
Model stylistické složky jazykového kódování
Lubomír Doležel
[Články]
Модель стилистического компонента языкового кодирования / Un modèle du composé stylistique du codage linguistique
I. Složky jazykového kódování
1. Pojem jazykového kódování. Jazykovým kódováním rozumíme posloupnost operací, jimiž vznikají sdělení (promluvy, texty) v přirozeném jazyce. Je to vstupní etapa komunikačního procesu, který je zobrazen známým schématem Shannonovým a Meyer-Epplerovým.[1] Průběh jazykového kódování si lze představit takto: Zdroj jazykových informací (kódovač) vytváří (produkuje) z elementárních jednotek jazykového kódu a s použitím jeho pravidel konkrétní sdělení (promluvy), které jsou jazykovým zobrazením určitých mimojazykových „událostí“.[2]
Základními úkoly teorie jazykového kódování jsou: 1. určit elementární jazykové jednotky, na nichž se provádějí kódovací operace; 2. popsat pravidla, podle nichž se elementární jednotky organizují v jazyková sdělení. V prvním bodě přejímáme stanovisko, které za elementární jednotku jazykového kódo[224]vání považuje slovo-lexém („konkrétní jednotka“).[3] Slova a jednotky nižší než slova (morfémy) se netvoří v aktuálním procesu kódování, tvoření slov a morfémů je akt jazykové diachronie, jímž se mění daný „stav jazyka“. „De Saussurova a naše hypotéza, že každý text se skládá z konkrétních jednotek, je ekvivalentní s aproximativním ztotožněním jazyka s takovým systémem, v němž se možnosti vzniku nových forem prudce zvýší z nuly na nekonečno, jakmile délka forem překročí délku konkrétních jednotek“ (B. Mandelbrot, o. c., s. 140). Základní výstupní jednotkou procesu jazykového kódování je výpověď;[4] posloupnost výpovědí vytváří jazykové sdělení (promluvu).
Úkol 2 můžeme tedy nyní formulovat konkrétněji: Je třeba zjistit a popsat pravidla, jimiž se v procesu kódování vytvářejí ze slov výpovědi a z výpovědí sdělení. V tomto příspěvku si však tento úkol záměrně zužujeme na etapu „slovo — výpověď“, protože pro popis etapy „výpověď — sdělení“ nejsou zatím vytvořeny dostatečné analytické předpoklady.[5]
2. Schéma jazykového kódování. Domnívám se, že v procesu jazykového kódování musí být rozlišeny minimálně tři operace: 1. Operace pojmenování: zadané množině mimojazykových událostí[6] E = {e1, e2 … er} se přiřazují jazyková zobrazení z konečné množiny slov V = {va, vb, … vz}, jež má k dispozici kódovač. Slovo anebo skupinu slov z V, které lze přiřadit elementární událostí ei, budeme nazývat denotátem. Ve shodě s jazykovou empirií předpokládáme, že ve většině případů je možno jedné elementární události přiřadit více denotátů významově ekvivalentních (synonymních).[7] Výsledkem operace pojmenování je tedy přiřazení podmnožiny denotátů Vi ⊂ V elementární události ei. 2a. Operace výběru (selekce): z Vi se vybírá pouze jeden denotát, pro daný případ optimální, zatímco ostatní jsou eliminovány. Opakováním obou popsaných operací dostáváme negramatikalizovanou (gramaticky neorganizovanou) posloupnost denotátů ![]() . 3. Operace usouvztažnění: Gramaticky amorfní posloupnost denotátů se přetváří v gramatikalizovanou výpověď mající formu určité syntaktické konstrukce. [225]Přitom je zpravidla možné transformovat jednu a touž posloupnost denotátů ve dvě anebo více syntaktických konstrukcí funkčně ekvivalentních (synonymních). 2b. Operace výběru, analogická operaci výběru denotátů: v průběhu této operace je zvolena jedna syntaktická konstrukce, která je považována pro danou situaci za optimální.
. 3. Operace usouvztažnění: Gramaticky amorfní posloupnost denotátů se přetváří v gramatikalizovanou výpověď mající formu určité syntaktické konstrukce. [225]Přitom je zpravidla možné transformovat jednu a touž posloupnost denotátů ve dvě anebo více syntaktických konstrukcí funkčně ekvivalentních (synonymních). 2b. Operace výběru, analogická operaci výběru denotátů: v průběhu této operace je zvolena jedna syntaktická konstrukce, která je považována pro danou situaci za optimální.
Operaci pojmenování nazveme sémantickou složkou, operaci usouvztažnění — složkou syntaktickou a operaci výběru (zahrnující 2a i 2b) — stylistickou složkou jazykového kódování.[8]
Vcelku lze popsané kódovací operace zobrazit tímto schématem:

Ke schématu je třeba připojit tyto poznámky:
1. Pro zjednodušení je vypuštěna operace realizace (zvukové nebo grafické), která je konečnou složkou jazykového kódování.
2. Jde nám jen o takové rámcové zobrazení kódovacích operací, jaké je nezbytně nutné pro začlenění operace výběru, jež je vlastním předmětem naší práce. Propracování popisu ostatních operací a jejich vztahů není úkolem této studie.
3. Lze snadno postřehnout, že naše schéma využívá myšlenek V. Mathesia o „jazykové stylizaci“, zejm. jeho rozlišení dvou základních aktů, z nichž vznikají jazykové promluvy, aktu „pojmenovávacího“ a aktu „větotvorného“.[9] Rovněž časová následnost těchto dvou operací odpovídá Mathesiovým představám: „Představíme-li si normální vznik promluvy sdělné o několika slovech podle vzoru zpomaleného filmu v tempu do nemožnosti zvolněném, předchází v něm rozbor dané skutečnosti v úseky jazykově pojmenovatelné nutně před aktem větotvorným, jímž se jednotlivá slova, označující vybrané úseky skutečnosti, uvádějí ve vzájemné vztahy určené větným vzorcem“ (ve sb. Čtení o jazyce a poezii, s. 17).
