
K syntaktickým rozdílům mezi psanými a mluvenými texty
Jan Průcha
[Články]
К синтаксическим различиям между письменными и устными высказываниями / Différences syntaxiques entre les textes écrits et les textes parlés
1. Úvod. V tomto článku předkládáme výsledky statistické analýzy rozdílů ve frekvenci typů syntagmat v několika psaných a mluvených textech současné spisovné češtiny. Navazujeme tím na naši předchozí práci,[1] z jejíhož materiálu a dat tato analýza vychází. Jejím účelem bylo ověřit, zda zjištěné rozdíly mezi texty dané různým využitím jednotlivých typů syntagmat jsou statisticky významné či nikoli. Jde přitom nejen o významnost rozdílů mezi jednotlivými texty zvlášť, ale především o rozdíly mezi třídami textů, mezi styly (tj. stylem projevů mluvených a stylem projevů psaných).[2]
Kvantitativní analýza se uplatňuje v studiu syntaxe různých jazyků a stylů zatím jen dosti omezeně a v studiu syntaxe mluvených textů se jí zatím téměř neužívá. Pokud jde o češtinu, je v této oblasti průkopnickou prací studie M. Dvořáčka a J. Hubáčka[3] přinášející základní kvantitativní charakteristiky syntaxe moderní české prózy. V této práci jsou publikovány četnosti výskytu několika větných typů (věty podle složitosti, členitosti a postoje mluvčího) v textech tří současných novel. Bohužel analýza zůstává na rovině popisné statistiky a zhodnocení rozdílů v zjištěných četnostech není provedeno. Detailnější a rozsáhlejší (pokud jde o zkoumaný materiál) statistickou analýzu výskytu větných typů v psaných textech různých stylů současné spisovné češtiny provedla M. Königová.[4] Ve vztahu k aktuálnímu členění zkoumal kvantitativně některé syntaktické jevy v češtině K. Pala.[5] Zejm. druhá z jeho cit. prací obsahuje důležité údaje o četnostech výskytu větných členů a jejich kombinací v různých pozicích vět odborných textů. Pro studium pořádku slov v češtině zjišťovala výskyt některých syntaktických jevů (zejm. kombinací subjekt-predikát-objekt) v odborných textech L. Uhlířová.[6] Dílčí poznatky pro kvantitativní studium syntaxe přinášejí práce M. Těšitelové ve vztahu k morfologické homonymii, E. Macháčkové o frekvenci spojek a J. Průchy o četnostech syntaktických slovních tříd v různých pozicích vět.[7]
Pokud jde o kvantitativní studium syntaxe mluvených projevů, v poslední době publikovali zajímavé práce bohemisté z Pedagogické fakulty v Ostravě. Je to jednak [277]práce A. Knopa a F. Krušiny[8] obsahující některé statistické údaje o syntaxi mluvených projevů mládeže (žáků, studentů a učňů), jednak práce F. Krušiny a J. Říhové,[9] která je rovněž součástí komplexního výzkumu mluveného jazyka několika generací v městském průmyslovém centru. (Data týkající se syntaxe jsou doplněna výsledky kvantitativní analýzy fonologické a tvaroslovné roviny mluvených projevů mládeže uvedené lokality — viz další studie sb. cit. v pozn. 9.) Frekvenci slovních druhů a speciálně adjektiv v mluvených projevech olomouckých obyvatel zkoumal Z. Kovalčík.[10] Jeho výsledky jsou o to zajímavější, že jsou porovnatelné s údaji o frekvencích slovních druhů v psaných textech obsaženými ve frekvenčním slovníku češtiny.[11] K cenným zjištěním těchto prací o syntaxi mluvených projevů se ještě vrátíme níže při interpretaci našich výsledků..
