
Podnětný ukrajinský sborník kvantitativní stylistiky
Jiří Kraus, Pavel Vašák
[Rozhledy]
Инициативный украинский сборник квантитативной лингвистики / Un recueil suggestif ukraïnien concernant la linguistique quantitative
Statistični parametri stiliv (Kyjev 1967, 260 s.) je sborníkem prací z kvantitativní stylistiky, jímž se představuje kolektiv autorů Potebňova Ústavu jazykovědy v Kyjevě pod redakcí V. I. Perebejnosové. Zatímco většina studií ukrajinských pracovníků, které byly na tomto úseku publikovány dříve,[1] soustřeďovala se převážně na řešení dílčích otázek kvantitativní lingvistiky, nalézáme v recenzovaném sborníku jednotnou koncepci a převládající snahu o komplexní přístup k souboru kvantitativních údajů z hlediska jejich stylové funkce, tj. jejich schopností stát se „stylovými parametry“.
Již na první pohled se sborník vyznačuje přehledným utříděním zpracovávaného materiálu. Po úvodní stati M. A. Žovtobrjucha věnované stylistickému rozboru ukrajinštiny a po výkladu užitých statistických metod V. I. Perebejnosové následují oddíly věnované stylistickým funkcím rozložení fonémů (V. I. Perebejnosové), slabik (L. M. Gridnevové), sufixů (M. P. Muravické), sloves (V. M. Rusanivského), postavení přísudku ve větě (M. N. Peščakové), rozložení spojek (L. O. Kadomcevové), délce věty v počtu slov (L. F. Kosjukové), rozložení interpunkčních znamének (V. K. Kuzmičové), délce slova v počtu fonémů (V. I. Perebejnosové), rozložení předpon (M. P. Muravické) a frekvenčnímu uspořádání slov v současné ukrajinštině (G. M. Grimičové, O. F. Savrančukové a I. F. Savčenkové). Materiál zahrnuje oblast beletrie (drama, uměleckou [426]prózu a poezii), společenskovědní a politické literatury (administrativní, publicistický, řečnický a populárně vědecký žánr) a vědeckou a technickou prózu (vyjadřování odborné a texty učebnic) za posledních čtyřicet let vývoje ukrajinštiny. Každý z žánrů je zastoupen 5—6 autory, takže výsledky umožňují jak porovnání stylů funkčních, tak i autorských. Protože poznání stylové funkce zkoumaných jevů je založeno na velikosti odchylky od průměrného stavu, snaží se autoři o stanovení tzv. ideálního souboru „nulového stylu“. Vedeni snahou o nezávislost jednotek tohoto souboru na zjišťovaném materiálu (a na jeho průměrných hodnotách), zvolili pomocí tabulky náhodných čísel z Pravopisného slovníku ukrajinštiny 5000 slov, tj. asi 50 tisíc fonémů. Aby konstruovaný výběr neobsahoval pouze slovníkové formy, vybíral se prostřednictvím náhodných čísel i jeden z možných tvarů odpovídajícího slova.
Použité metody jsou jasně a přehledně uvedeny na počátku monografie, takže i čtenář, který není odborníkem ve statisice, je s nimi na pravém místě seznámen. Statistické pojmy jsou vyloženy co nejjednodušeji; tento způsob výkladu nejde však na úkor matematické přesnosti. Je jistě sympatické, že autoři monografie neváhali takový způsob výkladu do monografie zařadit. Vždyť celé dílo je určeno převážně pro lingvisty, z nichž zdaleka ne všichni jsou se základními statistickými metodami a postupy uspokojivě seznámeni.
V práci se v podstatě užívají pouze dvě statistické charakteristiky pro popis jazykových dat — průměr a rozptyl, resp. směrodatná odchylka. Získané charakteristiky se porovnávají v rámci jednotlivých stylů, popř. autorů pomocí Pearsonova testu χ2, koeficientu pořadové korelace Spearmana a především pomocí Studentova t-testu. V této souvislosti je třeba připomenout, že Studentův t-test (tj. test pro srovnání významnosti odchylek dvou průměrů) vychází z požadavku platnosti tzv. normálního rozložení. Zůstává otázkou, zda o všech jevech hodnocených tímto testem normální rozložení skutečně platí. Důležitost opodstatněného užití t-testu vyplývá z toho, že toto kritérium je základní statistickou metodou autorů monografie. Pro účely srovnávání průměrných hodnot nejrůznějších jazykových údajů mezi jednotlivými funkčními styly nebo autory se totiž užívá tzv. koeficientu vzdálenosti, který je definován jako
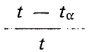
kde t je vypočtená velikost testového kritéria a tα = kritická hodnota t-rozložení uvedená v tabulkách. Autoři tedy vypočítali pro sledované jazykové jevy velikost testového kritéria t pro každou dvojici stylů. Sledujeme-li např. frekvenci fonému n’ pro jednotlivé styly, ukazuje se, že pro dvojici: styl dramat — styl vědeckotechnický je hodnota testového kritéria t = 13,0. Kritická hodnota t-rozložení je pro jednoprocentní hladinu významnosti a příslušný počet stupňů volnosti rovna 2,88. Oba styly se tedy významně liší. Zjištěná vzdálenost je stanovena vzorcem
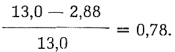
Číselná vzdálenost mezi oběma styly na základě zvoleného jevu (četnosti fonému n’) je rovna 0,78.