4. Lze docela dobře zkonstruovat jiná schémata jazykového kódování, např. takové, které vychází z usouvztažňovací (syntaktické) složky.[10] Volba nej[226]vhodnějšího schématu je zatím určována především cílem studia, méně našimi skromnými znalostmi o skutečném průběhu procesu jazykového kódování.[11]
II. Empirické pojmy selekce
1. Subjektivní a objektivní faktory selekce. Každé jazykové sdělení je kódováno určitým konkrétním mluvčím v určitém komunikačním okruhu přirozeného jazyka.[12] V důsledku toho je proces výběru popsaný v I,2 řízen (regulován) mimojazykovými faktory dvojího druhu: a) faktory subjektivními, jimiž rozumíme všechny vlastnosti mluvčího, jež jsou relevantní při provádění výběru (rozsah aktivních jazykových schopností, psychický typ, stylizační talent, momentální psychický stav atd.); b) objektivními faktory Q, kterými rozumíme podmínky působící v jednotlivých komunikačních okruzích nezávisle na mluvčím. Patří sem např. forma jazyka užitá při kódování (mluvená — psaná), forma sdělení (dialog — monolog) a zejména tzv. funkce sdělení.[13]
2. Třídy sdělení (promluv). Na množině sdělení T produkovaných v daném synchronním stavu jazyka lze pak definovat tyto podmnožiny: podmnožiny Ki, tj. množiny sdělení produkovaných v určitém komunikačním okruhu jazyka, a podmnožiny Sj, tj. množiny promluv kódovaných určitým mluvčím. Jinými slovy, Ki je množina (třída) sdělení přiřazená určitému komunikačnímu okruhu, Sj — množina (třída) sdělení přiřazená určitému kódujícímu subjektu. Mezi oběma systémy podmnožin existuje překrývání (overlapping). Zavádíme proto označení Sji ⊂ S pro podmnožinu sdělení, jež jsou kódovány mluvčím j v komunikačním okruhu i. Vcelku lze pak vztahy mezi T, K a S popsat takto:
T = K1 ∪ K2 ∪ … ∪ Km ≡ S1 ∪ S2 ∪ … ∪ Sn
Ki = S1i ∪ S2i ∪ … ∪ Sni
Sj = Sj1 ∪ Sj2 ∪ … ∪ Sjm,
přičemž některé Sji mohou být prázdné.
Tak jsou formálně vyjádřeny dvě důležité skutečnosti: a) že týž mluvčí může produkovat sdělení (promluvy) v různých komunikačních okruzích, tj. vytváří např. sdělení jak psaná, tak mluvená, může psát jak romány, tak novinářské články nebo odborná pojednání atd.; b) že někteří mluvčí neprodukují texty (sdělení) ve všech komunikačních okruzích daného jazyka.
Evidentní zkušenosti lingvistiky prokazují, že třídy sdělení se mezi sebou liší určitými specifickými vlastnostmi, které nazveme vlastnostmi stylovými. Styl potom budeme definovat jako množinu všech specifických vlastností [227]určité třídy sdělení. Budeme mluvit o stylu subjektivním jako množině všech specifických vlastností třídy Sj a stylu objektivním jako množině všech specifických vlastností třídy Ki.
3. Stylové charakteristiky a jejich vlastnosti. Předpokládáme, že stylové vlastnosti jsou měřitelné anebo převeditelné na měřitelné vlastnosti. Jejich kvantitativním (statistickým) vyjádřením jsou tzv. stylové charakteristiky (charakteristiky X), dobře známé z dosavadního vývoje statistické stylistiky. Stylové charakteristiky zadáváme v základní formě jako rozložení četností určitých jazykových elementů anebo tříd jazykových elementů, mohou však být přirozeně také vyjádřeny v podobě momentů, kontingenčních tabulek, vektorů, koeficientů (viz např. Busemannův koeficient), informačních měr atd. Každý text a každá třída textů bude pak zobrazena množinou (svazkem) stylových charakteristik, nabývajících určitých hodnot, resp. n-rozměrným vektorem (srov. M. Bense, o. c., s. 3).
Domnívám se, že na stylových charakteristikách bude možno popsat některé obecné statistické vlastnosti, čímž se prohloubí jejich dosavadní převážně empirické studium. Pro potřeby našeho modelu zůstáváme u těchto vlastností: a) homogennost — nehomogennost vzhledem k třídám sdělení, definovaným v II,2; b) stacionárnost — nestacionárnost vzhledem k časovému průběhu charakteristiky.[13a] Obojí vlastnost lze vyjádřit v dvojrozměrném prostoru, jehož jednou dimenzí je komunikační síť přirozeného jazyka, druhou — časový průběh sdělení.