Analýza, jejíž výsledky zde uvádíme, má charakter pouze dílčího příspěvku ke kvantitativnímu studiu syntaxe mluvených a psaných textů, neboť je založena pouze na zkoumání elementárních syntaktických jednotek — typů syntagmat. Také pro poměrnou omezenost zkoumaného materiálu (i když pro danou úlohu statisticky reprezentativního, viz o. c. v pozn. 1) mají dosažené výsledky jen omezenou obecnou platnost.
Účelem analýzy bylo ověřit tuto hypotézu: Vedou-li rozdíly mezi styly projevů psaných a mluvených k diferencím v syntaxi textů psaných a mluvených, pak tyto syntaktické diference jsou způsobeny (mimo jiné) i významnými rozdíly ve využití syntagmat různých typů. V následující části objasňujeme způsob ověřování této hypotézy, výsledky a jejich zhodnocení.
2. Analýza. Způsob primární analýzy (zjištění četností typů syntagmat) je podrobně vyložen v naší dřívější práci (o. c. v pozn. 1); zde uvádíme jen základní údaje nutné pro interpretaci výsledků získaných v sekundární analýze, tj. testování významnosti rozdílů.
2.1 Zkoumaná jednotka. Jednotkou analýzy je syntagma (v pojetí závislostní syntaxe), tj. skupina dvou větných členů spojená jedním syntaktickým vztahem.[12] Syntaktické skupiny, které mohou být více než dvojčlenné (např. koordinační, apoziční) a syntagmata s více než jedním syntaktickým vztahem (např. determinační syntagma s doplňkem) mezi zkoumané jednotky nezahrnujeme. Tyto případy tvoří v našem materiálu asi 8 % všech syntaktických skupin. I když by bylo možno některé z těchto skupin převádět na binární vztahy, do souboru jsme pojali jen základní, přirozeně binární typy syntagmat. Toto jisté omezení vyplynulo především z primární analýzy, v níž byly pomocí kombinatorních matic detailně zkoumány struktury syntagmat jako binární kombinace různých syntaktických tříd slov (viz podrobněji o. c. v pozn. 1).
[278]2.2 Typy syntagmat. Rozlišujeme typy syntagmat podle tří kritérií:
2.21 Podle syntaktického vztahu: P (predikační syntagma), D (determinační syntagma), a to: D1 (determinační syntagma se vztahem vyjádřeným shodou), D2 (determinační syntagma se vztahem vyjádřeným tzv. silnou rekcí), D3 (determinační syntagma se vztahem vyjádřeným tzv. slabou rekcí), D4 (determinační syntagma se vztahem formálně nevyjádřeným).
Jako příklad uvádíme typy syntagmat v jedné větě ze zkoumaného materiálu (F. Hrubín, U stolu): Maminka opatrně rozestřela lesklý papír od homole cukru. — P (maminka rozestřela), D1 (lesklý papír), D2 (rozestřela papír), D3 (papír od homole), D3 (od homole cukru), D4 (opatrně rozestřela).
Pokud jde o typy determinačních syntagmat, za typ D2 byla považována syntagmata s rekčním vztahem daným pouze předmětem v bezpředložkovém akuzativu nebo genitivu (např. uviděl slunce), kdežto všechny ostatní případy rekce (např. dotkl se dlaní, rozestřela po stole) byly řazeny k typu D3. K typu D4 byla počítána všechna determinační syntagmata, v nichž není syntaktický vztah mezi členy formálně vyjádřen ani shodou, ani rekcí (např. rychle se vzdálil). Uvedené rozlišení bylo nutno provést pro nejednoznačnost vymezení tzv. silné rekce a slabé rekce z hlediska požadavků spojených se statistickým zpracováním materiálu.[13]
2.22 Podle vzájemného pořadí členů: a) syntagma prepozitivní (tj. s pořadím: člen řídící → člen závislý), b) syntagma postpozitivní (tj. s pořadím: člen závislý ← člen řídící).
2.23 Podle vzdálenosti členů: a) syntagma kontaktní (tj. mezi jehož členy nestojí žádný jiný člen v lineární posloupnosti větných členů), b) syntagma distantní (tj. mezi jehož členy stojí jeden nebo více jiných větných členů).
