
K otázce statistického výběru v lingvistice
Marie Königová
[Discussion]
К вопросу о статистической выборке в лингвистике / Sur la question du choix statistique en linguistique
1.1. Význam určení výběru v lingvistice. Jedním z několika odvětví aplikací matematiky v lingvistice je lingvistická statistika. Statistické šetření má význam nejen pro lingvistiku kvantitativní, ale pro lingvistiku vůbec.
Obecným problémem, kterým se chci v této stati zabývat, je určení výběru v lingvistice. Metody, kterých lze přitom použít, ověříme na konkrétním příkladu stanovení výběrů pro výpočet četností grafémů. S touto otázkou jsme se setkali při výpočtu entropie a redundance psané češtiny[1] při sestavování frekvenční tabulky českých grafémů a jejich spojení. Určení výběru v lingvistice je jednou z nejdůležitějších otázek lingvistické statistiky vůbec.
Užíváme přitom metod matematické statistiky, jejímž úkolem je na základě zákonitostí ve výběru usuzovat na neznámé zákonitosti v základním souboru. Parametry základního souboru odhadujeme z charakteristik výběrových s určitou přesností a spolehlivostí. Spolehlivost odhadu je dána pravděpodobností toho, že výběr, který jsme provedli, je jedním z výběrů, na jehož základě bude správné naše tvrzení o odhadovaném parametru základního souboru pomocí příslušné výběrové charakteristiky. Dostatečnou kvalitu odhadů si musíme zajistit takovým výběrem, který by dobře reprezentoval základní soubor. Reprezentativnosti výběru dosahujeme nejčastěji náhodným výběrem, kdy má každá jednotka základního souboru stejnou možnost, že bude pojata do výběru.
Pro správný výběr a správný odhad parametrů zkoumaného souboru je důležité správné vymezení základního souboru. Zejména jednotky je nutno stanovit tak, aby je bylo možno identifikovat a vybírat. Vypracovaný výběrový postup je nutno v zájmu reprezentativnosti výběru důsledně dodržovat.
Metodami matematické statistiky můžeme určit rozsah výběru tak, aby hledaná pravděpodobnost byla rovna vztahu ![]() s požadovanou přesností (
s požadovanou přesností (![]() je relativní četnost jevu ve výběru o rozsahu n). Zvětšíme-li délku textu (tj. rozsah základního souboru) a zvýšíme-li požadavky na přesnost, bude rozsah výběru vzrůstat.
je relativní četnost jevu ve výběru o rozsahu n). Zvětšíme-li délku textu (tj. rozsah základního souboru) a zvýšíme-li požadavky na přesnost, bude rozsah výběru vzrůstat.
[162]Správné použití výběrových metod dovoluje určit každou lingvistickou charakteristiku v libovolném statistickém souboru. Charakteristiky (např. úhrny, poměry, poměry úhrnů, průměr, relativní četnosti) vypočtené na základě výběru se stávají statistickými odhady parametrů základního souboru.
Přenášení výsledků z výběrového souboru na základní soubor je speciálním případem velmi obvyklého myšlenkového pochodu, který nazýváme zobecňováním z části na celek. Matematická statistika dovedla dát tomuto zobecňovacímu pochodu objektivní matematický tvar.
1.2. Druhy výběrů. Druhy výběrů jsou velmi rozličné, uvedu zde proto jen nejtypičtější (podrobněji o výběrovém šetření viz u J. Hájka[2]):
Náhodný výběr provádíme tehdy, nemáme-li žádné znalosti o základním souboru nebo známe-li jen jeho rozsah; spočívá v tom, že dáme každé jednotce základního souboru stejnou možnost, aby se dostala do výběru. Příklad náhodného výběru v lingvistice bude uveden dále.
Záměrný výběr provádíme tehdy, máme-li o základním souboru dostatečné informace, ale záměrně vybíráme ty jednotky, o nichž předpokládáme, že budou pro daný soubor typické. U tohoto výběru nemůžeme stanovit přesnost, ani spolehlivost.