Stylovou charakteristiku budeme nazývat objektivní (K-charakteristika), jestliže její hodnoty v určité třídě sdělení Ki jsou statisticky homogenní, tj. nevykazují statisticky významnou fluktuaci. Stylovou charakteristiku budeme nazývat subjektivní (S-charakteristika), jestliže její hodnoty v množině Ki vykazují významnou fluktuaci, avšak jsou statisticky homogenní v množině sdělení Sji. Stylovou charakteristiku budeme nazývat stacionární, jestliže v časovém průběhu sdělení bude statistiky stabilní, tj. bude-li vyhovovat těmto podmínkám pro stacionární posloupnosti:[14]
| E K(t1) = E K(t2) … = μ D K(t1) = D K(t2) … = σ2 | E S(t1) = E S(t2) … = μ D S(t1) = D S(t2) … = σ2 |
Tyto vlastnosti stylových charakteristik jsme empiricky zjistili na příkladu rozložení délky vět.[15] V několika textech současné spisovné češtiny jsme stanovili tuto průměrnou délku věty (vyjádřenou v slovech):
x̅1 = 4,56 J. Topol, Jejich den
x̅2 = 4,86 Fr. Hrubín, Křišťálová noc
x̅3 = 14,61 Večerní Praha
x̅4 = 15,20 Rudé právo
x̅5 = 18,87 J. Wolf, Učebnice histologie
[228]Rozdíl mezi extrémními hodnotami x̅1 a x̅5 se ukázal, jak bylo možno očekávat, statisticky významný. (Bylo použito parametrického t-testu na hladině významnosti α = 0,05.) Naproti tomu rozdíly mezi x̅1 a x̅2, stejně jako mezi x̅3 a x̅4 se ukázaly jako statisticky nevýznamné. Z toho lze usoudit, že rozložení délky vět je objektivní stylovou charakteristikou jak v sděleních novinářských, tak v současném českém (konverzačním) dramatu. Toto zjištění je zvláště zajímavé pro oblast dramatu, kde jsou srovnávána díla dvou autorů patřících k různým generacím.
Ke zkoumání byly dále přibrány dva výběry z poezie M. Holuba a M. Floriána. Rozdíly v průměrné délce věty (x̅6 = 10,32, x̅7 = 14,26) se ukázaly jako statisticky významné. Z toho lze soudit, že ve sděleních současné poezie není rozložení délky vět stylovou charakteristikou objektivní, nýbrž subjektivní.
Běžnými statistickými metodami bylo dále prokázáno, že ve zkoumaných textech obou dramat má rozložení délky vět povahu stacionární, kdežto v obou výběrech poezie je charakteristika nestacionární.[16]
V této souvislosti nás zajímá nejen empirická evidence zmíněných vlastností stylových charakteristik, nýbrž také to, že tyto vlastnosti nejsou fixované vzhledem k dané charakteristice. Táž stylová charakteristika (v našem případě rozložení délky vět) může v určité třídě sdělení Ki vykazovat vlastnost homogenity, ale v jiné třídě může být nehomogenní, podobně může táž stylová charakteristika v určité třídě sdělení probíhat stacionárně, kdežto v jiné třídě (v poezii) může vykazovat vlastnost nestacionárnosti. Tento závěr musí být považován za eminentně důležitý pro další rozvoj teorie stylových charakteristik.[17]
4. Způsoby regulace stylových charakteristik. Za těchto okolností je možno zpřesnit popis vztahu mezi stylovými charakteristikami a jejich regulačními faktory. Je třeba rozlišit tři případy: 1. Regulaci, při níž se uplatňují pouze objektivní faktory, takže charakteristika je za týchž faktorů Q ve sděleních různých mluvčích udržována na homogenních hodnotách (tj. nevykazujících statisticky významnou fluktuaci). 2. Regulaci, při níž se uplatňují jak objektivní, tak subjektivní faktory a charakteristika tudíž vykazuje za konstantních podmínek Q statisticky významné rozdíly ve sděleních různých kódujících subjektů. 3. Regulaci, která je řízena pouze subjektivními faktory, při níž je charakteristika za různých podmínek Q statisticky homogenní ve sděleních téhož mluvčího. Tento třetí případ nebudeme zatím uvažovat, poněvadž se zdá být anomální.[18]
III. Formální model
1. Předpoklady: a) Předpokládá se, že selekce probíhá tak, že z množiny alternativních jazykových jednotek je vybírána jedna jednotka, která je v konkrétní situaci považována za optimální.
b) Předpokládá se, že řízení selekce objektivními a subjektivními faktory [229]má povahu automatické regulace, tj. probíhá tak, že se výběr alternativ přizpůsobuje (adaptuje) působícím extralingvistickým faktorům.[19]
c) Předpokládá se, že alternativní jednotky vstupují do selekce bez jakýchkoli pravděpodobnostních charakteristik. Výsledkem selekce je přiřazení určitých pravděpodobností výskytu jednotlivým alternativám, tj. transformace abecedy alternativ A v náhodnou proměnnou ω(A) s určitým rozložením pravděpodobností.
2. Výběrové alternativy. Výchozím pojmem každého modelu selekce je pojem množina (abeceda) výběrových alternativ.[20] Avšak právě vymezení této množiny je v lingvistice (podobně jako v jiných případech selekce) nevyřešeným problémem. Zde se můžeme spokojit s tím, že budeme množiny alternativních (synonymních) jazykových prvků považovat za zadané a jejich definování uložíme teorii jazykového popisu. Formalizace pojmu synonymity patří k nejaktuálnějším úkolům lingvistické teorie.[21]
Zaveďme tato označení:
U — množina (konečná nebo nekonečná), z níž je možno tvořit abecedy alternativ; např. věty o délce <1, ∞>, množina všech slov jazyka apod.
T — konečná podmnožina z U, ze které se skutečně tvoří abecedy alternativ: věty určité konečné délky <1, n>, aktivní slovník určitého mluvčího.