2.3 Materiál. Materiál tvoří soubory vět sestavené na základě náhodného výběru z těchto 4 textů: a) texty psané: F. Hrubín, U stolu (H), Učebnice fyziky pro 11. třídu (F); b) texty mluvené: 2 texty odborných referátů přednesených na seminářích matematické lingvistiky v ÚJČ ČSAV (podle magnetofonových záznamů — M1 a M2).
Rozsah (n) jednotlivých souborů: n(H) = 469 dvojčlenných syntagmat, n(F) = 470, n(M1) = 467, n(M2) = 475. Celkový rozsah zkoumaného materiálu je 1881 dvojčlenných syntagmat; pokud jde o reprezentativnost, bylo ověřeno, že materiál je statisticky reprezentativní (nikoli však pro jednotky s malými četnostmi výskytu, tj. jejichž relativní četnost p<0,020, což je v naší analýze zanedbatelné).
2.4 Testování rozdílů. Testování významnosti rozdílů mezi četnostmi typů syntagmat jsme prováděli pomocí těchto testů: χ2-test (test shody), F-test (test
| [279] Typ | H | F | M1 | M2 | Σ | ||||
| ni | pi | ni | pi | ni | pi | ni | pi | ||
| P | 67 (51,14) | 0,148 | 45 (50,98) | 0,090 | 47 (50,65) | 0,100 | 45 (51,52) | 0,094 | 204 |
| D1 | 92 (122,92) | 0,199 | 138 (123,18) | 0,331 | 137 (122,40) | 0,290 | 126 (124,49) | 0,264 | 493 |
| D2 | 73 (56,35) | 0,153 | 65 (56,47) | 0,134 | 41 (56,11) | 0,089 | 47 (57,07) | 0,096 | 226 |
| D3 | 172 (154,05) | 0,365 | 180 (154,42) | 0,363 | 134 (153,43) | 0,287 | 132 (156,06) | 0,283 | 618 |
| D4 | 65 (84,77) | 0,135 | 42 (84,95) | 0,082 | 108 (84,41) | 0,234 | 125 (85,86) | 0,263 | 340 |
| Σ | 469 | 1,000 | 470 | 1,000 | 467 | 1,000 | 475 | 1,000 | 1881 |
Tab. č. 1. Empirické a teoretické rozložení četností typů syntagmat v souboru H, F, M1 a M2
[280]významnosti rozdílů mezi dvěma rozpyly). A-test (test významnosti rozdílů mezi dvěma průměry).[14]
3. Výsledky. V tab. 1 jsou uvedeny absolutní (ni) a relativní četnosti (pi) typů syntagmat v zkoumaných textech, jejich průměry a rozytyly. Rozdíly v četnostech jsou dvojího druhu: (a) rozdíly mezi jednotlivými typy syntagmat v daném textu (např. v textu H představuje typ P 14,8 %, typ D1 19,9 %, typ D2 15,3 %, typ D3 36,5 %, typ D4 13,5 %); (b) rozdíly mezi jednotlivými texty u daného typu syntagmat (např. typ P tvoří v textu H 14,8 %, v F 9,0 %, v M1 10,0 %, v M2 9,4 %). Vzhledem k výše formulované hypotéze o stylových syntaktických diferencích mezi psanými a mluvenými projevy zaměřujeme se v dalším na testování rozdílů na rovině (b). Jde o to prokázat, zda tyto rozdíly jsou statisticky významné či nikoli.
Celkové zhodnocení významnosti rozdílů bylo provedeno pomocí testu χ2. Smysl tohoto testu spočívá v tom, že se porovnávají rozdíly mezi zjištěnými četnostmi (nij), a četnostmi očekávanými (oij), tj. četnostmi teoretického rozložení. Hodnoty tohoto teoretického rozložení jsou uvedeny rovněž v tab. I (v závorkách pod hodnotami absolutních četností). Testovací kritérium χ2 je definováno vztahem
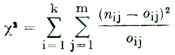
a má v = (k — 1) . (m — 1) stupňů volnosti. V našem případě je kritická hodnota χ20,05 = 21,0, přísnější hodnota na vyšší hladině významnosti χ20,005 = 28,3 pro v = 12 stupňů volnosti.
