
Převodní jazyk a teorie gramatiky
Petr Sgall
[Články]
Яазык-посредник и теория грамматики / La langue intermédiaire et la théorie de la grammaire
1. Soustavné uplatnění matematických metod, zejména těch, které jsou spojeny s rozvojem kybernetiky, pomáhá některým základním složkám jazykovědy získat novou teoretickou úroveň. Neznamená to, že by v budoucnu nebylo užitečné pokračovat ve výzkumu jazyka i bez matematického aparátu, ale úroveň abstrakce lingvistické teorie bude, jak se zdá, čím dál víc podmíněna právě mírou uplatnění matematických a formálně logických hledisek. V prvním období vývoje tzv. matematické lingvistiky šlo o aplikace matematických metod z hlediska matematiky ne zvlášť hluboké,[1] ale dnes už existuje i oblast teoretického výzkumu, která je předmětem jak lingvistiky, tak i matematiky samé, oblast, kde výzkum lingvistický má i přímý význam pro obohacení matematických poznatků.[2]
Touto oblastí je teorie gramatiky, která je z určitého hlediska shodná s algebraickou teorií automatů. Jak ukázaly práce N. Chomského,[3] gramatika může být chápána abstraktně jako řada pravidel (nověji podle K. Čulíka jako semialgoritmus),[4] vymezující gramaticky správně tvořené věty daného jazyka. Teorie automatů se zabývá v podstatě shodnou otázkou — chápe totiž automat, stroj abstraktně jako řadu pravidel vymezující ze všech možných posloupností daných symbolů právě ty, které mohou být tímto automatem zpracovány (řečeno lingvisticky — které jsou větami jeho jazyka). Algebra má prostředky k exaktnímu zachycení různých možností takového vymezení množiny „správně tvořených“ posloupností, jejich odlišení od množin jiných. Je tu možné jednak vymezení pro[115]cedurou generativní, tj. řadou pravidel, jejichž uplatnění vede k postupné generaci kteréhokoli prvku množiny, ale nikoli ke generaci prvku, který je mimo tuto množinu (v našem případě tedy jde o proceduru umožňující generovat, „odvodit“ kteroukoli správně tvořenou větu daného jazyka, a právě jen větu správně tvořenou); jednak může být vymezení dáno procedurou rekognoskativní (identifikační), tj. řadou pravidel umožňujících stanovit, zda daný prvek je prvkem množiny nebo nikoli (tedy procedura, při níž bychom vyšli z dané posloupnosti symbolů a zjistili o ní, zda je správně tvořenou větou jazyka nebo ne).
V obou případech tu ovšem máme na mysli procedury efektivní, které je možno provést konečným počtem kroků, bez nějakých vnějších zdrojů informace, tedy „mechanicky“. Procedury rekognoskativní i generativní existují pro množiny rekurzívní, jako je např. množina všech sudých čísel (ačkoli je nekonečná) nebo množina všech posloupností typu ab, abab, ababab atd. (kterou můžeme chápat jako množinu správně tvořených vět určitého jazyka, jehož abeceda má jen dva symboly a v němž jsou vyloučeny posloupnosti jako aab, aba atd.). Pro množiny rekurzívně spočetné, přečíslitelné (rekursivno perečislimyje množestva, recursively enumerable sets) existují však obecně jen procedury generativní, nikoli vždy i rekognoskativní;[5] k takovým množinám patří např. množina všech posloupností typu aa, abab, aabaab, abbabb atd. (tj. správně tvořené věty jazyka, který může mít v druhé polovině věty vždy jen posloupnost symbolů shodnou s tou, která je v její první polovině).
Pro přirozené jazyky zatím byly do určité míry algebraicky propracovány jen gramatiky generativní, a to především transformační (složené ze tří částí, z nichž první obsahuje pravidla frázová — v dosavadním zpracování obvykle založená na tzv. analýze podle bezprostředních složek — druhá pravidla transformační a třetí morfonologická).[5a] Podle některých náznaků je ostatně možno soudit, že se podaří i pro přirozené jazyky najít postup, který by vedl k vytvoření efektivní rekognoskativní procedury.[6]
Úloha gramatiky se ovšem neomezuje jen na odlišení těch posloupností daných jednotek (zvukových nebo grafických), které jsou správně tvořenými větami, od těch, které jimi nejsou. Každé z vymezených (správně tvořených) posloupností přiřazuje gramatika i určitou strukturu (při konstrukční homonymii dvě nebo více struktur různých). Základní úkoly gramatiky z hlediska algebraické lingvistiky jsou tedy v podstatě shodné jako úkoly gramatiky klasické. Liší se tu především požadavky kladené na její formu. To souvisí s úkoly, před které dnes lingvistiku staví praxe: nejde už jen o to, popsat jazykový systém tak, aby se z výsledku mohl poučit člověk, aby se mohl řídit pravidly, zvládnout systém cizího jazyka nebo systém spisovný ap.; dnes je třeba popsat jazykový systém tak, aby některé složky interpretace i formulace textu mohly být automatizovány, a jednou z nutných podmínek k tomu je značná míra formalizace popisu; práce s textem musí být v některých ze svých základních složek popsána v podobě efektivní procedury.
Algebraická lingvistika znamená nový stupeň ve vývoji jazykovědy; úspěchy algebraické teorie gramatiky vedou některé jazykovědce k tomu, že označují strukturní jazykovědu za součást kybernetiky.[7] Ať už toto tvrzení přijmeme nebo ne, nelze ovšem přehlížet, že lingvistika jako celek se nemůže omezit jen na matematický přístup a na matematické metody. Lingvistika a matematika se liší v cílech i v prostředcích;[8] nebylo by tedy na místě zaměňovat algebraickou (popř. mate[116]matickou) lingvistiku za celou jazykovědu. Naopak, výhodné je právě těsné spojení nových hledisek a postupů s výsledky klasické lingvistiky i s dalším uplatněním jejích prostředků tam, kde formalizace není — dosud — možná. Výsledky klasické lingvistiky je třeba uplatňovat i v teorii gramatiky, a to především v souvislosti s otázkou adekvátnosti dané nebo nově tvořené gramatiky pro určitý jazyk; dosavadní gramatiky byly však formulovány tak, že aplikace jejich pravidel vyžaduje využití intuice mluvčího, a to se právě ve formální, algebraické podobě gramatiky odstraňuje. Lingvistika tím zpřesňuje své metody a zbavuje se bludných kruhů.[9] Vedle toho získává i možnost vlastního matematického zpracování takových otázek, jako je ekvivalence jednotlivých typů gramatik (mluví se o slabé ekvivalenci dvou gramatik, vymezují-li tytéž množiny správně tvořených vět; bez soustavného zpracování zůstává zatím tzv. silná ekvivalence, při níž různé gramatiky nejen vymezují tytéž množiny vět, ale také přiřazují těmto větám shodné struktury), jejich jednoduchost, otázky rozhodnutelnosti aj.[10]
Těsné spojení teorie gramatiky s teorií automatů vede tedy k vyšší exaktnosti, úplnosti i úspornosti popisu jazykového systému. Pro praxi to přináší možnost automatizace některých složek práce s textem, pro teorii vyšší úroveň abstrakce a možnost přímého využití výsledků soudobé metodologie věd.