Systematický (mechanický) výběr volíme při velmi rozsáhlém základním souboru, jsou-li jednotky základního souboru seřazeny do nějaké posloupnosti podle hlediska, jež nesouvisí se znaky, které zkoumáme. Vybíráme každý i-tý prvek, přičemž i se stanoví podle rozsahu výběru. První prvek zvolíme náhodně z prvních i prvků.
Oblastní výběr volíme rovněž tehdy, jde-li o základní soubor rozsáhlý. Rozdělíme jej na L nepřekrývajících se oblastí a potom v každé samostatně, nezávisle navzájem provedeme prostý náhodný výběr. Každá oblast přitom vystupuje jako samostatný menší základní soubor. Jsou-li rozsahy oblastí N1, N2, … NL a oblastní výběrové soubory mají rozsahy n1, n2, … nL, potom celý základní soubor má rozsah
N = N1 + N2 … + NL
a výběrový soubor
n = n1 + n2 … + nL.
Jsou-li výběrové rozsahy n úměrné základním rozsahům N, říkáme, že oblastní výběr je rovnoměrný. Při rovnoměrném oblastním výběru má každá jednotka stejnou pravděpodobnost, že bude zahrnuta do výběrového souboru nezávisle na tom, do které oblasti patří. Tato pravděpodobnost se rovná společné hodnotě zlomku
![]()
Při rovnoměrném oblastním výběru lze nadále užívat výběrových ukazatelů k odhadu jejich základních protějšků. (Při nerovnoměrném oblastním výběru by bylo nutno hodnotám z různých oblastí udělit různou váhu.)
Dvoustupňový výběr provádíme pro snadnější organizační zvládnutí výběrového zjišťování. V prvním stupni vybereme náhodně určité širší jednotky, primární, v nich pak ve druhém stupni náhodně jednotky, jejichž znaky nás zajímají, jednotky sekundární.
O vícestupňový výběr jde v lingvistice vždycky, když je výběr více než dvoustupňový. Prvním stupněm může být např. určení určitého období, jehož jazyk chceme zkoumat, např. současná spisovná čeština (už to je velké omezení); druhý [163]stupeň tvoří výběr děl, která reprezentují příslušné období; v třetím stupni vybíráme jen části textu z těchto děl; čtvrtý stupeň se už vztahuje k vlastnímu zkoumání, např. náhodný výběr vět, slov apod.
1.3. Odhady parametrů. Při prostém náhodném výběru odhadujeme průměr základního souboru ā pomocí průměru výběrového x̅ jako
![]()
kde n je rozsah výběru; x̅i jsou hodnoty znaku vybraných prvků. Úhrn v základním souboru ![]() , tj. součet všech hodnot v základním souboru odhadujeme jako
, tj. součet všech hodnot v základním souboru odhadujeme jako
A = N . x̅,
kde N je rozsah základního souboru.
Relativní četnost v základním souboru odhadujeme pomocí výběrové relativní četnosti jako
![]()
a absolutní četnost v základním souboru jako součin výběrové relativní četnosti a rozsahu základního souboru, tj. jako
![]()
směrodatná odchylka základního souboru σ1 se odhaduje pomocí směrodatné odchylky výběrové s1 při výběrech s vracením jako
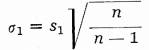
a při výběrech bez vracení jako
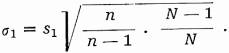
První čtyři odhady jsou nezkreslené, neboť platí, že průměr všech průměrů je roven průměru základního souboru.
Charakteristikou přesnosti odhadu průměru základního souboru při prostém náhodném výběru je střední kvadratická chyba
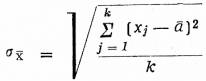 , kde k je počet všech možných výběrů.
, kde k je počet všech možných výběrů.