Ze srovnání je patrno, že χ2 = 80,7 > χ20,005 = 28,3,
tj. můžeme tvrdit, že testované rozdíly nemají charakter náhodný a jsou způsobeny vlivem stylových faktorů. Konkrétně řečeno: styl textu má signifikantní vliv na rozložení typů syntagmat.
3.2 Tento výsledek, sám o sobě průkazný, je ještě příliš obecný a nedovoluje ověřit naši hypotézu, že existují diference ve využití syntagmat různých typů v textech mluvených a psaných. Provedli jsme proto jemnější analýzu, a to tak, že jsme měřili významnost rozdílů mezi psanými texty (H a F) a mluvenými texty (M1 a M2) pomocí F-testu a A-testu. Oba testy byly aplikovány vždy dvakrát, a to jednak pro průměrné četnosti, jednak pro úhrnné četnosti. Výsledky těchto testů shrnuté v tab. 2 prokazují ve všech případech značnou nevýznamnost rozdílů v četnostech typů syntagmat mezi texty psanými a texty mluvenými. Vzhledem k tomu by bylo nutno naši základní hypotézu zamítnout, tj. museli bychom konstatovat, že psané a mluvené texty se neliší ve využití různých typů syntagmat.
Problém je však komplikovanější. Uvedenými testy byla sice spolehlivě zjištěna nevýznamnost rozdílů mezi psanými a mluvenými texty, ale bez zřetele k jednotlivým typům syntagmat. Tím se ovšem skutečné rozdíly vyrovnávají a výsledky testování tím ztrácejí smysl pro ověření naší hypotézy.
| [281]Test | Porovnání vypočtené hodnoty s kritickou hodnotou | Stupně volnosti | Významnost |
| F-test (pro průměrné četnosti) |
F = 1,80 < F0·025 = 9,60 |
v1, v2 = 4 |
ne |
| F-test (pro úhrnné četnosti) |
F = 1,94 < F0·025 = 9,60 |
v1, v2 = 4 |
ne |
| A-test (pro průměrné četnosti) |
A = 0,86 > A0·05 = 0,304 |
v = 4 |
ne |
| A-test (pro úhrnné četnosti) |
A = 1,89 > A0·05 = 0,304 |
v = 4 |
ne |
Tab. č. 2. Významnost rozdílů v četnostech typů syntagmat mezi psanými a mluvenými texty
Je tedy nutno provést jemnější analýzu na rovině jednotlivých typů syntagmat. Proto jsme testovali rozdíly v četnostech zvlášť pro každý z pěti typů syntagmat. Z výsledků shrnutých v tab. 3 (pro všechny texty) je patrno, že s výjimkou typu P se četnosti všech ostatních typů syntagmat významně liší. Nevýznamnost rozdílů u typu P je dána specifickou funkcí predikačního syntagmatu jako základního konstituentu větné struktury. Toto zjištění o nevýznamnosti rozdílů v četnostech syntagmatu typu P se shoduje s poznatky z ji-
| Typ syntagmatu | Porovnání vypočtené hodnoty s kritickou hodnotou | Stupně volnosti | Významnost |
| P | χ2 = 6,72 < χ0·05 = 7,8 | v = 3 | ne |
| D1 | χ2 = 16,96 > χ0·05 = 7,8 > χ0·005 = 12,8 | v = 3 | ano |
| D2 | χ2 = 11,96 > χ0·05 = 7,8 | v = 3 | ano |
| D3 | χ2 = 12,13 > χ0·05 = 7,8 | v = 3 | ano |
| D4 | χ2 = 30,81 > χ0·05 = 7,8 > χ0·005 = 12,8 | v = 3 | ano |
Tab. č. 3. Významnost rozdílů v četnostech jednotlivých typů syntagmat (pro všechny texty)
[282]ných výzkumů,[15] že predikační syntagma má v textech různých stylů relativně konstantní využití. Pokud jde o další typy syntagmat, ukazují se nejvýznamnější rozdíly u typů D4 a D1, významné jsou rozdíly i u typů D2 a D3.