Spearmanův koeficient korelace pořadí označuje stanovení míry závislosti mezi různými jazykovými jevy. Je výhodný především pro snadný a rychlý výpočet. Pro stanovení intervalu spolehlivosti je užito intervalu ![]() , kde N je rozsah výběru a
, kde N je rozsah výběru a ![]() směrodatná odchylka průměru.
směrodatná odchylka průměru.
Zůstává otázkou, zda pro popis získaných jevů jsou dostačující pouze dvě statistické charakteristiky, tj. průměr a rozptyl. Oprávněnost požadavku dalších měr je patrna [427]zvláště při komplexnějších jevech, jako jsou např. rozložení délky slov a vět. Bylo by tedy možno uvažovat i o aplikaci takových charakteristik distribuce, jako jsou kvartily, mezikvartilové odchylky, modus, medián a devátý decil. I pro tyto míry lze konstruovat uvedené intervaly spolehlivosti a dojít tak k úplnějšímu popisu rozložení. Oprávněný je především devátý decil, tj. veličina, za níž následuje 10 % sledovaných prvků. Zvláště v rozložení větných délek nastává taková situace, že text obsahuje extrémně dlouhé věty, které podstatně mění průměr i rozptyl. Devátý decil by mohl ukázat, jaké procento dlouhých vět distribuce obsahuje.[2]
Jedním z nejsložitějších problémů, které kvantitativní lingvistika řeší, je rozsah výběru pro zjištění frekvence sledovaných jevů.[3] Nejlepším z dosavadních řešení se zdá přístup experimentální, tj. empirické určení rozsahu výběru; tento výběr se potom rozdělí na určitý počet stejných částí a ty se potom vzájemně testují, aby se zjistila jejich statistická homogennost. K testování jsou vhodné vícerozměrné statistické testy (Bartlettův, Hottelingův aj.). Rozsah výběrů užitých v recenzované monografii představuje základnu pro praktické i teoretické řešení problematiky výběrových souborů v jazykovědě.
Zajímavým způsobem je v práci doložena originální myšlenka, že rozložení fonémů je jedním z kritérií diferenciace funkčních stylů. Zastoupení jednotlivých tříd fonémů je totiž ovlivněno řadou omezení lišících se podle žánrů:
| Žánr
Omezení | Drama | Próza | Poezie | Pop. věd. styl | Věd. techn. styl | Nulový styl |
| Zákonitosti jazyka Tematika Obraznost výkladu Rytmus Rým | + + + (+) (+) | + + + (+) — | + + + + (+) | + + (+) — — | + + — — — | + — — — — |
(Znaménko + označuje obligatorně působící omezení, (+) fakultativní omezení a — nepřítomnost omezení v odpovídajícím žánru.)
Počet těchto omezení je v přímé korelaci s rozsahem vzdálenosti jednotlivých žánrů od „nulového stylu“, v němž se uplatňuje pouze jediný organizující princip, a to jazyková zákonitost. Autoři přesvědčivě ukazují, že největší podíl samohlásek obsahují společenskovědní a vědeckotechnické žánry, méně vokalická jsou dramata, zatímco nejvíce konsonantů je v poezii. Toto zdánlivě překvapivé zjištění (platné i pro soustavu českých fonémů) zároveň vyvrací platnost kritéria tzv. libozvučnosti, podle něhož texty obsahující největší podíl vokálů a sonor jsou nejlibozvučnější (podle tohoto hlediska jsou v ukrajinštině na prvním místě texty umělecké prózy (79,3 %), dále vědeckotechnická literatura (79,1 %); poezie s 78,9 % je až na třetím místě).
Obdobnou funkci stylových parametrů má i rozložení slabik. Autoři vycházejí z tzv. [428]paralelogramů možných slabičných typů[4] a zkoumají jejich zastoupení a frekvenční využití. Průměrná délka slabiky se pohybuje od 2,34 (v dramatu) do 2,40 (vědeckotechnická próza); nejčastějšími slabičnými typy jsou V, CV, CCV, CCCV, CVC, CCVC; parametrem stylu, tedy slabikou s nejzřetelnější diferenciační funkcí jsou typy CCCV a CV.