Chybu, kterou při odhadu předem připouštíme, nazýváme přípustnou chybou. Ta je určitým násobkem střední chyby stanoveným tak, abychom jej překročili v co nejmenším počtu případů. Výše přípustné chyby charakterizuje přesnost konkrétního odhadu.
Provádíme-li proporcionální oblastní výběr, tj. takový, kdy rozsahy výběrů v jednotlivých oblastech (nj) jsou přesně úměrné počtu prvků v základních oblastech, můžeme odhadnout nezkresleně průměr základního souboru jako
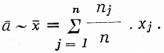
[164]2. Kvantitativní hodnocení psané češtiny
2.1. Mechanický a náhodný výběr. V této části uvedu příklad užití výběrových metod při určování četnosti grafémů a digramů při soustavném kvantitativním výzkumu češtiny. Navazuji zde na úkol zjištění entropie a redundance psané češtiny (viz pozn. 1).
Při tomto výzkumu se vyskytly dvě podstatné otázky: určení rozsahu výběrového souboru a materiálu, na němž se budou šetření provádět. Materiál byl určen tak, aby zahrnoval pokud možno různé vyhraněné styly psané češtiny, tedy text vědecký, populárně vědecký, beletristický, básnický, novinářský apod.
Výběrová šetření byla tu dvojího druhu:
1. Vybrali jsme 20 000 grafémů celkem z 10 textů mechanickým výběrem; vzali jsme tedy posloupnost 20 000 grafémů bez náhodného určování vět. V tomto výběru jsme určovali četnost grafémů a digramů.
2. Očíslovali jsme 1 000 vět a pořídili náhodný výběr o rozsahu 250 vět. Tento výběr jsme provedli pomocí tabulek náhodných čísel. Poněvadž rozsah N = 1 000, zahrnuli jsme do výběru věty podle tabulky náhodných čísel s nejvýše trojciferným číslem. Čísla již jednou vybraná a čísla větší než N jsme pominuli. První číslo jsme vybrali namátkou na jisté stránce tabulek. Rozsah takto pořízených výběrů se pohyboval také kolem 20 000 grafémů, ale nikdy nebyl roven přesně této hodnotě. To však není na závadu, poněvadž porovnáváme relativní četnosti. Z takto utvořených výběrů jsme opět určovali četnosti grafémů a digramů.
(Rozsahy byly např.: 18 086 Hrubín, U stolu, 23 623 Rudé právo, 22 228 Učebnice fyziky pro 11. ročník.)
2.2. Určení spolehlivosti a rozsahu výběru. Abychom mohli hodnotit spolehlivost našich výsledků, určujeme chybu buď absolutní, nebo relativní, jak o tom podrobněji píše R. M. Frumkinová.[3] Absolutní chyba je definována jako rozdíl četnosti pozorované ve výběru a četnosti pozorované v základním souboru:
| P — p |.
Relativní chyba je definována jako ![]() , což určuje vztah tohoto rozdílu k určované veličině. Absolutní i relativní chyby budou tím menší, čím větší bude rozsah výběru. Vztah pro určení rozsahu výběru s přípustnou chybou můžeme odvodit, známe-li předem četnost. Čím je při dané relativní chybě δ menší četnost, tím větší musí být výběr. Jestliže P → 0, pak n → ∞.
, což určuje vztah tohoto rozdílu k určované veličině. Absolutní i relativní chyby budou tím menší, čím větší bude rozsah výběru. Vztah pro určení rozsahu výběru s přípustnou chybou můžeme odvodit, známe-li předem četnost. Čím je při dané relativní chybě δ menší četnost, tím větší musí být výběr. Jestliže P → 0, pak n → ∞.
Např. grafém ó má v češtině velmi malou četnost, a proto při desetiprocentní relativní chybě bychom museli vzít rozsah výběru 4 000 000 grafémů. Naopak pro nejčetnější grafém e stačí při téže relativní chybě rozsah výběru 5 700.