Konečně jako poslední krok analýzy jsme testovali rozdíly v četnostech jednotlivých typů syntagmat (průměrné četnosti) zvlášť pro texty psané a texty mluvené. Výsledky shrnuté v tab. 4 ukazují, že nejvýznamnější rozdíl je u syntagmat typu D4, významné rozdíly jsou u typu D2 a D3, nevýznamné nejen u typu P, ale i u typu D1. Odchylka v četnosti syntagmat typu D1 v textu H (srov. tab. 1), která způsobila významnost rozdílů v četnostech tohoto typu pro všechny texty, jeví se tedy jako spíše náhodná než podmíněná faktory stylovými, tj. stylovými diferencemi mezi texty psanými a texty mluvenými.
| Typ syntagmatu | Porovnání vypočtené hodnoty s kritickou hodnotou | Stupně volnosti | Významnost |
| P | χ2 = 0,98 < χ0·05 = 3,8 | v = 1 | ne |
| D1 | χ2 = 1,10 < χ0·05 = 3,8 | v = 1 | ne |
| D2 | χ2 = 5,54 > χ0·05 = 3,8 | v = 1 | ano |
| D3 | χ2 = 5,96 > χ0·05 = 3,8 | v = 1 | ano |
| D4 | χ2 = 23,32 > χ0·05 = 3,8 | v = 1 | ano |
Tab. č. 4. Významnost rozdílů v četnostech jednotlivých typů syntagmat mezi texty psanými a texty mluvenými
Na základě zjištěných výsledků, především těch, jež uvádí tab. 4, můžeme tedy k naší výše uvedené hypotéze (1) zaujmout toto stanovisko: Hypotéza se potvrzuje, tj. syntaktické diference mezi texty psanými a mluvenými jsou dány rozdíly ve využití syntagmat různých typů; statisticky významné rozdíly v četnostech jsou však prokázány jen u některých typů syntagmat (D4, D3, D2), kdežto u dalších typů (P a D1) se rozdíly jeví jako nevýznamné.
Jako součást analýzy hodnotili jsme také ještě rozdíly mezi psanými a mluvenými texty z hlediska vzdálenosti členů syntagmat (syntagmata kontaktní a distantní) a z hlediska pořadí členů syntagmat (syntagmata prepozitivní a postpozitivní — viz zde 2.22 a 2.23). Jak ukazují hodnoty tab. 5, v psaných textech (H a F) mírně převažují prepozitivní syntagmata nad syntagmaty postpozitivními, v mluvených textech (M1 a M2) je poměr opačný. Tento rozdíl [283]mezi hodnotami psaných a mluvených projevů se však jeví podle A-testu jako nevýznamný. (A-test byl aplikován na průměrné četnosti reprezentující zkoumané texty psané a mluvené.)
Pokud jde o frekvence typů syntagmat podle vzdálenosti, ukazuje rovněž tab. 5, že ve všech zkoumaných souborech převládají kontaktní syntagmata, která představují zhruba 2/3 počtu všech syntagmat. Také zde byl výsledek testování významnosti rozdílů mezi texty psanými a mluvenými negativní.
| Typ syntagmatu | Text psaný | Text mluvený | ||
| H | F | M1 | M2 | |
| kontaktní distantní | 62,5 37,5 | 67,7 32,3 | 61,2 37,9 | 64,0 36,0 |
| prepozitivní postpozitivní | 52,2 47,8 | 58,8 41,2 | 48,8 51,2 | 49,9 50,1 |
Tab. č. 5. Četnosti typů syntagmat podle vzdálenosti a pořadí členů (hodnoty udány v procentech)
Vzhledem k prokázané nevýznamnosti rozdílů v obou případech lze konstatovat, že syntaktické diference mezi psanými a mluvenými texty nejsou zřejmě dány rozdíly ve využití kontaktních a distantních syntagmat,[16] ani ve využití prepozitivních a postpozitivních syntagmat.