2. Možnost automatizace je tedy díky těmto novým objevům alespoň v oblasti gramatické stavby jazyka daleko reálnější než dříve. V přípravě strojového překladu, který je relativně aktuálním[11] oborem automatického zpracování textu (v přirozeném jazyce), se však výsledků algebraické teorie gramatiky zatím soustavně nevyužívá. Pracuje se tu obvykle se systémy založenými na frázových nekontextových gramatikách nebo na gramatikách s nimi ekvivalentních, ačkoli takové gramatiky pro popis přirozených jazyků nejsou výhodné.
To neznamená, že by příprava strojového překladu pro teorii nic nepřinášela; naopak, je známo, že výzkum strojového překladu vedl k významným novým objevům jak v oblasti přirozených jazyků — uveďme jen automatizaci gramatické analýzy na základě kombinatorických i kvantitativních vztahů v textu, kterou navrhl N. D. Andrejev a také P. L. Garvin, nebo Yngveho hypotézu o hloubce syntaktických struktur,[12] tak i v oblasti umělých formalizovaných systémů, kde především A. G. Oettinger přímo přispěl ke zpracování některých aspektů vztahů mezi formálními jazyky.[13] V přípravě strojového překladu se však stále do značné míry uplatňuje postup „pokusů a omylů“, shromažďování dílčích zlepšení na základě postupně získávaných zkušeností, bez soustavné teorie. Něco podobného je ovšem zatím nutné především v otázkách sémantiky, kde nemáme abstraktní teorii na úrovni srovnatelné s tou, které bylo dosaženo v teorii gramatiky. Ale [117]právě sémantické otázky jsou pro překlad podstatné; nevystačíme tu s popisem jazykového systému, úkolem tu je právě jednotky jednoho jazyka přiřadit jednotkám jazyka jiného tak, aby význam (obsah sdělení) zůstal neměnný.[14] Tento empirický výzkum sémantických otázek pro účely strojového překladu bude mít jistě svůj význam pro další rozvoj teoretické jazykovědy, v níž se nyní základní otázky sémantiky začínají dostávat do popředí; vždyť má-li mít strojový překlad úspěch v širším měřítku, je nutné abstraktní zpracování sémantiky s určitou mírou formalizace.
Užívá-li se dnes pro strojový překlad většinou uvedených gramatických systémů, je to jistě do značné míry podmíněno i tím, že pro praktické uplatnění mají své výhody. Tak např. pro analýzu ve strojovém překladu je nutná procedura rekognoskativního typu (která by dané větě z textu přiřadila jednu nebo více struktur). Je tedy pochopitelné, že se tu nedá bez dalšího prostě užít gramatiky typu, pro který rekognoskativní procedura zatím nebyla nalezena, jako je tomu např. u gramatik transformačních.
3. Některá z pracovišť strojového překladu nepřipravují algoritmy pro tzv. binární překlady (z jednoho jazyka do druhého), nýbrž konstruují pro jednotlivé jazyky jen algoritmy analýzy a syntézy, jejichž společným druhým pólem je převodní jazyk (jazyk-posrednik, intermediate language, Interlingua). Tato myšlenka, jejímž hlavním cílem je snížení počtu nutných algoritmů překladu, vznikla sice před lety v USA, je však prakticky uplatňována zejména v Sovětském svazu, zčásti také v Anglii, v NDR a u nás. I to má, jak se zdá, svou souvislost s praktickými podmínkami a cíli jednotlivých výzkumných skupin: v USA se soustřeďují především na přípravu překladu z ruštiny a jiných jazyků do angličtiny, kdežto v SSSR se práce (zejm. na leningradské universitě) zaměřuje na mnohojazyčný systém automatického překladu.
Přístupy k vytvoření převodního jazyka jsou značně různé a většinou mají vážné nedostatky.[15] Je zřejmé, že by nebylo účelné užít v této úloze některý z přirozených jazyků; vznikla by tu v nejlepším případě situace podobná té, kterou známe z nepřímých překladů dosavadních: vzhledem k složitému asymetrickému dualismu (homonymii a synonymii) přirozených jazyků se při každém převedení obsahu sdělení z jedné jazykové formy do druhé sdělná hodnota textu sníží. Překlad prostřednictvím přirozeného jazyka v této úloze by tedy měl nižší kvalitu než překlad binární. Jako druhý extrém jsou obvykle odmítány pokusy (známé zejm. z britské cambridgeské skupiny) o vytvoření formalizovaného převodního jazyka, založeného na prostředcích predikátového kalkulu ap. Sestavovat algoritmy pro překlad z přirozených jazyků do tohoto formalizovaného jazyka by totiž pravděpodobně bylo daleko obtížnější než připravovat algoritmy binární, a tak by snížení počtu algoritmů ztratilo svou praktickou cenu.[16]
Aby byl převodní jazyk výhodný, tzn. aby sestavování algoritmů analýzy a syntézy pro něj bylo poměrně jednoduché, k tomu musí splňovat určité podmínky co do vlastností své struktury. Z hlediska sémantického, které je tu základní, popř. z hlediska vztahu formy a funkce v jazyce, je možno formulovat je asi takto: Systém převodního jazyka by se měl od přirozených jazyků lišit především tím, že by v něm byl odstraněn asymetrický dualismus, že by tedy jeho jednotky formální (symboly) byly v jedno-jednoznačném vztahu k jednotkám sémantickým. Dokud neexistuje [118]ucelená teorie sémantiky přirozených jazyků, je ovšem obtížné vymezit tyto sémantické jednotky jinak než právě jako jednotky, které při překladu obecně zůstávají invariantní (srov. výš). Zatím je tu tedy nutný empirický postup, ale právě výzkum problematiky překladu by mohl mít rozhodující význam pro vytvoření postulované teorie sémantiky, podaří-li se spojit jeho výsledky s požadavky deduktivních teorií založených na postupech algebraických.
Naproti tomu by měl mít převodní jazyk co nejvíce společného s přirozenými jazyky v ostatních ohledech. Neměl by se od nich lišit v takových věcech, jako je anafora, deixe, určité ustálené typy elips, základní syntaktické vztahy jako determinace; v těchto věcech by se tedy převodní jazyk podstatně lišil od umělých jazyků formálních. Aby nebyl příliš odlišný od přirozených jazyků, měl by do určité míry zahrnovat všechny jejich sémantické prvky. Podle názoru I. A. Meľčuka by měl být převodní jazyk konstruován jako určitý logický součet prvků všech přirozených jazyků, které by do systému překladu byly začleněny.[17] Takový přístup je reálný, pokud jde o slovník převodního jazyka, kde je ostatně uplatňován zejm. leningradskou skupinou, vedenou N. D. Andrejevem. V gramatice by však měl značné nevýhody, především proto, že jednotlivé morfologické prvky (číslo, čas, vid ap.) by byly v textech převodního jazyka zastoupeny různě — podle toho, zda jsou gramatikalizovány, tedy obligatorní, v jazyce překládaného textu, a algoritmy syntézy jednotlivých jazyků by pak musely počítat s nejrůznějšími možnostmi; např. syntéza angličtiny by co do určenosti substantiv vycházela z jiných podmínek při překladu z němčiny (kde by pak musely v algoritmu být jen upraveny ty případy, v kterých se užívání členů v němčině od angličtiny liší), než při překladu z jazyka, který takovou gramatickou kategorii nemá. Musely by tedy pro syntézu být připraveny buď algoritmy značně složité (které by velkou část morfologie budovaly na základě kontextových kritérií), nebo algoritmy různé podle toho, z jakého jazyka se daný text překládá. V obou případech by tedy tento postup, který pro lingvistickou teorii jistě i tak může přinést mnoho závažných podnětů, přece jen vedl ke ztrátě hlavní výhody získané zavedením převodního jazyka.