A ⊆ T — množina alternativ, abeceda alternativ A = {a, b, … z}, která je v konkrétním výběrovém aktu předmětem selekce; v některých případech A = T (délka vět), v jiných A ⊂ T (množina lexikálních synonym).[22]
Nevyřešeným problémem je právě definice podmnožiny A na množině T, která vyžaduje zavedení určitého kritéria ekvivalence. Zdá se, že pro jazykové elementy různých rovin bude třeba definovat různá kritéria ekvivalence. Pro sémantickou rovinu se o to např. pokusil N. I. Žinkin použitím kritéria logické ekvivalence.[23] Je ovšem možné, že pro stylistický výběr bude vhodnější definovat množiny výběrových alternativ nikoli na základě kritéria přísné logické ekvivalence, nýbrž na základě kritéria „parafráze“[24] nebo kritéria „sémantické totožnosti“.[25]
3. Regulování selekce. Proces regulování selekce si můžeme představit na základě tohoto schématu:

[230]Schéma má obecnou povahu a zobrazuje jak působení objektivních faktorů Q, tak vliv parametrů kódovače K, který funguje jako selektor. Zpětná vazba od dekódovače D umožňuje kódovači sledovat, zda je při selekci dosahováno žádoucí adaptace. V případě, že jde o kódování bez přítomnosti dekódovače, musí tuto kontrolu provádět kódovač sám.
Vzhledem k tomu, co bylo řečeno v II,4, je třeba v modelu rozlišit dvojí typ regulace: a) regulace objektivní, při níž se parametry kódovače neuplatňují a výběr je řízen pouze množinou objektivních faktorů Q; b) regulace subjektivní, při níž se na regulaci podílejí jak množina faktorů Q, tak individuální vlastnosti selektoru.
4. Zavedení modelu náhodného automatu. K zobrazení obecných vlastností a činnosti selektoru lze použít abstraktního náhodného automatu.[26]
Podle M. O. Rabina je náhodný automat zadán formulí: ↔AA = (S, M, s0, F) a vstupní abecedou Σ = {σ, ρ …}. Ve vzorci S = {s0, … sn} je konečná množina vnitřních stavů automatu, M je funkce S X Σ taková, že pro každé (s, σ) ∊ S X Σ M (s, σ) = [p0 (s, σ), … pn, (s, σ)], přičemž Σpi (s, σ) = 1. M se nazývá tabulka pravděpodobnosti přechodu, s0 ∊ S je počáteční stav, F ⊂ S je množina označených konečných stavů. Je zřejmé, že pro naše účely jsou v definici automatu relevantní hlavně množiny S, M a Σ.
Činnost automatu popisuje Rabin takto: „Náhodné automaty jsou modely systémů (jako jsou např. sériově zapojené okruhy), které se mohou nacházet v konečné množině stavů s0, … sn. Systém může obdržet vstupy σ ∊ Σ. Je-li ve stavu s a je-li vstup σ, pak může systém přejít do kteréhokoli ze stavů si ∊ S, a pravděpodobnost, že přejde do stavu si je (i + 1)-ní koordináta pi(s, σ) z M(s, σ). Předpokládá se, že pravděpodobnosti přechodu pi (s, σ) zůstávají stálé a jsou nezávislé na čase a na předcházejících vstupech“ (o. c., s. 234).
Podle K. Čulíka doplňujeme do definice automatu množinu symbolů Y, která představuje výstupní abecedu automatu, a (determinovanou) funkci Ψ(si), která každému stavu si ∊ S přiřazuje určitý výstupní symbol z abecedy Y. V činnosti automatu se toto doplnění projeví tak, že automat při přechodu do stavu si produkuje (generuje) určitý výstupní symbol z abecedy Y podle výstupní funkce Ψ(si).
Pokusme se nyní naznačit, jak bude fungovat stylistický selektor modelovaný jako náhodný automat. Budiž Q = {q1, … qn} vstupní abeceda Σ, S = {s0, … sz} konečná množina vnitřních stavů selektoru, M(s, q) matice pravděpodobností přechodu daného selektoru; abecedu alternativ A = {a, b, … z} ztotožníme s výstupní abecedou Y. Selektor funguje tak, že při přijetí vstupního symbolu q ∊ Q může přejít s určitou pravděpodobností ze stavu si do stavu s(i + 1) a přitom vybírá určitý symbol z abecedy alternativ podle funkce Ψ(si). Po n krocích generuje selektor řetězec symbolů o délce n, který se vyznačuje určitým rozložením pravděpodobností ω(A).
V této stati nejsou studovány jiné vlastnosti modelu než ty, které umožňují formalizaci dvou základních typů selekce, definovaných v II,4. Jestliže předpokládáme, že všechny selektory se v daném komunikačním okruhu cho[231]vají jako automaty s totožnou maticí M(s, q), potom je selekce de facto řízena pouze množinou Q. Je-li pro každý selektor zadána jeho vlastní matice Mi(s, q), modeluje automat selekci za působení objektivních i subjektivních faktorů.
Selekci při objektivní regulaci lze zobrazit takto:
|
| ↓ Q1 | ↓ Q2 … | ↓ Qn |
| a | P1(a) | P2(a) | Pn(a) |
| b | P1(b) | P2(b) | Pn(b) |
| . . . z |
P1(z) |
P2(z) |
Pn(z) |
|
| ξ1(A) | ξ2(A) | ξn(A) |
V každém sloupci platí: Σ Pi = 1.
Q1, Q2, … Qn jsou množiny objektivních stylových faktorů, které působí v jednotlivých komunikačních okruzích. Pod vlivem těchto regulujících faktorů je na výstupu selektoru generován (vybírán) řetězec symbolů z abecedy A, vyznačující se obecně rozložením pravděpodobností ξi(A). Náhodná proměnná ξi(A) se nazývá objektivní stylový parametr.