Při interpretaci dosažených výsledků bude nás zajímat především vysvětlení zjištěného stavu. Jeden z možných způsobů výkladu vychází z analýzy statisticko-kombinatorních vlastností syntagmat. Protože zkoumané jednotky-typy syntagmat-jsou binárními kombinacemi syntaktických slovních tříd, můžeme zjištěné významné rozdíly mezi texty psanými a mluvenými ve využití některých typů syntagmat konfrontovat s rozdíly v četnostech syntaktických slovních tříd vytvářejících tato syntagmata. Jak jsme uvedli v tab. 4, nejvýznamnější rozdíl byl prokázán u syntagmat typu D4, jejichž komponentem je převážně syntaktické adverbium; pokusíme se o vysvětlení příčin rozdílů právě u tohoto typu syntagmatu. Podle našich zjištění (o. c. v pozn. 1) je frekvence syntaktického adverbia v psaných textech nižší (v H 7,4 %, v F 4,8 %) než v textech mluvených (v M1 11,7 %, v M2 13,4 %). Z tohoto hlediska se tedy odlišují texty mluvené od textů psaných. Vysoké četnosti syntaktických adverbií a tím také syntagmat typu D4 jsou zřejmě důležitými kvantitativními charakteristikami mluvených projevů. Toto zjištění se potvrzuje i v nedávné práci A. Knopa a F. Krušiny (o. c. v pozn. 8), kteří prováděli kvantitativní výzkum mluvených projevů mládeže různých věkových a sociálních kategorií. Z porovnání jejich údajů s našimi lze vyvodit, že čím je mluvený projev spontánnější a méně intelektuální, tím vyšší je v něm zpra[284]vidla frekvence adverbií a tím i syntagmat typu D4; z genetického aspektu je zajímavý poznatek, že v mluvených projevech dětí a mládeže nižšího věku jsou frekvence adverbií rovněž větší než v mluvených projevech starší mládeže a dospělých osob. To je potvrzováno i výsledky rozboru mluvených projevů v práci Z. Kovalčíka (o. c. v pozn. 10). Údaje citovaných autorů a naše výsledky můžeme porovnat se „základními“ daty, tj. s údaji frekvenčního slovníku češtiny (FS) (o. c. v pozn. 11) o frekvenci adverbií jednak ve skupině D (dramata), která se nejvíce blíží skutečným mluveným projevům, jednak celkově ve všech zkoumaných textech psané češtiny. Toto porovnání (viz tab. 6) ukazuje ve všech případech odlišnost textů mluvených a psaných, pokud jde
| Pramen | Knop—Krušina | Kovalčík | Náš materiál | FS | ||
| průměrná frekvence | 19,57 | 16,08 | 15,29 | 12,65* | 12,95 | 10,29 |
|
texty | spontánní mluvené projevy | spontánní mluvené projevy olomouckých občanů |
mluvené odborné referáty |
dramata | psané texty různých stylů | |
| žáků | studentů | |||||
Tab. č. 6. Frekvence adverbií v textech mluvených a psaných (hodnoty udány v procentech)
* Tato hodnota udává četnost syntaktických adverbií, tj. četnost adverbií jako slovního druhu je v těchto textech nepatrně nižší.
o frekvenci adverbií. Podobné porovnání frekvencí jiných slovních druhů v různých textech by mohlo ukázat další diference mezi texty mluvenými a psanými. V případě typů syntagmat a jiných syntaktických jednotek nejsou však dosud pro takové porovnání k dispozici ani základní údaje o jejich statistickém rozložení.