Z toho vyplývá, že převodní jazyk má mít svou vlastní gramatiku, která by zachycovala víc než jen členění slov do větných dvojic. Jak má být vybudována tato gramatika, aby příprava algoritmů překladu z přirozených jazyků do převodního a naopak byla co nejjednodušší? Důležité je tu jistě především hledisko zastávané Andrejevem: je třeba stanovit inkongruenci jednotlivých přirozených jazyků zařazených do systému překladu a odhadnout, jakou závažnost bude mít který z nich v tomto systému, a podle toho pak vybrat ty gramatické prvky, které by zajistily optimální strukturu převodního jazyka vzhledem k danému „poli jazyků“.[18] Nebylo by však správné klást při tom různé gramatické prvky na jednu rovinu. Je třeba postupovat tak, aby jednotky převodního jazyka měly co nejblíže k jednotkám sémantickým. Je tedy na místě vycházet ne z takových jednotek, jako jsou pády (protože, jak známo, mezi pády a jejich funkcemi jsou v přirozených jazycích složité vztahy spojené s homonymií a synonymií), ale z jednotek tzv. morfologického významosloví, jehož zpracování ovšem bude třeba kriticky revidovat z nových hledisek. A podobně i v syntaxi je třeba brát v úvahu vztah funkce a formy, který tu je v přirozených jazycích dost složitý a který byl zatím jen málo zpracováván.[19] Bude vhodné uvést tu do kontextu algebraické lingvistiky i ty výsledky klasické jazykovědy, které nebyly dosud soustavně zpracovány v plné šíři, [119]nýbrž spíše jen naznačeny jednotlivými vědci, jako zejm. významová výstavba věty a kontextové členění výpovědi.[20]
Z tohoto hlediska je třeba prověřit možnost soustavnějšího využití výsledků algebraické teorie gramatiky při konstrukci gramatiky převodního jazyka. Chomského teorii tu nelze přímo použít v její dnešní podobě především ze dvou příčin: Za prvé je vytvářena jako teorie jednoho jazyka, vcelku bez zřetele ke vztahům mezi systémy různých jazyků, které jsou tu rozhodující. Za druhé nezpracovává soustavně vztahy funkce a formy uvnitř gramatiky (alespoň ne explicitně), rozlišuje sice několik rovin jazykového systému, ale nepovažuje za dvě různé roviny vlastní syntaktické vztahy a způsoby jejich vyjádření v daném jazyce: např. otázky slovosledu jsou v ní zpracovávány týmiž pravidly jako vztahy větně členské, což je možné u jazyků se slovosledem do značné míry gramatikalizovaným, jako je angličtina, ale přinejmenším nejasné u jazyků s volným slovosledem.[20a] Jak oba tyto body souvisí, ukazuje především Curryho kritika transformační gramatiky, upozorňující na potřebu rozlišovat při analýze přirozených jazyků rovinu vlastních funkcí jazykových jednotek (Curryho tectogrammatics), v které se různé jazyky do značné míry shodují, od roviny prostředků, kterými jednotlivé jazyky — značně různě — tyto funkce vyjadřují (phenogrammatics).[21] Hranice mezi těmito rovinami však není jasná; vztah formy a funkce v gramatické stavbě přirozených jazyků je stupňovitý a nelze předem stanovit jasné měřítko, podle něhož by byly jazykové jednotky do těchto dvou rovin utříděny.
Vztah mezi sémantikou a gramatikou je nejasný i z jiného hlediska: Neexistuje totiž jednoznačné kritérium, podle něhož by bylo možno vést hranici mezi větami gramaticky nesprávnými a větami, které jsou sice správně tvořeny, ale přesto nejsou smysluplné (tj. vyhovují pravidlům gramatickým, ale nikoli sémantickým). Na tento bod se soustřeďuje velká část prací, které kritizují Chomského teorie. H. Putnam říká přímo, že otázka, kde vidět hranice mezi sémantikou a gramatikou, je věcí vhodnosti, nikoli vlastním teoretickým problémem.[22] Jisté je, že existují věty, které jsou v určitém smyslu na pokraji gramatické správnosti (např. věta Sincerity admires John může být za určitých okolností chápána jako gramaticky správná; v té věci — nikoli v celkovém zaměření — je třeba souhlasi i s P. S. Rayem a jinými kritiky transformační gramatiky).[23] Ostatně Chomsky a jeho spolupracovníci v novějších pracích stupňovitost gramatické správnosti nejen uznávají, ale i soustavně zpracovávají.[24]
Důležité je, že pro strojový překlad nepotřebujeme nutně úplnou gramatiku zpracovávaných jazyků, která by vymezovala všechny gramaticky správně tvořené věty daného jazyka a jen tyto věty. Vždyť pro analýzu nám stačí gramatika, která by každé větě v textu přiřadila jednu nebo několik struktur, tzn. vyhovuje tu i gramatika „širší“, která by jako správně tvořené věty daného jazyka určila i ně[120]které věty pravidlům jeho úplné gramatiky neodpovídající.[25] Nechceme-li mít v algoritmech překladu zároveň kontrolu správnosti vstupního textu (což by bylo pro počátek zbytečně náročné), pak můžeme předpokládat, že se nesprávně tvořené věty v textu nevyskytnou. A obdobně pro syntézu přeloženého textu není třeba pracovat s úplnou gramatikou výstupního jazyka; postačí tu gramatika „užší“, která neumožňuje odvodit všechny jeho věty (zejm. ne všechny stylistické varianty téhož sdělení; např. pro překlad do češtiny není třeba brát v úvahu kolísání jako dni - dny, v úřadu - v úřadě, lodi - lodě, musejí - musí — vystačíme tu vždy s jednou variantou). Základní úlohou gramatiky v procesu překladu není odlišovat správně tvořené věty od nesprávných, ale přiřazovat správně tvořeným větám struktury; samo vymezení vět správně tvořených se tedy nemusí plně krýt s vymezením vyžadovaným pro úplný popis jazyka. Z toho nijak nevyplývá, že by výzkum jazyka pro účely strojového překladu nevedl k úplnému popisu jeho systému: to, co můžeme zanedbat v syntéze, budeme potřebovat v analýze, a naopak, pokud ovšem jde o jevy, jejichž výskyt v překládaných textech není předem vyloučen.