Vzájemný vztah mezi četností P, výběrem n a relativní chybou lze vyjádřit

uα je kvantil normálního rozdělení
uα = 2 odpovídá hladině významnosti 0,95. (Předpokládáme-li, že četnosti jsou rozloženy podle Gaussova zákona.)
Použitím vztahu (1) můžeme řešit dvě základní otázky vyskytující se v práci lingvisty, který chce podat kvantitativní zhodnocení:
[165](1) zhodnocení spolehlivosti výsledků, tj. určit relativní chybu, s níž se v daném výběru vypočítá četnost lingvistického jevu;
(2) určit rozsah výběru zaručujícího stanovení četnosti s danou relativní chybou.
Abychom mohli užít vztahu (1), musíme vědět, z přibližně jaké četnosti máme vyjít, jinak bychom měli co činit s dvěma neznámými. Proto buď určíme hranice četností na základě hodnot známých z literatury, anebo provedeme jednoduchý pokus. Z výběru nevelkého rozsahem odhadneme četnost sledovaného znaku s jistou relativní chybou. Vezmeme dolní hranici četnosti a s chybou přípustnou pro konečné výsledky (tzn. s požadovanou přesností) vypočteme nutný rozsah výběru. Dále budeme relativní chybu, s níž jsme ochotni výsledky ještě přijmout, nazývat přípustnou chybou.
V odstavci 2.4. porovnáme výsledky, kterých jsme dosáhli při určování četnosti grafémů u výběrů z beletrie (Hrubín, U stolu) a vědeckého textu (Wolf, Učebnice histologie).
2.3. Utvoření tříd grafémů. Třídy utvoříme podobně jako R. Moreau ve své práci,[4] v níž ukazuje, že relativní četnosti grafémů netvoří klesající posloupnost. Utvoříme-li však třídy grafémů, pak součty četností v každé třídě P(Ci) a zároveň průměry p tvoří klesající posloupnost. Uvnitř každé třídy může dojít k určitým nepravidelnostem v rozložení četností.
Např. grafém č má u Hrubína nejvyšší četnost ve třídě C8, ale nejnižší u Wolfa; obdobně grafém ď ve třídě C9. Naopak grafémy ó a x mají u Wolfa podstatně vyšší četnost (výskyt cizích slov v Učebnici histologie) než u Hrubína (srov. tab. č. 1).
2.4. Porovnání výběrů z beletrie a vědeckého textu. Pro každou takto utvořenou třídu vypočítáme dále rozsah výběru n a přípustnou chybu δ. Výpočet provedeme opět pro oba výběry.
Relativní chyba se pro grafémy s vysokou četností (a, e, o) pohybuje kolem 6 %, pro grafémy s průměrnou četností (d, j, p, í, á) kolem 10 % a pro grafémy s nízkou četností (ú, f, g) kolem 30 %.
Obrátíme se nyní k druhé otázce, tj. k určení rozsahu výběru s předem stanovenou přípustnou chybou. Vztah (1) upravíme:
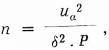
kde uα vezmeme rovno 2, což odpovídá 95% hladině významnosti; přípustnou chybu δ stanovíme 10 % a četnosti P vezmeme opět z týchž dvou výběrů: z beletrie a z vědeckého textu. Pro nejčetnější grafémy (a, e, o) stačí rozsah výběru od 7 000 do 8 000; pro grafémy průměrně četné (d, j, p, í, á) rozsah výběru 20 000; pro grafémy nejméně četné (ú, f, g) rozsah výběru od 150 000 do 170 000. Pro grafémy x, w bychom museli vzít dokonce výběr o rozsahu 4 miliónů jednotek, abychom zajistili pouze desetiprocentní chybu.
Pro přehlednost sestavíme tabulku č. 2. V prvním sloupci uvádíme číslo třídy, v druhém grafémy, v třetím a čtvrtém rozmezí četností od maximální k minimální v příslušné třídě u obou výběrů, v pátém a šestém zaokrouhlený rozsah výběru vypočtený pro dolní hranici četnosti ve třídě, v sedmém a osmém sloupci relativní chybu.