Pro subjektivní selekci se bude přirozeně tabulka značně komplikovat, protože každý selektor bude za týchž podmínek Qi generovat jinou náhodnou proměnnou:
| ↓ Q1 | ↓ Q2 … | |||||
|
| M1(s, q) | M2(s, q) | M3(s, q) … | M1(s, q) | M2(s, q) | M3(s, q) … |
| a | P11(a) | P21(a) | P31(a) … | P12(a) | P22(a) | P32(a) … |
| b | P11(b) | P21(b) | P31(b) … | P12(b) | P22(b) | P32(b) … |
| . . . z | . . . P11(z) |
P21(z) |
P31(z) … |
P12(z) |
P22(z) |
P32(z) … |
|
| η11(A) | η21( A) | η31(A) | η12(A) | η22(A) | η32(A) |
Pro každý sloupec platí: Σ Pi = 1.
Jestliže výběr symbolů z abecedy A je řízen jak faktory Qi, tak parametry selektoru, je výsledkem generování náhodná proměnná ηji (A), kterou budeme nazývat subjektivním stylovým parametrem.
Navržený model dovoluje rovněž zobrazení vlastnosti stacionarity. Z Rabinovy definice náhodného automatu, kterou jsme uvedli výše, plyne, že náhodná proměnná ξi (A), stejně jako ηji (A) bude vykazovat v časovém rozvinutí vlastnost stacionarity; zobrazení této vlastnosti tedy nevyžaduje zavedení žádných nových prvků do modelů. Obtížnější situace vzniká s definicí vlastnosti nestacionarity, pokud se nespokojíme s jejím čistě negativním vymezením. Není mi zatím známa žádná práce, která by se zabývala teorií [232]nestacionárních automatů; zdá se však, že tato teorie by měla v modelování chování složitých systémů (nejen lingvistických) zásadní důležitost.
5. Formální definice vlastností stylových charakteristik. Model umožňuje formální definici vlastností stylových charakteristik zavedených v II,3. Stylová charakteristika Xi se bude nazývat objektivní a stacionární, jestliže nevykazuje statisticky významnou odchylku od parametru ξi (A); stylová charakteristika bude subjektivní a stacionární, jestliže se od parametru ξi (A) odchyluje významně, avšak nevykazuje statisticky významnou fluktuaci vzhledem k příslušnému parametru ηji (A). Měření odchylky je přirozeně záležitostí běžných statistických testů vztahu mezi teoretickým rozložením pravděpodobností a empirickým rozložením četností.
6. Omezení modelu. Model je třeba považovat pouze za první pokus o formální zobrazení operace stylistické selekce. Vedle již zmíněných omezení (zejména toho, že v něm nejsou definována kritéria ekvivalence výběrových alternativ) vykazuje model tato omezení:
a) Objektivní i subjektivní regulační faktory nejsou kvantifikovány, takže model nedovoluje stanovení „apriorních“ pravděpodobností v rozloženích ξi (A) a ηji (A). Máme zatím jen možnost spojovat zcela obecně určitá rozložení jazykových prvků s určitými podmínkami Q anebo s určitými individuálními postoji kódovačů.[27] Přesto, že tato situace je zřejmě i u jiných pravděpodobnostních modelů složitých struktur,[28] musí být kvantifikace objektivních i subjektivních faktorů selekce považována za nejpřednější úkol exaktní stylistiky.
b) V modelu není studován problém optimálního stylistického výběru, jeho podmínek a kritérií. Zde bude třeba model dále rozvíjet zavedením rozhodovacích procedur vedoucích k volbě optimální varianty.
c) I kdyby se podařilo odstranit uvedená omezení, nepůjde stále ještě o úplný model stylistiky. Teoretická stylistika má vysvětlit nejen vznik a průběh stylových charakteristik, ale rovněž jejich vzájemné vztahy, vytvářející stylovou strukturu jazykového sdělení.
IV. K syntetické lingvistické teorii
N. Chomsky a G. A. Miller[29] formulovali v poslední době tyto tři základní složky lingvistické teorie: a) teorie jazykových schopností (znalostí) — modely jazyka („langue“), b) teorie užívání jazyka — modely uživatelů, c) teorie jazykového učení — modely učení. I když zde stále chybí podstatná složka lingvistické teorie — teorie jazykového vývoje, může být toto rozčlenění dobrým východiskem pro další úvahy. Nás v této souvislosti zajímá pouze vztah mezi teorií jazykových schopností a teorií užívání jazyka. J. J. Katz (o. c. v pozn. 11, s. 1—7) nazývá první teorii lingvistický popis, druhou, zahrnující teorii kódování a dekódování jazykových sdělení, teorií jazykové komunikace. Zároveň Katz načrtává schéma lingvistického popisu a z něho vycházející schéma jazykové komunikace. Schéma lingvistic[233]kého popisu se skládá ze tří složek: syntaktické, sémantické a fonologické. Syntaktická složka má generativní sílu a generuje řetězce čistě formálních elementů, tzv. formativů. Sémantická složka provádí sémantickou interpretaci těchto řetězců, fonologická složka jim přiřazuje zvukovou reprezentaci.
Schéma jazykového kódování bude zobrazením vstupní etapy jazykové komunikace, tj. bude totožné se schématem mluvčího M. Zopakujme zde, že bude obsahovat minimálně tyto bloky: (A) blok pojmenování, (B) blok usouvztažnění (gramatické syntézy), (C) blok stylistického výběru, provádějící výběr z množiny alternativ jednak denotátů, jednak syntaktických konstrukcí, (D) blok realizace (zvukové nebo grafické), který přiřazuje kódované výpovědi materiální reprezentaci.
Schéma zařízení M musí mít dále minimálně tři vstupy: 1. vstup z množiny událostí, 2. vstup z bloků lingvistického popisu LD (z pravidel jazyka), 3. vstup z množiny mimojazykových podmínek kódování Q působících v daném komunikačním okruhu. Bloky A, B, D jsou spojeny s příslušnými bloky schématu lingvistického popisu, blok A má nadto vstup z množiny událostí a blok C z množiny podmínek Q.