Pro gramatiku převodního jazyka z toho vyplývá, že nemusí přímo zachycovat všechny složité vztahy obvyklé v gramatikách přirozených jazyků — jednak proto, že patří spíše do roviny „fenogramatické“ než „tektogramatické“ (např. transformace týkající se slovosledu), a jednak proto, že „širší“ gramatika i zde postačí, nebudeme-li od převodního jazyka žádat, aby umožnil automatické zjištění chyb, k nimž popř. došlo při analýze; můžeme tedy odhlédnout od kontextových omezení kombinací jednotlivých slov (např. od omezení, které nedovoluje spojovat jména neživých předmětů a abstrakta jako podmět s aktivními tvary sloves označujících lidské činnosti, a tedy tvořit věty jako Sincerity admires John). Podaří-li se sestavit pro převodní jazyk frázovou nekontextovou gramatiku, tj. gramatiku s pravidly typu A → X, kde A je jediný symbol, kdežto X je obecně řetěz symbolů, a → čteme „přepiš“ nebo „změň na“, pak získáme mnoho výhod. Sestavit algoritmy překladu do takového převodního jazyka a z něho bude obecně snazší, než kdyby měl gramatiku kontextovou nebo transformační. Sestavení algoritmů překladu mezi dvěma takovými jazyky by snad mohlo být i automatické.[26] Přirozené jazyky mají ovšem strukturu složitější, ale při vhodném členění algoritmů analýzy a syntézy by bylo možné na tomto základě dosáhnout cíle určeného pro převodní jazyk: sestavení algoritmu pro překlad z přirozeného jazyka do převodního nebo naopak by bylo jednodušší než sestavení algoritmů pro některou dvojici přirozených jazyků, a přitom by se počet potřebných algoritmů vytvořením převodního jazyka značně snížil.
4. S přihlédnutím k uvedeným měřítkům a podmínkám je možno sestavit předběžnou generativní gramatiku převodního jazyka jako frázovou nekontextovou gramatiku, která vytváří terminální řetěz v poněkud jiné podobě, než je obvyklé u Chomského, totiž v podobě blízké Łukasiewiczově bezzávorkové notaci;[27] jinak tu používáme základních konvencí obdobně jako u Chomského, jen [121]znak „-“ má poněkud jinou funkci. Gramatika připouští i řadu vět, které se v praxi nemohou vyskytnout spíše z příčin daných systémy přirozených jazyků než jejich sémantikou; je to tedy gramatika „širší“. Nejsou zpracovány některé závažné otázky, které potřebují speciální prozkoumání (zejm. zájmena vztažná, anaforická aj.).
Předběžná podoba gramatiky převodního jazyka, kterou tu předkládáme k posouzení, vznikla na základě zkušeností z práce na strojovém překladu na Karlově universitě, kde byly některé složky převodního jazyka prověřeny pracovníky různých filologických oborů na základě struktur několika evropských jazyků. Prvků tohoto převodního jazyka bylo použito i v algoritmech překladu kratšího elektrotechnického textu z angličtiny do češtiny, připravených v rámci spolupráce s Výzkumným ústavem matematických strojů v Praze.
a) Syntaktická pravidla:

Pro větší přehlednost uvádíme, že Ra označuje větný člen, který za ním následuje, jako činitele (agens), Rp jako patiens, Ri jako nepřímý předmět, popř. vůbec druhý předmět u slovesa (Vbitr) Rd jako determinans jiného druhu; symboly s Q označují koordinaci (kopulativní, gra[122]dační, disjunktivní, adverzativní a „kontrastní“, tj. slabě adverzativní) a apozici; symbol indir v prav. 11. označuje nepřímou otázku. — Ze symbolů spojených svorkou je možno vybrat kterýkoli, symboly nebo posloupnosti v závorkách je možno vynechat. Prav. 7.—9. jsou rekurzívní; jsou to schémata pravidel, kde X je za Věta, Enunc, Interr, Vok, VP, NP s indexem, Y je za Enunc, Interr, Vok, VP, NP s indexem a Z je za Věta, VP, NP s indexem. Znak „-“ připojuje k samostatnému (levému) symbolu další (nesamostatné) „sufixální“ tvaroslovné morfémy zprava, kdežto znak „+“ spojuje samostatné symboly, které v terminálním řetězu lze chápat jako symboly bezzávorkové notace (R a Q s indexy tu slouží jako funktory, ostatní jako argumenty), přičemž funktory jsou dvouargumentové, neoznačuje-li horní index u Q vyšší počet argumentů; zároveň s druhem syntaktického vztahu je tu označen (u funktorů s R) i směr závislosti: v této podobě převodního jazyka platí pravidlo „regens post rectum“. Tak např. vynecháme-li sufixální symboly a znak „+“, můžeme posloupnost Ra Rd A S Rp S Vtr interpretovat asi takto: atributivní adjektivum s řídícím substantivem ve funkci činitele (část podmětová) — objektové substantivum s řídícím přechodným slovesem (část přísudková, kterou tu vždy považujeme za řídící).[28] To je ovšem jen hrubá pomůcka; nejde přitom o slovní druhy morfologické nebo syntaktické, nýbrž sémantické (označení předmětu, děje, vlastnosti ap.),[29] tedy např. rychlost je v tomto systému tvarem adjektiva, fungování tvarem nepřechodného slovesa, elektronový tvarem substantiva ap.; zda se ve „fenogramatice“ jednotlivých jazyků tyto prvky vyjadřují morfologicky, slovotvorně nebo jinak, to pro převodní jazyk není důležité.
b) Morfologická pravidla:
12. S → Subst-Num-Def (-neg)
13. Vindex → Verbindex-(Num-Def-) (neg-) Asp-Mod-Temp
14. A → Adj-(Num-Def-) Komp(-neg)
15. A → Adv-(Num-Def) (-neg)
16. Modal → enunc, exkl, dezid, imper
17. Num → sg, pl
18. Def → noc, kont, poses, indef[30]
19. Komp → poz, komp, sup, elat
20. Asp → mom, ingr, fin, rezult, stat, dur, iter
21. Mod → ind, opt, deb, vol, posib, perm, hort, fak
22. Temp → préz, prét, fut, gnóm
23. Rel → simult, prec, sukc
24. Det → gener, instr, kauz, kond, pos, lok1 — lok36, temp1 — temp7 atd. (Sem patří řada dalších významů adverbiálních a přívlastkových, jako nesk. podm., důsledek, účel, způsob, míra, omezení, vlastnost …)
c) Lexikální pravidla:
25. Subst → kov, elektron, vodič, izolant, polovodič, látka, vazba, on, já …
26. Adj → přítomný, volný pevný, dobrý, meziatomární, tzv., mnoho, všechen …
27. Adv → vně, doma, včera, loni …
28. Verbimpers → prší, mrzne …
29. Verbintr → pohybovat se, vyskytovat se, jít, existovat …
[123]30. Verbtr → charakterizovat, mít, vázat, působit, zabývat se …
31. Verbbitr → dát, vzít, učit …
Česká slova tu ovšem uvádíme jen náhradou za překladová pravidla, podobně jako výše terminální morfologické symboly (kde sama zkratka, i když je snad srozumitelná, málo říká o tom, které všechny prvky jednotlivých jazyků budou do převodního jazyka takto překládány); upozorňujeme jen, že obecnější významy modálních a fázových sloves mají být zahrnuty v kategoriích označených zde jako Mod a Asp. Místo dalších vysvětlivek uvedeme raději (v tab. 1 a 2) příklady derivace vět podle této gramatiky; uvádíme je v podobě grafů — stromů (číslice vlevo označují pravidla použitá v dané etapě derivace), jen poslední dva řádky jsou vždy — z technických důvodů — rozepsány jako řetězy.
