2) = 1 p (c'1 | b'2) ≐ 0,04 p (c'1 | c'2) ≐ 0,12 p (c'1 | d'2) ≐ 0,15 | p (c'1 | e'2) ≐ 0,42 p (c'1 | f'2) ≐ 0,19 p (c'1 | g'2) ≐ 0,08 p (d'1 | h'2) = 1 p (e'1 | i'2) = 1 |
Tak po variantě a'1 v pozici n'2 následuje s pravděpodobností 0,25 varianta a'2 = nástavbový morfém -sja. S pravděpodobností 0,75 nebude však za variantou a'1 následovat již žádný morfém — prázdná množina ø bude zde mít tedy hodnotu 0,75. Další varianta — b'1 — má v pozici n'2 pouze jedinou variantu — b'2 — to znamená, že s pravděpodobností 1 (tj. ve všech případech) bude následovat nástavbový morfém -u. Nejrozmanitější rozložení pravděpodobností má varianta c'1. U varianty d'1 následuje zase ve všech případech jediný nástavbový morfém — -teľ. Za variantou e'1 nenásledoval v žádném případě už další morfém.
Tímto způsobem jsme ve výpočtu postupovali dále: probrali jsme ještě varianty pozice n'2 jako konstanty, k nim varianty pozice n'3 jako proměnné, potom varianty pozice n’3 jako konstanty a varianty pozice n'4 jako proměnné. Obdobně — pouze v opačném směru — jsme vypočítali pravděpodobnosti pro nástavbové morfémy předcházející kořenovému morfému. Nakonec jsme pak dostali soubor pravděpodobností pro všechny kombinace různých nástavbových morfémů s kořenovým morfémem -vod-, které se v excerpovaném materiálu vyskytly.
Celkem bylo propočteno 270 takových souborů sestavených pro 270 kořenových morfémů a na základě těchto výpočtů byla sestavena hierarchie morfémů z hlediska pravděpodobnosti jejich výskytu v té či oné pozici. Uváděné výsledky nemají ovšem vzhledem k omezenému rozsahu výchozího materiálu obecnou platnost, slouží jen jako ilustrace metody.
Pokusíme se osvětlit praktický význam zkoumání pravděpodobnosti výskytu určitého morfému v závislosti na jeho okolí na příkladu morfému -a-, který v pozici n'1 stojí na prvním místě frekvenčního pořadí — 6 % výskytu. Poněvadž pozici n'1 předcházejí vždy kořenové morfémy (které se ovšem vzájemně liší co do sémantického aspektu, to však stojí mimo předmět našeho zkoumání), soustředíme pozornost na pozici následující — n'2 — a na všechny její varianty, které se objeví po zvoleném morfému -a-. Ukázalo se, že největší podmíněnou pravděpodobnost — 0,53 — má první varianta, symbol ø, což znamená, že ve více než polovině zkoumaných případů představoval morfém -a koncovku.
Všimněme si dalších variant: jestliže vezmeme např. množinu variant pozice n'2, před kterými vystupuje morfém -a- v pozici n'1 jako tematický vokál u sloves, zjistíme, že s pravděpodobností téměř 1/2 bude následovat koncovka 3. os. sg. prvního typu časování -et, s pravděpodobností 1/5 koncovka infinitivu ť a koncovka příč. min. mask. -l. Pravděpodobst výskytu jiných koncovek je zanedbatelná.
V analýze můžeme pokračovat z perspektivy vertikální: zajímá nás např. vyčíslení homonymie koncovky -a. Opět vyčíslením podmíněných pravděpodobností zjistíme, že daleko největší pravděpodobnost výskytu má koncovka 2. sg. mask. zakončených v 1. sg. na souhlásku — hodnota [103]podmíněné pravděpodobnosti je 0,71; značně nižší je pravděpodobnost výskytu koncovky 1. sg. fem. typu sila — 0,13; pravděpodobnost ostatních koncovek (např. 2. sg. neuter, zakončených v 1. sg. na -o aj.) je tak nízká, že ji vůbec nemusíme brát v úvahu.
Takto jsme postupovali ve výpočtu i v dalších pozicích. Nejprve bylo vždy stanoveno frekvenční pořadí morfémů předcházejících zkoumaný morfém a frekvenční pořadí morfémů za ním následujících, takže jsme nakonec dostali soubor pravděpodobností charakterizujících zkoumaný morfém a jeho vztahy k jiným morfémům, jak jsme již ukázali při vyčíslení pravděpodobností u souborů seskupených kolem kořenového morfému -vod-.
Výhledy: Po skončení excerpce ruských jazykovědných textů pokusím se touto metodou analyzovat morfémovou strukturu češtiny — provést klasifikaci morfémů z hlediska pravděpodobnosti výskytu jednotlivých morfémů v různých pozicích, pravděpodobnosti výskytu jejich různých kombinací, sestavit pořadí morfémů podle jejich „míry kombinačních schopností“, tj. schopností spojovat se s jinými morfémy.
Takový výzkum je ovšem nutno provádět na reprezentativním souboru jazykového materiálu. Zatím máme k dispozici 70 000 slov excerpovaných z textů různých literárních žánrů (prózy, poezie, dramat, populárně vědecké literatury, politické a hospodářské literatury, denního tisku), nashromážděných pro výzkum akustiky české řeči z hlediska srozumitelnosti a slyšitelnosti, který se provádí pod vedením B. Borovičkové ve Fonetickém kabinetu při Ústavu pro jazyk český ČSAV. — Zároveň hodláme provést analýzu frekvenčního slovníku českého jazyka (Praha 1961). Porovnání výsledků analýzy obou souborů přinese jistě zajímavé poznatky.