Jedním z cílů našeho příspěvku bylo prokázat, že schéma jazykového kódování musí obsahovat pragmatickou složku, tj. blok spojený s mimojazykovými podmínkami komunikace. Zdá se mi, že zde je jeden z podstatných rozdílů mezi schématem lingvistického popisu, které pragmatickou složku nemá, a schématem mluvčího, které se bez ní neobejde. Studium pragmatiky jazykové komunikace se tak postuluje stejně naléhavě jako studium syntaxe a sémantiky.
Celkové schéma popsaných zařízení (blok realizace je pro zjednodušení vypuštěn):
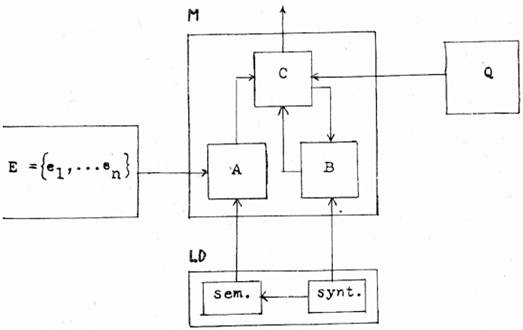
Je evidentní, že jedním z nejsložitějších problémů lingvistické teorie je vztah mezi zařízením M (schématem mluvčího) a systémem LD (schématem lingvistického popisu) (což je nová formulace vztahu mezi „langue“ a „pa[234]role“). V poslední době naznačili Miller a Chomsky zajímavou cestu k popisu těchto relací;[30] využívaje jejich podnětů, předpokládám, že zařízení M musí disponovat: 1. pamětí, v níž jsou uložena pravidla lingvistického popisu; 2. vlastní generativní schopností, která mu umožňuje generovat (produkovat) výpovědi; 3. zvláštním zařízením pro porovnávání (matching) výpovědí generovaných v M s větami generovanými pravidly LD. Má-li zařízení M vlastní generativní sílu, může přirozeně pravidla lingvistického popisu nejen respektovat, ale také modifikovat a přetvářet (popř. porušovat).[31] Nadto, což jsme se snažili prokázat v našem příspěvku, má zařízení M schopnost selekce, a tudíž výběru optimální varianty. Relativní samostatnost zařízení M a jeho selekční schopnost může vysvětlit nejen stereotypní formy komunikace, ale rovněž formy tvořivé, zejména komunikaci básnickou.[32] Tím se zároveň překonává jednostranný normativismus původní verze generativní gramatiky.[33]
Situace v lingvistické komunikaci byla nedávno přirovnána k situaci v uličním provozu, kde platí striktně určitá jednoznačná pravidla, ale provoz se v důsledku nejrůznějších faktorů vždy do určité míry od pravidel odchyluje. Zdá se mi, že analogie s šachovou hrou, které již kdysi k jiným účelům použili F. de Saussure a po něm G. A. Miller, je daleko výstižnější.[34] Šachová hra má rovněž přesně formulovaná a jednoznačná pravidla. Avšak těchto pravidel je možno využít tak, že vznikne partie buď zcela primitivní, anebo průměrná a stereotypní, anebo konečně partie originální a vysoce elegantní, v níž se může plně projevit tvůrčí potence velmistra. Stejně podstatné rozdíly shledáváme v jazykové komunikaci. Teorie přirozeného jazyka musí považovat vysvětlení těchto rozdílů za svůj přední úkol.
[235]R é s u m é
МОДЕЛЬ СТИЛИСТИЧЕСКОГО КОМПОНЕНТА ЯЗЫКОВОГО КОДИРОВАНИЯ
Статья представляет собой попытку моделирования стилевых различий в языковой коммуникации. Автор исходит из предпосылки, что стилевые различия возникают в процессе кодирования сообщений, а именно в компоненте выбора (селекции) оптимального варианта из множества альтернативных языковых элементов. Исходя из стилистики Пражской школы, автор различает объективные и субъективные факторы выбора, соответствующие классы сообщений, и наконец объективные и субъективные стили. Предполагается, что стилевые качества имеют статистический характер и выражаются стилевыми характеристиками (в основной форме распределениями частот альтернативных элементов). Учитываются два качества стилевых характеристик: стабильность и изменчивость по отношению к описанным классам сообщений, и стационарность — нестационарность на временной оси.
В качестве модели стилистического селектора предлагается вероятностный автомат определенный Рабином и другими авторами. Автомат порождает цепи символов из алфавита альтернатив А, которые характеризуются определенными распределениями вероятностей в зависимости от таблицы переходов автомата M (s, q). Эта формальная модель дает возможность определить стилистические параметры кодированных сообщений, причем стилевые характеристики считаются эмпирическим «образом» этих параметров.
В заключительной части дается краткое объяснение места предлагаемой модели в рамках синтетической лингвистической теории. Автор исходит из различения моделей языковых способностей и моделей языкового поведения. Модель селектора является компонентом модели говорящего (кодировщика). Тем самым постулируется включение прагматического компонента в модель кодирования языковых сообщений.
[1] C. E. Shannon, Communication in the Presence of Noice, PIRE 37, 1, 1949; W. Meyer-Eppler, Grundlagen und Anwendungen der Informationstheorie, Berlin-Göttingen-Heidelberg 1959.