Postupu, kterého jsme užili při výpočtu relativní chyby a rozsahu výběru, můžeme užít pro každý kvantitativní údaj a určovat, která ze dvou pozorovaných hodnot je spolehlivější a přesnější.
[166]Tabulka č. 1
| Třída Ci | Grafém | Hrubín | Wolf | ||
| p | P(Ci) | p | P(Ci) | ||
| C1 | mezera | 18,22 | 18,22 | 14,72 | 14,72 |
| C2 | e a o | 7,54 6,42 5,84 | 19,80
p̄ = 6,60 | 7,08 5,38 6,37 | 18,83
p̄ = 6,57 |
| C3 | l s k n i | 4,26 3,80 3,63 3,55 3,50 | 18,74
p̄ = 3,74 | 3,61 3,60 3,44 5,19 3,82 | 19,66
p̄ = 3,93 |
| C4 | v t m u | 3,36 3,15 3,01 3,00 | 12,50
p̄ = 3,12 | 4,23 3,83 2,51 3,43 | 14,00
p̄ = 3,50 |
| C5 | d r p í | 2,79 2,71 2,44 2,30 | 10,21
p̄ = 2,55 | 2,26 3,29 2,80 2,83 | 11,18
p̄ = 2,79 |
| C6 | á j z b | 2,05 1,96 1,80 1,57 | 7,38
p̄ = 1,84 | 1,78 2,01 1,89 1,71 | 7,39
p̄ = 1,85 |
| C7 | y h ň ř ch | 1,48 1,28 1,16 1,04 1,03 | 5,99
p̄ = 1,19 | 1,64 1,11 1,90 0,82 1,29 | 6,76
p̄ = 1,35 |
| C8 | č ž c š é ý | 0,93 0,89 0,83 0,76 0,75 0,69 | 5,99
p̄ = 0,80 | 0,53 0,73 1,05 0,59 1,01 0,88 | 4,79
p̄ = 0,79 |
| C9 | ď ť ě ú f g | 0,54 0,54 0,52 0,38 0,25 0,01 | 2,24
p̄ = 0,37 | 0,11 0,69 0,60 0,60 0,24 0,25 | 2,49
p̄ = 0,41 |
| C10 | ó x w | 0,01 0,01 0,00 | 0,02
p̄ = 0,00 | 0,13 0,04 0,01 | 0,18
p̄ = 0,06 |
p … četnost
p̄ … průměrná četnost ve třídě
P (Ci) … součet četností ve třídě
[167]Tabulka č. 2
| Třída Grafém | Četnost | n | δ | ||||
| Hrubín | Wolf | Hrubín | Wolf | Hrubín | Wolf | ||
| C1 | mezera | 18,22 | 14,71 | 2 200 | 2 700 | 3 % | 3,5 % |
| C2 | e, a, o | 7,53—5,48 | 7,08—5,37 | 6 700 | 7 500 | 6 % | 6 % |
| C3 | l, s, k, n, i | 4,25—3,50 | 5,19—3,44 | 11 500 | 11 700 | 7,5 % | 7,5 % |
| C4 | v, t, m, u | 3,36—3,00 | 4,23—2,51 | 13 400 | 16 000 | 8 % | 9 % |
| C5 | d, r, p, í | 2,78—2,29 | 3,29—2,26 | 17 400 | 17 700 | 9 % | 9,5 % |
| C6 | á, j, z, b | 2,05—1,57 | 2,01—1,71 | 25 500 | 23 300 | 11 % | 11 % |
| C7 | y, h, ň, ř, ch | 1,48—1,03 | 1,90—1,11 | 38 500 | 35 800 | 14 % | 13 % |
| C8 | č, ž, c, š, é, ý | 0,93—0,69 | 1,05—0,53 | 57 200 | 74 000 | 17 % | 19,5 % |
| C9 | ď, ť, ě, ú, f, g | 0,54—0,01 | 0,69—0,11 | 2 000 000 | 333 300 | 115 % | 41,5 % |
| C10 | ó, x, w | 0,01—0,00 | 0,13—0,01 | 4 000 000 | 4 000 000 | 141 % | 141 % |
2.5. Rozložení grafémů. Test χ2. Pro srovnání četností grafémů z 10 výběrů různých stylů a ověření shodnosti souborů, z nichž výběry pocházejí, můžeme provést test pomocí χ2. Zjistíme tedy, zda se rozložením grafémů v psané češtině styly významně liší, nebo zda toto rozložení je pro všechny styly přibližně stejné.