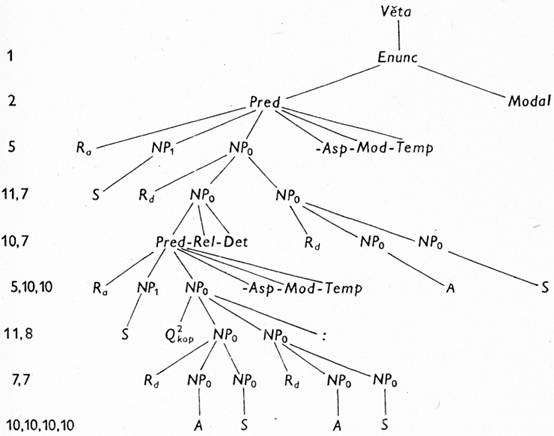
| 12—15 | Ra + Subst-Num-Def + Rd + Ra + Subst-Num-Def + Q2kop + Rd + Adj-Komp + Subst-Num-Def-neg + Rd + Adj-Komp + Subst-Num-Def-neg:-Asp-Mod-Temp-Rel-Det + Rd + Adj-Komp + Subst-Num-Def-Asp-Mod-Temp-Modal |
| 16—31 | Ra + polovodič-pl-noc + Rd + Ra + látka-pl-indef + Q2kop + Rd + dobrý-poz + vodič-pl-indef-neg + Rd + dobrý-poz + izolant-pl-indef-neg:-dur-ind-gnóm-simult-gener + Rd + pevný-poz + látka-pl-indef-dur-ind-gnóm-enunc |
Tab. 1
Věta zní v anglickém originále: Semiconductors are solid materials which are neither good conductors nor good insulators (R. P. Shea, Principles of transistor circuits, N. York 1953, s. 1), v překladu: Polovodiče jsou pevné látky, které nejsou ani dobré vodiče, ani dobré izolanty.
[124]
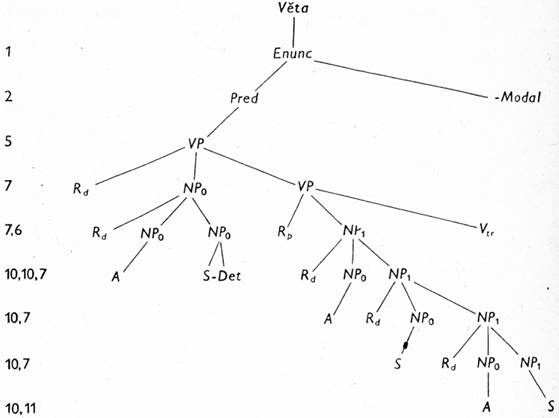
| 12—15 | Rd + Rd + Adj-Komp + Subst-Num-Def-Det + Rp + Rd + Adj-Komp + Rd + Subst-Num-Def + Rd + Adv + Subst-Num-Def + Verbtr-Asp-Mod-Temp-Modal |
| 16—31 | Rd + Rd + meziatomární-poz + vazba-pl-noc-lok3 + Rp + Rd + všechen-poz + Rd + on-pl-kont + Rd + vně + elektron-pl-poses + vázat-dur-ind-gnóm-enunc |
Таb. 2
Věta zní anglicky: All their outer electrons are tied up in interatomic bonds (R. P. Shea, l. c.), v překladu: Všechny jejich (izolantů) vnější elektrony jsou vázány v meziatomárních vazbách.
5. Jak by asi měly být učleněny jednotlivé etapy překladu spojeného s převodním jazykem tohoto typu? V analýze bude třeba především řešit homonymii v rovině morfologické; dále v rovině transformací bude třeba řešit transformace obligatorní a převést transformované fráze do základní podoby, snadno vymezitelné frázovou gramatikou: např. české příklonky se tu přičlení k slovesu, podobně se spojí v jednu souvislou frázi složené slovesné tvary anglické nebo německé, které jsou často transformacemi rozděleny na různá místa ve větě; to se týká pravidel řazení. Ostatní transformační pravidla, fakultativní, je možno pro účely překladu rozdělit do tří skupin: pravidla, jejichž výběr je dán kontextovými měřítky mezivětnými, zejm. kontextovým členěním výpovědi, za druhé pravidla s výběrem daným sémanticky (transformace otázky, imperativu ap.), za třetí pravidla kompoziční (koordinace, vedlejší věty a nominalizace). První z těchto skupin je třeba v analýze vyřešit a převést na kategorie použitelné ve frázové gramatice; zatím je zřejmá možnost takového řešení aspoň u některých prostředků kontextového členění, o kterých psal už Mathesius. Považujeme-li angl. pasívum [125]v základě za prostředek k vyjádření toho, že patiens patří k východisku výpovědi, popř. že činitel patří k jejímu jádru, pak je třeba v analýze nahradit prvky jako aktivum — pasívum prvky kontextového členění. Zdá se v dané etapě nejvhodnější — podle návrhu P. Nováka — pracovat se slovosledem jako s prostředkem kontextového členění v převodním jazyce v podstatě tak, že ponecháme pořádek sémantémů týž, jaký byl v jazyce vstupním (po odstranění transformací obligatorních, pravidel řazení, popř. po jednotlivých dalších úpravách). Počítáme-li jen s vědeckotechnickými texty (s objektivním pořadem), můžeme se v převodním jazyce obejít bez takových prostředků kontextového členění, jako je (pro angličtinu) vztah mezi aktivní a pasívní vazbou; stylistickou platnost pasíva, která je v různých jazycích značně různá, nelze v nynější etapě strojového překladu využít. Převodní jazyk tedy nebude mít rozdíl mezi aktivem a pasívem; po analýze se bude aktivní věta lišit od pasívní jen svým slovosledem. Slovosled je pak v podstatě dán pořadím sémantémů v překládané výpovědi vstupního jazyka, nikoli pravidly generativní gramatiky. Gramatika uvedená v odst. 4 neurčuje proto slovosled. Pořadí symbolů v terminálním řetězu generovaném podle této gramatiky (kromě koordinace a apozice) je vymezeno syntakticky, pravidlem „regens post rectum“, ale naprosto není shodné s pořadím slov v textu, ve výpovědi. Slovosled výpovědi může být v převodním jazyce vyznačen např. indexy u jednotlivých symbolů; bez nich jsme v odst. 4 měli posloupnosti symbolů převodního jazyka jen jako věty, jednotky systému, nikoli textu.[31]
Druhá skupina transformací (otázka, imperativ ap.) bude v analýze převedena na vyjádření prostředky frázové gramatiky. Vypracuje se tedy např. pro otázku (místo anglického vyjádření slovosledného) zvláštní příznak, platný pro celou větu (sr. naše pravidlo 3), pro rozkaz však jen zvláštní modalita, sr. prav. 16 (protože imperativní věta může být koordinována s oznamovací ap.). Třetí skupina, týkající se zejm. koordinace a souvětí, musí být podobně převedena na vyjádření frázové; u koordinace a apozice se to dá provést pomocí zvláštního typu funktorů — našich Qi — s různým počtem argumentů,[32] u podřadných souvětí pak tím, že závislou větu považujeme za větný člen.[33] V našem převodním jazyce tedy není rozdíl mezi spojeními jako takto získaný výsledek a výsledek, který byl takto získán nebo když autor zjistil, že je nákladné tak postupovat … a po autorově zjištění nákladnosti takového postupu … Jazyky se ve využití takovýchto nominalizačních prostředků značně liší a bylo by zbytečné, často i nemožné překládat je doslovně.