4. Závěr. Výsledky uvedené analýzy i všechny kvantitativní údaje týkající se syntaxe psaných a mluvených projevů považujeme mimo jiné za základ vytvoření nezbytných předpokladů pro studium psycholingvistické problematiky kódování a dekódování jazykových sdělení. V další práci půjde o ověřování, do jaké míry jsou různé syntaktické jevy a jejich kvantitativní vlastnosti (jako je např. frekvence větných vzorců, kontaktnost a distantnost syntagmat aj.) psycholingvisticky relevantní pro uživatele češtiny. Takové ověřování bude nutno zapojit do souvislosti s četnými psycholingvistickými výzkumy vlivu gramatické stavby v kódování a dekódování, které se v posledních letech provádějí velmi intenzívně.[17]
[285]Pokud jde přímo o typy syntagmat a jejich „chování“ v procesech kódování a dekódování, je nutno upozornit na práci I. M. Luščichinové.[18] Autorka zjišťovala četnosti typů syntagmat v ruských uměleckých a odborných textech a experimentálně prokázala značné rozdíly v dekódování jednotlivých typů. Nejnověji např. Matthews[19] prokázal experimentálně specifickou úlohu syntaktických struktur obsahujících adjektivální komponent v dekódování vět.
Bylo by možno uvádět ještě další příklady, z kterých je patrno, že kvantitativní charakteristiky syntaxe jsou nezbytným analytickým předpokladem pro explikaci kódovaní a dekódování jazykových sdělení. Prozatím dosažené výsledky svědčí o závažnosti studia těchto charakteristik jak pro lingvistickou teorii, tak pro některé aplikace, zejm. jazykové vyučování.
R É S U M É
Syntactic Differences between Written and Spoken Texts
The paper presents the results of statistical analysis of the frequency of syntagmatic types in written and spoken texts of the present-day standard Czech. The analysis is aimed at the verification of the following hypothesis: If the differences between styles of written and spoken messages result in syntactic differences between messages, then these syntactic differences are caused (beside other factors) by significant deviations in the utilisation of various syntagmatic types.
The unit of analysis is syntagma (so-called pair of sentence parts in the sense of dependency syntax). Different types of syntagmas are distinguished according to the following criteria: (a) according to syntactic relation: P (predicative syntagma), D1 (determinative syntagma with grammatical agreement between members of syntagma), D2 (determinative syntagma with strong government), D3 (determinative syntagma with weak government), D4 (determinative syntagma with a formally unexpressed syntactic relation); (b) according to the ordering of members: prepositive syntagma (ordered: governing member — subordinate member), postpositive syntagma (ordered: subordinate member — governing member); (c) according to distance of members: contiguous syntagma (no other member is placed between its members), distant syntagma (one or more members are placed between its members).
The material for analysis containes sentence samples of two written texts (prose and scientific text) and two spoken texts (scientific lectures). The size of material is 1881 two-member syntagmas. The significance of differences between frequencies of syntagmatic types (see Tab. 1—4) was tested by means of χ2-test, F-test and A-test.
The results show that the style of text significantly influences the distribution of syntagmatic types — the hypothesis is thus confirmed. Statistically significant differences in frequencies have been ascertained, however, only in some types of syntagmas (D4, D3, D2); in other types (P, D1) they are insignificant. Also the utilisation of contiguous and distant syntagmas, prepositive and postpositive syntagmas reveals only insignificant differences for spoken and written texts. The comparision [286]of the results obtained with results of other authors (cf. note 8 and 10) and with the “basic“ data from the frequency dictionary of Czech (cf. note 11) shows that the high frequency of adverbs and consequently of D4 syntagmas is one of the quantitative characteristics of spoken texts (see Tab. 6).
[1] J. Průcha, Častota tipov sintagm v pis’mennych i ustnych tekstach, Prague Studies in Mathematical Linguistics 3 (v tisku).