Praktický význam tohoto zkoumání spočívá v tom, že bude umožněno sledovat z hledisek obou souborů libovolný aspekt gramatického systému, např. způsoby tvoření slov, problémy gramatické homonymie, prediktabilitu určitých morfémových kombinací atd. Kromě toho budou výsledky těchto výzkumů užitečné i pro jiné lingvistické disciplíny, jako např. typologii jazyků a strojový překlad.
R é s u m é
ОБ ОДНОМ МЕТОДЕ МОРФЕМНОГО АНАЛИЗА ОСНОВАННОМ НА ПРИМЕНЕНИИ ТЕОРИИ ВЕРОЯТНОСТЕЙ
Цель работы — показать возможности использования вероятностных методов для анализа языка представленном на примере анализа морфемного. Каждое слово выражено последовательностью морфем, которая всегда включает одну морфему корневую, а также определенное число морфем примыкающих к ней, которые мы называем здесь в совокупности морфемами надстроечными. Следовательно, мы исходим из принципа группировки слов учитывая их семантическое ядро. Такова характеристическая линия морфемного анализа. В итоге ее исследования получается определение продуктивности отдельных корневых морфем, установление вероятности появления определенных моделей комбинаций морфем итд. Однако мы можем проследить еще вторую линию, сказывающуюся в соответствии формы и функции надстроечных морфем, при помощи которой возможно установить вероятность появления определенных видов морфем в определенных позициях. Обе эти линии создают ряды взаимно перекрещивающихся морфем, причем эти соотношения возможно точно описать с количественной точки зрения. При исчислении мы исходили из предположения, что между соседними элементами речи — в нашем случае между морфемами — существует вероятностная зависи[104]мость, что каждый элемент несет определенную информацию о элементе непосредственно последующем. Прежде всего была определена т. наз. условная вероятность перехода морфем, т. е. условная вероятность отношений морфемы и ее позиции в слове, и потом исчислены значения этих условных вероятностей у отдельных морфем. На базе этих исчислений была составлена иерархия морфем с точки зрения вероятности их появления в той или другой позиции. Метод был проверен на материале выборки из русских текстов по языкознанию. Практическое значение настоящего исследования состоит в том, что на показательном комплекте языкового материала можно будет исследовать любую сторону грамматической системы, напр. способы словообразования, проблемы грамматической омонимии, предопределение известных комбинаций морфем итд.
[1] TCLP — Thesès — 1, 1929, 321; ta se opírá v podstatě o Baudouina de Courtenay.
[2] V. Skalička, O pojem morfému, sb. Matice slovenskej XVI—XVII, 1938—1939. — N. S. Trubetzkoy, Das morphonologische System der russischen Sprache, TCLP V2, 1937.
[3] J. Horecký, Morfématický sklad slovenského lexika, Jazykovedný sborník 1—2, 1946—1947, Turčanský Sv. Martin. — Týž, Slovotvorná sústava slovenčiny, Bratislava 1959. — M. Dokulil, K základním otázkám tvoření slov, sb. O vědeckém poznání soudobých jazyků, Praha 1958, 154—169. I. Poldauf, Tvoření slov, op. cit., 143—153.
[4] G. O. Vinokur, Zametki po russkomu slovoobrazovaniju, Izv. AN SSSR, otd. lit. i jaz. V, 1946. — A. I. Smirnickij, Sovremennyj russkij jazyk — Morfologija, Moskva 1952. — Týž, Leksikologija anglijskogo jazyka, Moskva 1956. — N. M. Šanskij, Osnovy slovoobrazovateľnogo analiza, Moskva 1953. — Týž, Očerki po russkomu slovoobrazovaniju i leksikologii, Moskva 1958. — K. A. Levkovskaja, Slovoobrazovanije, Moskva 1954. — I. I. Kovalyk, Pytanňa slovjanskoho imennykovoho slovotvoru, Lviv 1958. — Týž, Včenňa pro slovotvir, Lviv 1958.
[5] L. Bloomfield, Language, New York 1933.
[6] B. Bloch, G. L. Trager, Outline of Linguistic Analysis, Linguistic Society of America, Baltimore 1942.
[7] G. Gleason, An Introduction to Descriptive Linguistics, New York 1955.
[8] E. A. Nida, The Descriptive Analysis of Words — Morphology, Ann Arbor University of Michigan Press 1949.
[9] J. Ružička, Rozbor a triedenie gramatických tvarov, Jazykovedný sborník SAVU IV, 1950, 109.
[10] Pro obměněný morfém — variantu morfému — užívají západní strukturalisté termínu „allomorfém“.
[11] Poznamenáváme, že pro ilustraci teoretických úvah jsme volili příklady české; ověření metody bylo však prováděno na materiálu ruském. Proto tam, kde vycházíme z konkrétních excerpcí, ponecháváme příklady ruské.
Slovo a slovesnost, volume 23 (1962), number 2, pp. 94-104
Previous Jiří Levý: Izochronie taktů a izosylabismus jako činitelé básnického rytmu
Next Ladislav Nebeský: O jedné formalizaci větného rozboru
© 2011 – HTML 4.01 – CSS 2.1