Vedle těchto úprav týkajících se transformací bude ovšem nutné v analýze využít relevantních rysů syntaktického kontextu a vypracovat prvky obligatorních morfologických kategorií převodního jazyka. Syntaktické vztahy vstupního jazyka budou převáděny na vztahy převodního jazyka nejen podle jevů z formálně syntaktické roviny (přesněji řečeno, nejen podle derivovaného strukturního ukazatele věty),[34] nýbrž z celé derivační historie věty, včetně transformací. Tak např. jako činitel bude v převodním jazyce označen nejen podmět aktivního slovesa, ale i určení činitele u slovesa pasívního atd.
[126]Vzhledem k tomu, že slovosled bude v textu převodního jazyka označen (na rozdíl od vět generovaných gramatikou v odst. 4.), bude patrně výhodnější označovat větně členské vztahy v podobě tzv. tektoglyfů, tzn. místo našich symbolů Ra, Rp, Ri, Rd označit u každého sémantému číslo řídícího slova a vedle toho druh větně členské závislosti (Ag, Pat, Pat2, D). Z tohoto způsobu záznamu (dá se mechanickou procedurou získat ze zápisu generovaného naší gramatikou) bude pak syntézou vytvořen odpovídající text ve výstupním jazyce. Pro syntézu bude třeba formulovat transformační (a frázová kontextová) pravidla výstupního jazyka, a to vcelku obdobně jako pro jeho generativní gramatiku, ale doplněná ještě o pravidla rozhodování pro některé fakultativní transformace, jako např. pro různé typy nominalizací (v. uved. příklady) nebo pro výběr mezi konstrukcí aktivní a pasívní ap. Tato pravidla budou muset být sestavena tak, aby jejich uplatnění nevyžadovalo jinou informaci než tu, která může být získána z údajů o morfologické a lexikální platnosti i o slovních druzích daných slov ve výpovědi, o jejich syntaktických funkcích (včetně údajů o slovech rozvíjejících a rozvíjených) a konečně o mezivětných vztazích;[35] tedy zejm. sémantické údaje (lexikální i morfologické) musejí být v textu převodního jazyka obsaženy a v pravidlech využity.
6. Zdá se tedy, že práce na převodním jazyce může mít i značný význam obecně lingvistický, zejm. že může být důležitá pro zkoumání sémantiky přirozených jazyků z nových metodologických východisek. Je jistě zřejmé, že první jednoduchá podoba gramatiky, výše uvedená, patrně nevyhoví všem hlediskům; je jen prvním krůčkem, jen předběžnou formulací některých základních pravidel. Ale právě výzkum různých jazyků, který je pro přípravu strojového překladu nutný, přinesl by tu určitou soustavu vystihující do značné míry vlastnosti přirozených jazyků i jejich sémantiky a přitom formálně zachytitelnou. Sám tento výzkum by ostatně mohl být zčásti automatizován.
Takový výzkum by přinesl odlišení „fenogramatických“ prvků jednotlivých jazyků od „tektogramatické“ struktury, která má rysy v základě společné snad všem jazykům; ty by právě gramatika převodního jazyka měla zachytit. Při jejich předběžném výběru jsme vycházeli z Revzinova vymezení syntaktických vztahů (v. pozn. 19); náš vztah Ra odpovídá — v hlavní větě — jeho predikaci, Rp a Ri jeho neregulární konfiguraci (tj. nutnému doplnění), Ra mimo hlavní větu (tedy vždy, kdykoli jeho řídící slovo závisí na některém slově jiném) a Rd — regulární konfiguraci. Kromě toho jsme se snažili celou tzv. syntaktickou derivaci[36] jako složku spíše „fenogramatickou“ (a tedy značně se lišící jazyk od jazyka) z převodního jazyka vyloučit, tzn. slovnědruhovou příslušnost slov nespojovat příliš těsně s jejich syntaktickou platností. Bylo by možné nespojovat tyto dvě stránky vůbec, tj. v generativní gramatice slovními druhy vůbec neoperovat; třídy slov by pak sloužily jen jako podklad pro kontextové řešení homonymie a synonymie v procesu překladu, jak je tomu v uved. práci B. M. Lejkinové (v. pozn. 29). Ale zdá se, že bude prakticky výhodnější i teoreticky plodnější pracovat tu s Kuryłowiczovými pojmy „primární a sekundární funkce“: např. primární syntaktickou funkcí pojmenování děje (slovesného sémantému) je funkce predikátu, ale vedle toho může mít i funkci činitele aj., kdežto u sémantému substantivního je tomu naopak. Z toho pak vyplývá možnost některých omezení, s nimiž naše gramatika počítá [127]a která jsou u různých slovních druhů různá. Teprve po prozkoumání mnoha jazyků bude možno z těchto jen nadhozených souvislostí vyvozovat obecné závěry.
Má-li být v převodním jazyku odstraněn asymetrický dualismus formy a funkce, pak je nutné, aby forma výpovědi v něm zahrnovala explicitní popis jeho struktury, tj. derivační historie; tomu, jak se zatím zdá, odpovídá nejlépe zápis, který obsahuje nejen označení jednotlivých morfémů, ale i syntaktických funkcí. Od takové formy zápisu bude také jednodušší přechod k informačnímu jazyku;[37] to předpokládá řešení řady dosud nejasných otázek, spjatých se sémantikou.
Nechceme vzbuzovat dojem, že metody algebraické lingvistiky, které dosáhly značných úspěchů ve formalizaci gramatiky a nyní se začínají uplatňovat i v řešení otázek sémantiky,[38] mohou být s úspěchem rozvíjeny bez navázání na dosavadní výsledky jazykovědy. Naopak, jde tu v podstatě o uplatnění nových metod k řešení starých otázek, s kterými se jazykověda vždy určitým způsobem vyrovnávala a o kterých tedy už něco víme.[39] Právě u nás má algebraická lingvistika výhodnou situaci zejm. díky tomu, že může vycházet z funkčního pojetí pražské školy (viz výše uved. podněty Mathesiovy, dále známé Havránkovy teze o stupňovitosti vztahu formy a funkce v gramatické stavbě), ze Skaličkovy typologie (poskytující mj. dobrou základnu k rozlišení prvků tektogramatických a fenogramatických), ze Šmilauerova zevrubného rozboru české skladby a z mnoha dalších cenných výsledků naší lingvistiky.