Provedli jsme výpočet pro četnosti grafémů z beletrie (Hrubín, U stolu) a vědeckého textu (Wolf, Učebnice histologie). Úmyslně jsme vzali text beletristický a vědecký, které se od sebe zásadně liší. Četnosti grafémů jsme seřadili sestupně podle velikosti a vzali jsme prvních 18 nejčetnějších z obou výběrů. Ostatní grafémy s četností nižší než 2,00 jsme do testu nepojali, poněvadž pro ně již není výběr 20 000 reprezentativní. Hodnota χ2 se pak rovná ![]() , kde n je rozsah výběru, ni,j jsou četnosti, index i značí různé styly, index j různé grafémy, ni. je součet četností pro všechny grafémy, n.j součet četností pro oba styly. Pro objasnění smyslu uvedených charakteristik rozdílnosti výskytu různých grafémů v různých druzích textu poznamenejme toto:
, kde n je rozsah výběru, ni,j jsou četnosti, index i značí různé styly, index j různé grafémy, ni. je součet četností pro všechny grafémy, n.j součet četností pro oba styly. Pro objasnění smyslu uvedených charakteristik rozdílnosti výskytu různých grafémů v různých druzích textu poznamenejme toto:
Každý úsek textu je považován za shluk grafémů vybraný náhodně ze souboru všech grafémů, kterých český spisovný jazyk užívá. (Říkáme zde náhodně vybraný proto, že jsme se při volbě příslušného úseku neřídili četnostmi grafémů, vybírali jsme texty bez jakékoli snahy o ovlivnění výsledku.) Kdyby v každém druhu prózy byly jednotlivé grafémy zastoupeny přibližně stejně, očekávali bychom, že i v delších úsecích náhodně vybraných textů budou přibližně stejná procenta jednotlivých grafémů. Tabulka č. 1 však ukazuje, že např. ve vědeckém textu je 5,38 % grafémů a, zatímco v beletrii 6,42 %. Je třeba posoudit, do jaké míry lze tento rozdíl vysvětlit náhodností při výběru textu a do jaké míry ukazuje na podstatnou rozdílnost v základní slovní zásobě literatury vědecké a umělecké. K tomu cíli slouží statistický test, který jsme provedli. Veličina χ2 vypočtená podle uvedeného vzorce je mírou rozdílnosti četností jednotlivých grafémů v různých typech prózy. Kdybychom vybrali jiné úseky textu, dostali bychom jinou hodnotu χ2. Kdyby jednotlivé grafémy byly v slovní zásobě různých stylů a oborů zastoupeny stejně početně, pak by hodnoty χ2 s pravděpodobností 0,95 byly menší než 8,67 (což je příslušná kritická hodnota).[5] Při opakování pokusu s různými úseky textů jen průměrně v pěti případech ze sta by tedy vyšla hodnota χ2 větší než 8,67. Vypočítali jsme hodnotu χ2 pro oba výběry (Wolf, Hrubín) pořízené (1) mechanicky, (2) náhodně. V prvním případě vychází hodnota χ2 = 1 292, ve druhém χ2 = 156. Obě tyto hodnoty jsou větší než tabelovaná [168]hodnota. Nastal tedy jev, který má — za předpokladu přibližně stejného rozložení grafémů v různých oborech literatury — velmi malou pravděpodobnost. Jsme tedy oprávněni k závěru, že ve slovníku jazyka vědeckého jsou grafémy rozloženy jinak než v slovníku spisovatele beletristy, neboli, že rozložení grafémů v beletrii se statisticky významně liší od rozložení grafémů ve vědeckém textu. Pracujeme-li s náhodnými výběry, vychází hodnota χ2 podstatně nižší (χ2 = 156) než u výběrů mechanických (χ2 = 1 292). Najdeme-li metodicky správné výběrové šetření, které by splňovalo přísné požadavky testu, přiblížíme se ještě více tabelované hodnotě χ2. Náhodný výběr vylučuje vliv opakování téhož slova v souvislém textu a přibližuje se požadavku testu o nezávislosti jednotlivých pokusů, čili o nezávislosti grafémů.