Výrazným parametrem stylu je i frekvenční zastoupení jednotlivých afixů. Nejzřetelnější slovotvornou strukturu má odborná próza, opačný pól tvoří texty beletristické, zvláště poezie, v nichž je počet předpon a přípon největší. V každém stylu se projevuje tendence volit vlastní soubor afixů, která souvisí s frekvencí slovních druhů a kategorií. Nejčastější příponou je např. -a (gen. sing. n. znan’-a), které se vyskytuje u většiny termínů odborného stylu. Naopak imperativní a vokativní přípony se vyskytují téměř výhradně v dramatě a poezii.
Podkladem pro výpočet frekvencí slovesných tvarů je binární dělení kategorií podle tohoto schématu:
| určité tvary ————————————————— neurčité tvary / \ / \ rozlišující čas nerozlišující čas infinitiv neinfinitiv / \ / \ / \ minulý čas neminulé časy kondicionál imperativ příčestí přechodník / \ přítomný čas budoucí čas |
Parametry funkčního (a méně zřetelně i autorského) stylu jsou (a) celková frekvence sloves, (b) vztah tvarů určitých a neurčitých a (c) frekvence jednotlivých slovesných kategorií. Získané výsledky v procentech uvedeme v porovnání s odpovídajícími údaji českými.[5]
(Frekvenční slovník češtiny neuvádí v přehledu zvlášť kategorii příčestí; obě pojetí se liší i v chápání budoucího času; v recenzovaném sborníku jsou shrnuty tvary jednoduchého a složeného futura, FSČ uvádí pouze tvary složené.)
| Žánr (v závorce skupina FSČ) | Min. | Přít. | Bud. | Kond. | ||||
| Ukr. | Č | Ukr. | Č | Ukr. | Č | Ukr. | Č | |
| Drama (D) | 24,1 | 18,6 | 38,5 | 50,8 | 9,5 | 1,8 | 1,2 | 6,8 |
| Uměl. próza (A) | 55,1 | 45 | 14 | 31,2 | 6 | 0,8 | 0,6 | 5,9 |
| Poezie (B) | 31,8 | 23,9 | 33,2 | 55,3 | 12 | 0,6 | 0,4 | 3 |
| Spol. věd. (E) | 26,6 | 17,6 | 35,1 | 50,3 | 5 | 0,4 | 2 | 4,5 |
| Věd. techn. (G) | 4,5 | 15,5 | 54,5 | 54,7 | 13,5 | 0,6 | 0,2 | 4,2 |
| Žánr (v závorce skupina FSČ) | Imp. | Inf. | Přech. | |||
| Ukr. | Č | Ukr. | Č | Ukr. | Č | |
| Drama (D) | 10,9 | 7,3 | 11,7 | 12,4 | 1,9 | — |
| Uměl. próza (A) | 3,1 | 2,3 | 9,8 | 9,7 | 6 | 1,6 |
| Poezie (B) | 7 | 3,9 | 9,5 | 8,9 | 2,1 | 1,5 |
| Spol. věd. (E) | 0,3 | 0,4 | 17,1 | 12,3 | 3,9 | 0,7 |
| Věd. techn. (G) | 0,5 | 0,9 | 12,7 | 13,6 | 5,7 | 0,7 |
V uvedeném přehledu frekvencí slovesných tvarů se projevují dva typy činitelů ovlivňujících číselné hodnoty, a to zákonitosti jazyka a zákonitosti funkčního stylu. Typologickými vlastnostmi jazyka jsou podmíněny např. vyšší četnosti přechodníků v ukrajinštině, funkčním stylem nízké hodnoty pro imperativy v odborné a vědeckotechnické próze. Třetí činitel, individuální styl autora, nemá povahu zákonitosti, ale [429]projevuje se v kolísání frekvence některých kategorií, zvláště v beletristických žánrech (nejvíce se liší jednotliví ukrajinští autoři v užívání přechodníků). Kvantitativní výsledky, které sborník uvádí, jsou ovšem pouze prvním nutným krokem k hlubšímu poznání promluvových funkcí. Každý kvantitativní údaj je totiž podmíněn složitým komplexem objektivních a subjektivních slohotvorných činitelů, jejichž působení se nejenom sčítá, ale i vyrovnává. Úlohou interpretace textů je tedy podrobný rozbor porovnávaných číselných hodnot vyjádřených v kvalitativních pojmech odrážejících vlastnosti zkoumaných textů, jak se projevují ve své vnitřní struktuře i ve vztahu k uživatelům jazyka. Výsledky sborníku týkající se funkčních stylů jsou tedy přesvědčivější než přehled údajů o stylech individuálních především proto, že jsou abstrahovány od tématu. Právě frekvence sloves je podle našeho názoru podmíněna spíše mírou dynamiky děje než jeho stylem, který chápeme jako záměrnou volbu jazykových prostředků.[6]
Zkoumání funkce predikátu v slovosledu představuje jednu z nejoriginálnějších kapitol sborníku. Analyzují se zde tříčlenné skupiny prvků typu X Pred. X, kde X je libovolným slovním tvarem nebo interpunkčním znaménkem. Největší počet kombinatorních variant je pro styly odborné, u beletristických textů převládají v bezprostředním okolí predikátu zájmeno, čárka a tečka.