R é s u m é
ЯЗЫК—ПОСРЕДНИК И ТЕОРИЯ ГРАММАТИКИ
1. Возможность формальной обработки языковых систем значительно приблизилась благодаря достижениям алгебраической теории грамматики. В дальнейшей разработке этой теории и ее приложений полезно, конечно, применять также и результаты классического языкознания. — 2. Пользуясь приемами теории грамматики в разработке машинного перевода, надо учитывать а) относительную сложность отдельных типов грамматик (трудно пользоваться здесь грамматиками, для которых пока не разработаны распознающие процедуры), б) сложное отношение грамматики и семантики (теорию которой, столь важную для перевода, нельзя строить без эмпирических приемов).
3. Грамматику ЯП («нестрогую», не исключающую все «неправильные» цепочки) можно строить как бесконтекстную грамматику фразовых структур; в таком случае составление алгоритмов перевода с естественного языка на ЯП и наоборот не было бы слишком затруднительным (в сопоставлении с бинарным переводом). Омонимия и синонимия в ЯП должны отсутствовать; из этого вытекает, что грамматические единицы ЯП должны приближаться единицам высших планов естественных языков (с точки зрения отношения формы и функции). — 4. В предлагаемой порождающей грамматике ЯП (см. правила 1—31) синтаксические связи выражаются символами Ra (agens), Rp (patiens), Ri (второе дополнение), Rd (необязательный второстепенный член), расставленными подобно функторам бесскобочной нотации; из обоих аргументов [128]этих функторов первый понимается как зависимый от второго (в лингвистическом смысле). Символы Qij можно рассматривать как функторы о i аргументах (без отношения зависимости); они означают сочинение и аппозицию.
5. Предложения определяются порождающей грамматикой только как единицы системы языка, а не как отрезки текста; порядок слов в предлагаемой системе ЯП не играет грамматической роли, и поэтому не определяется грамматикой, не совпадает с порядком символов в порождаемых цепочках. При переводе можно оставить порядок слов в основном тем же, каким он был в тексте входного языка, после устранения трансформаций, свойственных этому языку. (Это, конечно, не касается служебных слов, которые в нашем ЯП переходят в «суффиксальные» морфемы и функторы.) Порядок слов в тексте можно отметить, напр., особыми индексами. Факультативные трансформации входного языка надо в анализе перевести на символы, входящие в рамки грамматики фразовых структур; напр., придаточные предложения (также, как и номинализации) здесь трактуются просто как члены главного предложения. Для синтеза надо формулировать контекстные и трансформационные правила выходного языка более или менее подобным путем, как в его порождающей грамматике, но вместе с правилами выбора для некоторых факультативных трансформаций (напр. для выбора между номинализациями и придаточными предложениями).
6. Дальнейшая работа над этим предварительным наброском грамматики ЯП, включающая изучение самых разных языков с точки зрения отношения формы и функции, была бы, кажется, небезинтересной, не только для подготовки машинного перевода, а также для общего языкознания.
[1] Srov. R. L. Dobrušin, Matematičeskije metody v lingvistike, Matematičeskoje prosveščenije 6, 1961, s. 40.
[2] Viz Y. Bar-Hillel, Recent developments in algebraic and computational linguistics, předn. na konferenci o základech matematiky a matematických strojích v Tihany, 1962 (v tisku).
[3] Syntactic structures, ’s-Gravenhage 1957 (Janua linguarum IV); On certain formal properties of grammars, Information and control 2, 1959, 137—167; On the notion “rule of grammarˮ,Structure of language and its mathematical aspects, PSAM 12, 1961, 6—24; v ruském překladu vyšla první z těchto prací ve sb. Novoje v lingvistike 2, Moskva 1962, druhá — Kibernetičeskij sbornik 5, Moskva 1962.
[4] K. Čulík, Some axiomatic systems for formal grammars and languages, Preprint of the Proc. of the IFIP Congress 62, Mnichov 1962, 134—137.
[5] K těmto otázkám srov. R. B. Lees, O vozmožnostjach proverki lingvističeskich položenij, Vjaz 11, 1962, č. 4, s. 47—55.
[5a] Srov. informativní přehled otázek transformační gramatiky B. Palka zde, s. 140n.
[6] Viz zejm. G. H. Matthews, The use of grammars within the mechanical translation routine, Proc. of the Nat. Symp. on Mach. Transl. … 1960 (vyd. H. P. Edmundson), Englewood Cliffs 1961, 245—248 a jeho Analysis by synthesis, Teddington 1961.
[7] S. K. Šaumjan, Nasuščnyje zadači strukturnoj lingvistiki, Izv. AN, OLJ 21, 1962, 104.
[8] V tom je třeba dát za pravdu P. L. Garvinovi a W. Karushovi (v. Linguistics, data processing, and mathematics; vyjde ve sb. Natural language and the computer).
[9] Srov. N. Chomsky, Explanatory models in linguistics, Proc. of Intern. Congr. for Logic, Methodology and Philosophy of Science, Stanford Univ. 1960, vyd. 1962; J. Katz - J. Fodor, What’s wrong with the philosophy of language, Inquiry 5, 1962, zejm. s. 218n.
[10] V. Bar-Hillelovu práci uved. v pozn. 2, dále Y. Bar-Hillel, M. Perles, E. Shamir, On formal properties of simple phrase structure grammars, Jerusalem 1962 (Applied Logic Branch, The Hebrew Univ., Techn. rep. 4), přetišť. v Zeitschr. f. Phonetik, Sprachwissenschaft und Kommunikationsforschung 14, 1961, 143—172; M. Bierwisch, Über den theoretischen Status des Morphems, Studia grammatica I, Berlin 1962, 51—89.
[11] Ovšem někteří význační odborníci dnes popírají možnost (resp. rentabilnost) „stoprocentního“ strojového překladu; viz Y. Bar-Hillel, Four lectures on algebr. linguistics … (rozmnož.), 1963, odd. 4.
[12] N. D. Andrejev, Modelirovanije jazyka na baze jego statističeskoj i teoretiko-množestvennoj struktury, Tezisy Soveščanija po matem. lingvistike, Leningrad 1959, 15—22; P. L. Garvin, Automatic linguistic analysis — a heuristic problem, Teddington 1961; V. H. Yngve, A model and a hypothesis for language structure, Proc. of Amer. Philos. Society 104, č. 5, 1960, 444n. a The depth hypothesis, PSAM 12, 130—138.
[13] A. G. Oettinger, Automatic syntactic analysis and the push-down store, PSAM, 12. 104—129.
[14] N. D. Andrejev - S. J. Fitialov Jazyk-posrednik mašinnogo perevoda i principy jego postrojenija, Tezisy soveščanija po matem. lingvistike, Leningrad 1959, 59.