[2] Rozlišíme-li s A. A. Reformatským (O perekodirovanii i transformacii kommunikativnych sistem, Issledovanija po strukturnoj tipologii, Moskva 1963, s. 208n.) dvojí typ kódování — tzv. „překódování“ a tzv. „transformaci“, pak proces jazykového kódování patří do druhého typu: jde o transformaci „systému“ mimojazykových „událostí“ (ve smyslu teorie informace) v sémiotický systém jazyka. Z toho důvodu nelze teorii jazykového kódování ztotožňovat s teorií „překódování“, jak je rozvíjena např. Schützenbergerem (viz výklad v studii N. Chomského - G. A. Millera Introduction to the Formal Analysis of Natural Languages, Handbook of Mathematical Psychology (ed. Luce - Bush - Galanter), New York 1963, sv. II, s. 277n.).
[3] B. Mandelbrot, Structure formelle des textes et communication, Word 10, 1954 (čes. překlad ve sb. Teorie, informace a jazykověda, Praha 1964, s. 136n.); viz též M. Bense, Theorie der Texte, Köln 1962, s. 70n. R. Moreau považuje za elementární jednotku jazykového kódování slovo zvětšené o určitou konstantu (Sur la distribution des formes verbales dans le français écrit, Etudes de linguistique appliquée II, Paris 1963, s. 65—88. Srov. též: „Když básník stylizuje verš, jsou pro něho z jistého hlediska základními kameny slova“ (J. Levý, Matematický a experimentální rozbor verše, Česká literatura 12, 1964, 182).
[4] K pojmu výpověď viz naposled Fr. Daneš, A Three-Level Approach to Syntax, Travaux linguistiques de Prague 1, Praha 1964, s. 229n. Rozlišení „výpovědi“ a „výpovědní události“ není myslím v teorii jazykového kódování nutné.
[5] V budoucnosti tu jistě bude možno využít prací z „teorie promluvy“, viz zejména: Vl. Skalička, Promluva jako lingvistický pojem, SaS 3, 1937, 163—166; L. Doležel, O stylu moderní české prózy, Praha 1960 (Úvod); Vl. Skalička, Syntax promluvy (enunciace), SaS 21, 1960, 241—249; K. Hausenblas, On the Characterization and Classification of Discourses, Travaux linguistiques de Prague I, 1964, s. 67—83.
[6] Množina E se považuje za zadanou působením faktorů, jež leží mimo lingvistickou kompetenci.
[7] Srov.: „V řadě případů (zřejmě ve většině případů) jedno a totéž označované (jeden a týž smysl) může být v jednom a témže kontextu vyjádřeno různými označujícími“ (A. B. Dolgopoľskij, Kategorija vida v russkom jazyke i verojatnostnyj charakter svjazi označajemogo s označajuščim, sb. Problemy strukturnoj lingvistiki, Moskva 1963, s. 267).
[8] Pojem výběru je ve stylistice běžný, viz např. J. Marouzeau, Précis de stylistique française, Paris 1950, 10n. a je používán k vysvětlení stylových rozdílů. V oblasti básnického jazyka, kde výběr alternativ může probíhat uvědoměle, jsou známy teorie básnického tvoření, v nichž je centrálním pojmem právě výběr optimální varianty (viz E. A. Poe, V. V. Majakovskij).
[9] Viz zejm. Obsahový rozbor současné angličtiny (vyd. J. Vachek), Praha 1961, s. 11n. a Řeč a sloh, sb. Čtení o jazyce a poezii, Praha 1942, s. 17n.
[10] Viz např. náznaky J. J. Katze v stati The Semantic Component of a Linguistic Description, Magdeburg 1964, s. 4 a zejména J. J. Katz - P. M. Postal, An Integrated Theory of Linguistic Descriptions, Res. Monograph No. 26, M. I. T., Cambridge (Mass.) 1964, s. 169n.
[11] Psycholingvistika je zaměřena více na studium procesu dekódování sdělení, protože ten je lépe přístupný jejím experimentálním metodám. Výzkumem procesů jazykového kódování se již delší dobu zabývá rakouská psycholingvistická škola (práce A. Busemanna, Ch. Bühlerové, O. Selze, A. Schlismannové aj.), jejíž výsledky jsou však u nás málo známy.
[12] K pojmům komunikační okruh a komunikační síť přirozeného jazyka viz mou stať Jazykověda a kybernetika, sb. Kybernetika ve společenských vědách, Praha 1965, s. 267—280. Tato stať je pokusem o spojení teorie „funkčních stylů“ s teorií komunikace a o nový výklad funkčních stylů pomocí pojmu komunikační okruh.
[13] Rozlišení subjektivních a objektivních „stylotvorných faktorů“ je v české stylistické tradici dobře známo, jeho počátky jsou však již značně starší, viz např. rozlišení psychologických a sociologických faktorů řeči u L. P. Jakubinského (O dialogičeskoj reči, sb. Russkaja reč I, Petrograd 1923, s. 96n.).
[13a] Srov. P. Suppes, Models of Data, Logic, Methodology and Philosophy of Science (Proceedings of the 1960 International Congress), ed. Nagel-Suppes-Tarski, Stanford 1962, s. 256.
[14] Viz B. V. Gnedenko, Kurs teorii verojatnostej, Moskva 1961, s. 335.
[15] Rozložení délky vět je „klasická“ stylová charakteristika, jejíž studium započal G. Udny Yule statí On Sentence-Length as a Statistical Characteristic of Style in Prose, Biometrica 30, 1939; kritické zhodnocení dosavadního výzkumu viz u H. Spang-Hanssena Sentence Length and Statistical Linguistics, sb. Structures and Quanta, Copenhagen 1963, s. 58—72.
[16] Podrobnosti budou uveřejněny v připravované studii Rozložení délky slov a délky vět v současné psané češtině.
[17] Podobný složitý obraz zjistila pro tzv. Busemannův koeficient F. Antoschová (Stildiagnostische Literaturuntersuchungen mit dem Aktionsquotienten, Wiener Archiv für Psychologie, Psychiatrie und Neurologie, B. III, 1953, seš. 2, s. 3—11).