2.6. Digramy. Přejdeme-li od jednotlivých grafémů k dvojicím čili digramům, dostaneme tento obraz. Relativní četnosti u digramů jsou vesměs nižší než u grafémů. Abychom zajistili reprezentativnost výběru, museli bychom rozsah výběru podstatně zvýšit. Ze 42 grafémů lze utvořit celkem 42 . 42 dvojic, tj. 1 764 digramů. V textu se nevyskytují všechny kombinace, nýbrž asi polovina, tedy 800 až 900 digramů.
Rozsah výběru by byl pro nejčetnější digramy 20 000, pro digramy, které jsou podle četnosti na 50. místě, asi 135 000 a pro digramy, které jsou v polovině, tedy asi na 400. místě, asi 1 600 000. Rozsah 20 000 bude reprezentativní pouze pro tyto digramy:
| Hrubín, U stolu | Wolf, Učebnice histologie |
| a — (2,44) e — (2,36) s — (2,03) | e — (2,15) |
Shrnutí. Jedním z úkolů matematické statistiky je na základě zákonitostí ve výběru usuzovat na neznámé zákonitosti v základním souboru. Při kvantitativním zpracování jakéhokoli lingvistického jevu musíme pořizovat výběr, poněvadž základní soubor je zpravidla vždycky nekonečný nebo fiktivní. Výběr musí být pořízen, zpracován a zhodnocen tak, aby poskytoval o základním souboru maximální informaci. Poměry ve výběru se nikdy nerovnají přesně poměrům v základním souboru, ale jsou jejich určitou analogií.
Kvantitativním veličinám, které popisujeme, říkáme v základním souboru parametry, ve výběru charakteristiky. Parametry základního souboru odhadujeme z charakteristik výběrových s určitou přesností a spolehlivostí, kterou určíme podle absolutní nebo relativní chyby. Dostatečnou kvalitu odhadů si musíme zajistit takovým výběrem, který by dobře reprezentoval základní soubor. Reprezentativnosti výběru dosahujeme nejčastěji náhodným výběrem. Jednou ze základních otázek lingvistické statistiky je určení rozsahu výběru s předem stanovenou přípustnou chybou.
Postupu, kterého jsme použili, můžeme použít pro každý kvantitativní údaj a určovat, která z dvou pozorovaných hodnot je spolehlivější a přesnější.
[1] L. Doležel, Předběžný odhad entropie a redundance psané čestiny, SaS 24, 1963, 165—175.
[2] Teorie pravděpodobnostního výběru s aplikacemi na výběrová šetření, Praha 1960, kap. II.
[3] O. S. Achmanova, I. A. Meľčuk, E. V. Padučeva, R. M. Frumkina, O točnych metodach issledovanija jazyka, Moskva 1961, s. 67—97.
[4] Quantité d’information et redondance aux différents niveaux de français écrit, cyklost., Paris 1963.
[5] J. Janko, Statistické tabulky, Praha 1958.
Slovo a slovesnost, volume 26 (1965), number 2, pp. 161-168
Previous Jan Chloupek: Městská mluva v Uherském Brodě
Next František Kopečný: Kniha o sponě
© 2011 – HTML 4.01 – CSS 2.1