[15] Y. Bar-Hillel, The present status of automatic translation of languages, Advances in computers I, 1960, 91—163; v. též I. A. Meľčuk, Nekotoryje voprosy mašinnogo perevoda za rubežom, Moskva (VINITI) 1961, 18—25.
[16] Převedení textu z jazyka přirozeného do formalizovaného bude ovšem potřebné pro další úseky automatického zpracování údajů z textu; k tomu viz např. G. S. Cejtin, O promežutočnom etape pri perevode s jestestv. jazyka na jazyk isčislenija predikatov, Moskva (VINITI) 1961.
[17] I. A. Meľčuk, Raboty po mašinnomu perevodu v SSSR, Vestnik AN SSSR 1959, č. 2, 43—47; K voprosu o „grammatičeskom“ v jazyke-posrednike, Mašinnyj perevod i priklad. lingvistika 4, 1960, 25—45.
[18] N. D. Andrejev, Mašinnyj perevod i problema jazyka-posrednika, VJaz 6, 1957, č. 5, s. 117—121; srov. i práci uved. v pozn. 14, ale též A. Lentin, Sur la notion de congruence, La traduction automatique 1, 1960, č. 2, s. 11—17.
[19] I. I. Revzin, Formaľnyj i semantičeskij analiz sintaksičeskich svjazej v jazyke, sb. Primenenije logiki v nauke i technike, Moskva 1960, 119—139.
[20] Viz nyní zejm. M. Dokulil a Fr. Daneš, K tzv. významové a mluvnické stavbě věty, sb. O vědeckém poznání soudobých jazyků, Praha 1958, 231—246; P. Novák, O prostředcích aktuálního členění, AUC-Philologica I, Praha 1959, 9—15; J. Firbas, On the communicative value of the modern English finite verb, Brno Studies in English 3, 1961, 79—104, Ze srovnávacích studií slovosledných, SaS 23, 1962, 161—174 a jeho předcházející práce tam uvedené; ze starších prací především A. Séchehaye, Essai sur la structure logique de la phrase, Paříž 1926; V. Mathesius, Čeština a obecný jazykozpyt, Praha 1947.
[20a] O některých možnostech zpracování slovosledu viz F. Bach, The order of elements in a transformational grammar of German, Language 38, 1962, 263—269.
[21] H. B. Curry, Some logical aspects of grammatical structure, PSAM, 12, 56—68.
[22] H. Putnam, Some issues in the theory of grammar, PSAM 12, 25—42.
[23] P. S. Ray, The logic of linguistics, Methodos 13, sv. 51—52, 1961, 247; dále srov. např. A. Reichling, Principles and methods of syntax: cryptanalytical formalism, Lingua 10, 1961, 1—17; A. G. F. van Holk, On transformations, Synthese 14, 1962, 217—223.
[24] N. Chomsky - G. A. Miller, Introduction to the formal analysis of natural languages (rozmnož.), kap. 3; M. Bierwisch, Über die Bedingungen und Probleme bei der Anwendung mathematischer Theorien in der Sprachwissenschaft, předn. v Tihany, 1962, (v tisku).
[25] S. J. Fitialov, O modelirovanii sintaksisa v strukturnoj lingvistike, Problemy strukturnoj lingvistiki, Moskva, 1962, 100—114; srov. též K. G. Knowlton, Sentence parsing with a self-organizing heuristic program, Cambridge (MIT) 1962, kap. 1 (rozmnož.).
[26] Srov. R. J. Solomnoff, The mechanization of linguistic learning, 2nd Intern. Congr. on Cybernetics, Namur, vyd. 1960, 180n; A new method for discovering the grammars of phrase structure languages, Information Processing, UNESCO, Paříž 1960, 285—290.
[27] K tomu srov. V. H. Yngve, A model … (viz zde pozn. 12); A. G. Oettinger, A new theory of translation and its applications, Proc. of the Nat. Symp. on MT 1960, 363—366; v takto pojaté generativní gramatice se uplatňuje tzv. závislostní koncepce větné skladby, srov. P. Novák, Některé otázky syntaktické analýzy, SaS 23, 1962, 9—20.
[28] O výhodách, které má toto pojetí větné struktury — s přísudkem jako řídícím členem — srov. S. J. Fitialov, o. c. v pozn. 25.
[29] K podobnému výběru základních kategorií dospívá také M. Dokulil, Teorie odvozování slov, Praha 1962, 32. Toto rozdělení vychází z některých základních vlastností syntaxe mnoha jazyků (srov. vztahy predikace, nutného a volného doplnění, formálně zpracované ve výše uved. studii Revzinově) a v praxi bude patrně výhodné dále ho zjemnit, srov. B. M. Lejkina, K voprosu o strukture jazyka-posrednika, Moskva (VINITI) 1961, 22n.
[30] Jde o určenost pojmovou (nocionální), kontextovou, posesívní a neurčenost. — V pravidlech 16—31 označují čárky možnost výběru, podobně jako výše svorky.
[31] Jako prostředek kontextového členění je tu slovosled charakteristický pro výpověď, nikoli pro větu; srov. Fr. Daneš, K vymezení syntaxe, Jazykovedné štúdie 4, 1951, 41—45.
[32] Srov. R. B. Lees, O pereformulirovanii transformacionnych grammatik, VJaz 10, 1961, č. 6, s. 41—50.
[33] Pro češtinu zpracovala tuto koncepci se zřetelem ke strojovému překladu E. Macháčková v čl. Spojky podřadicí v čes. matematických textech, SaS 24, 1963, 38—47.
[34] Viz výše uved. stať N. Chomského ve sb. PSAM 12, zejm. s. 17 a 19.
[35] Mezivětné vztahy zatím v podobě generativní gramatiky zpracovány nejsou, ale podle zkušeností získaných v práci na překladových algoritmech bude možné zařadit sem — vedle kontextového členění — aspoň prvky jako „mezivětný důsledek“ (tedy), „mezivět. adverz.“ (přesto) aj.
[36] Viz J. Kuryłowicz, Dérivation lexicale et dérivation syntaxique, BSL 37, 1936, 79—92.
[37] K významu převodního jazyka z tohoto hlediska srov. např. E. de Groliеr, Quelques problèmes de codification, 2nd Intern. Congr. on Cybernetics, Namur, vyd. 1960, 174n.
[38] Viz zejm. J. A. Fоdоr, Of words and uses, Inquiry 4, 1961, 190—208 a stať J. A. Fodora a J. Katze uved. v pozn. 9.
[39] Vždyť i některé ústřední pojmy transformační gramatiky navazují dost těsně na tradiční okruhy otázek; srov. např. zřejmou souvislost mezi těmi transformacemi, které jsme výše označili jako kompoziční, a mezi jevy zahrnutými třeba ve Šmilauerově Učebnici větného rozboru (Praha 1955) jako „translace“.
Slovo a slovesnost, ročník 24 (1963), číslo 2, s. 114-128
Předchozí Jaroslav Kuchař: Základní rysy struktur pojmenování
Následující Vladimír Hrabě: Existuje nulový znak?
© 2011 – HTML 4.01 – CSS 2.1