[18] Odpovídal by mu takový výběr, při němž by určitý mluvčí stylizoval stejným způsobem jak báseň, tak oběžník, jak soukromý dopis, tak novinářský článek atd.
[19] Tyto dva předpoklady odpovídají pojetí stylistické selekce, jak je stručně vyloženo v stati V. V. Ivanova - V. N. Toporova K rekonstrukcii praslavjanskogo teksta, Slavjanskoje jazykoznanije (V meždunarodnyj sjezd slavistov, Doklady sovetskoj delegacii), Moskva 1963, zejm. s. 108n.
[20] Viz R. Duncan Luce, Individual Choice Behavior (A Theoretical Analysis), New York - London 1959, s. 3—4.
[21] K formalizaci pojmu gramatické synonymity viz L. Nebeský - P. Sgall, Vztah formy a funkce v jazyce (Pokus o axiomatizaci), SaS 23, 1962, 174—189.
[22] Postupujeme v podstatě podle Luce, ale modifikujeme jeho pojmy podle potřeb našeho modelu.
[23] N. I. Žinkin, Mechanizm regulirovanija segmentarnych i prozodičeskich komponentov jazyka i reči, čes. překlad ve sb. Teorie informace a jazykověda, s. 236n.
[24] Viz P. Garvin, Inductive Method in Semantic Analysis, Technical Note No. 6 (Thompson Ramo Wooldridge, Inc.), Canoga Park 1962.
[25] Viz W. A. Koch, On the Principles of Stylistics, Lingua 12, 1963, zejm. s. 414n.
[26] Teorie náhodných automatů je rozpracovávána teprve v posledních letech. Po podnětech J. von Neumanna, W. Ross-Ashbyho a J. A. Šrejdera se teorie konstituuje v statích: M. O. Rabin, Probabilistic Automata, Information and Control 6, 1963, 230—245; G. L. Arešjan - G. B. Marandžjan, O nekotorych voprosach teorii verojatnostnych avtomatov, Matematičeskije voprosy kibernetiki i vyčisliteľnoj techniki, Jerevan 1964, 73—81; K. Čulík, Analýza, minimalizace a syntéza pravděpodobnostních automatů (rukopis).
[27] Příkladem takového přístupu je práce Ch. E. Osgooda Some Effects of Motivation on Style of Encoding, sb. Style in Language (čes. překlad ve sb. Teorie informace a jazykověda, s. 273—281).
[28] Srov. J. V. Sačkov, Verajatnosť i jeje roľ v razvitii poznanija, Voprosy filosofii 1962, č. 5, s. 146.
[29] N. Chomsky - G. A. Miller, Introduction to the Formal Analysis of Natural Languages, cit. sborník, sv. II, s. 271.
[30] G. A. Miller - N. Chomsky, Finitary Models of Language Users, cit. Handbook of Mathematical Psychology, sv. II, s. 465n.
[31] V teorii generativní gramatiky se dnes velmi intenzívně uvažuje o vztazích mezi množinou „správně tvořených“ výpovědí a množinou výpovědí, které vykazují v různém stupni „gramatické odchylky“ (teorie „polovět“) — viz zejm. N. Chomsky, Degrees of Grammaticalness, sb. The Structure of Language. Readings in the Philosophy of Language (ed. J. A. Fodor - J. J. Katz), New Jersey 1964, s. 384—389; P. Ziff, On Understanding „Understanding Utterances“, ib., s. 390—399; J. Katz, Semi-sentences, ib., s. 400—416; S. R. Levin, Deviation — Statistical and Determinate — in Poetic Language, Lingua 12, 1963, 276—290.
[32] Výklad o stereotypní a básnické komunikaci viz v mém článku Pražská škola a statistická teorie básnického jazyka, Česká literatura 13, 1965, 101—113.
[33] Nikdy jsem netvrdil, jak proti mně uvádí P. Sgall (SaS 26, 1965, 85), že generativní gramatika je „modelem činnosti mluvčího, popř. její etapy“; naopak, kritizoval jsem ty tendence v generativní gramatice, které — explicitně nebo implicitně — ztotožňovaly generativní gramatiku s teorií chování mluvčího, tj. s teorií produkování konkrétních výpovědí. Tvrdil jsem však a budu i nadále tvrdit, že operace usouvztažnění v procesu jazykového kódování probíhá podle pravidel generativní gramatiky, tak jako je obecně chování M řízeno pravidly LD. Je ovšem třeba dodat, že generativní gramatiku chápu ve smyslu druhovém, tj. jako třídu syntetických modelů gramatiky přirozených jazyků (na rozdíl od třídy modelů analytických). Pro různé účely lze konstruovat různé systémy generativních gramatik, v nichž derivace nemusí nutně postupovat „od výběru určité větné stavby k výběru lexikálních jednotek“. Generativní gramatiku nelze v žádném případě ztotožňovat s jedním, třebas nejpropracovanějším generativním systémem.
[34] F. de Saussure, Cours de linguistique générale, Paris 19603, pass.; G. A. Miller, Language and Communication, New York 1951 (franc. překlad Language et Communication, Paris 1956, s. 147—150). Kritiku analogie pravidel jazyka a pravidel dopravy viz též u J. Ellise „Rules“, Probability and Delicacy, Linguistics 1, 1964, č. 6, s. 41—42.
Slovo a slovesnost, ročník 26 (1965), číslo 3, s. 223-235
Předchozí Ladislav Nebeský, Petr Sgall: Relace a operace v syntaxi
Následující Josef Tříška: Z poetiky a fabulistiky „moderního“ středověku
© 2011 – HTML 4.01 – CSS 2.1