Zjištění průměrných délek věty představuje výstižný stylový parametr, v němž se objevují zajímavé analogie mezi údaji ukrajinskými a českými:
| Drama | Uměl. próza | Poezie | Pop. věd. | Odb. text | |||||
| Ukr. | Čeština (Topol) | Ukr. | Čeština (Hrubín) | Ukr. | Čeština (Hrubín) | Ukr. | Čeština (Instr.) | Ukr. | Čeština (Wolf) |
| 4,53 | 4,56 | 12,43 | 10,70 | 10,53 | 4,86 | 17,57 | 14,16 | 15,17 | 18,87 |
(České údaje srov. u L. Doležela Model stylistické složky jazykového kódování, SaS 26, 1965, 223—234 a J. Krause Kvantitativní rozbor stylu pracovních návodů, NŘ 49, 1966, 193—199.)
Tabulka poměrně přesvědčivě dokládá skutečnost, že údaje o délce věty závisí převážně na stylovém, v daleko menší míře na jazykovém omezení (jediný význačnější rozdíl uvedených dat v plánu českém a ukrajinském představuje poezie, kde délka věty je značně variabilní i v plánu jednoho jazyka).
Kapitola věnovaná frekvenčnímu seznamu nejčastějších ukrajinských slov obsahuje 309 lexikálních jednotek doplněných četnostmi slovních tvarů v textu uspořádaných abecedně. Právě k tomuto užitečnému souhrnu dat postrádáme komentář, který by se zamýšlel nad některými statistickými zákonitostmi rozložení slovní zásoby. Vzhledem ke zvýšenému zájmu sovětských pracovišť o otázky frekvence slov lze však očekávat, že materiál zde zpracovaný představuje pouze jedno z východisek další práce na tomto úseku.
Celkově můžeme recenzovaný sborník hodnotit jako materiálově bohatý, přehledně utříděný základ pro systematický kvantitativní popis současné ukrajinštiny, přitahující k sobě pro svou metodologickou ujasněnost a soustavnost při popisu jednotlivých jazykových rovin a při diferenciaci funkčních stylů zájem jazykovědců, a to i těch, kteří sami kvantitativních metod neužívají.
[1] Srov. zprávu J. Krause Ukrajinské sborníky o statistické a strukturní lingvistice, SaS 28, 1967, 323—325.
[2] Podobným způsobem zpracoval rozložení délky vět již G. U. Yule, On Sentence-Length as a Statistical Characteristic of Style in Prose. With Application to Two Cases of Disputed Authorship, Biometrika 30, 1939, 363—390. Stejně postupuje i A. Q. Morton, The Authorship of Greek Prose, JASA 1965, vol. 128, P. II, 169—233.
[3] Ne zcela vždy vyhovuje postup, který navrhuje Frumkinová (srov. O. S. Achmanova — I. A. Mel’čuk — E. V. Padučeva — R. M. Frumkina, O točnych metodach issledovanija jazyka, Moskva 1961), opírající se o předběžné znalosti četností výskytu sledovaného jevu.
[4] P. Menzerath, Typology of Languages, JASA 22, 1950, 698—701.
[5] J. Jelínek — J. V. Bečka — M. Těšitelová, Frekvence slov, slovních druhů a tvarů v českém jazyce, Praha 1961.
[6] Vedle této kvantitativně nejsnáze zachytitelné linie stylu jako výběru jazykových prostředků existují ovšem i linie další, spočívající v uspořádání jazykového inventáře, v členění tematickém, v posloupnosti sémantické atd. Srov. K. Hausenblas, Zobrazení prostoru v Máchově Máji, sb. Realita slova Máchova, Praha 1967, 70n.
Slovo a slovesnost, ročník 29 (1968), číslo 4, s. 425-429
Předchozí Eva Pokorná, Vlasta Červená: O ukrajinských lexikografických a lexikologických sbornících
Následující Jan Průcha: Leonťjevův úvod do psycholingvistiky
© 2011 – HTML 4.01 – CSS 2.1