[2] Viz zvl. K. Hausenblas, O studiu syntaxe běžně mluvených projevů, sb. Otázky slovanské syntaxe, Praha 1962, 313—323 a jiné příspěvky v tomto sborníku.
[3] M. Dvořáček—J. Hubáček, Frekvence větných typů v současné české novele, Sborník prací Pedagogického institutu v Ostravě, řada jazyk-literatura-umění č. 5, 1964, 17—38.
[4] M. Königová, On statistical dependence in syntax, Prague Studies in Mathematical Linguistics 3 (v tisku).
[5] K. Pala, O nekotorych problemach aktual’nogo členenija, Prague Studies in Mathematical Linguistics 1, Praha 1966, 81—92; týž, Otnošenije meždu porjadkom slov i aktual’nym členenijem v češskom jazyke, ib. 2, Praha 1967, 51—64.
[6] L. Uhlířová, Statistics of the word order of direct object in Czech, Prague Studies in Mathematical Linguistics 2, Praha 1967, 37—49.
[7] M. Těšitelová, O morfologické homonymii v češtině. Rozpravy ČSAV. Roč. 76, seš. 8, Praha 1966, zvl. s. 28—29 aj.; E. Macháčková, Spojky podřadicí v českých matematických textech, SaS 24, 1963, 38—47; J. Průcha, On word-class distribution in Czech utterances, Prague Studies in Mathematical Linguistics 2, 1967, s. 65—76.
[8] A. Knop —F. Krušina, Poznámka k výzkumu mluvené řeči ostravské mládeže, ČJL 18, 1967—68, 85—90.
[9] F. Krušina—J. Říhová, Poznámky k syntaxi běžně mluvených projevů nejmladší generace města Ostravy, Sborník prací Pedagogické fakulty v Ostravě, řada D-3, č 11, 1968, 59—75.
[10] Z. Kovalčík, Frekvence adjektiv v mluvených projevech, Sborník Pedagogické fakulty University Palackého v Olomouci, Jazyk a literatura, 1966, 19—25.
[11] J. Jelínek—J. V. Bečka—M. Těšitelová, Frekvence slov, slovních druhů a tvarů v českém jazyce, Praha 1961.
[12] Srov. B. Havránek—A. Jedlička, Česká mluvnice, Praha 1960, zvl. s. 281 až 283.
[13] Nejednoznačnost vyplývá zejm. z toho, že se slabá a silná rekce odlišuje především na základě sémantického vztahu, v jehož klasifikaci se užívá převážně intuitivního kritéria, viz např. J. Popela, Příspěvek k základním syntaktickým vztahům a k syntaktickým prostředkům, Bulletin VŠRJL IV, Praha 1960, 109—130 a P. Adamec, Porjadok slov v sovremennon russkom jazyke, Rozpravy ČSAV 76, Praha 1966. — Pro odstranění uvedené nejednoznačnosti by mohl mít zásadní význam Apresjanův pokus o rozlišení silné a slabé slovesné rekce na základě pravděpodobnostních charakteristik valence a síly řízení slovesem, viz J. D. Apresjan, O sil’nom i slabom upravlenii (Opyt količestvennogo analiza), VJaz 13, 1964, č. 3, s. 32—49.
[14] Použité testy jsou popsány v běžných příručkách, např. R. Reisenauer, Metody matematické statistiky, Praha 1965.
[15] Srov. pro češtinu nepublikované výsledky L. Uhlířové (podle ústního sdělení).
[16] Srov. však tzv. koeficient vzdálenosti (o. c. v pozn. 1), jehož hodnoty pro jednotlivé texty naznačují různý stupeň nerovnoměrnosti ve využití kontaktních a distantních syntagmat; otázka zůstává tedy dále otevřena.
[17] Viz zvl. sb. Directions in Psycholinguistics, ed. S. Rosenberg, New York — London 1965 a Psycholinguistics Papers, od. J. Lyons — R. J. Wales, Edinburgh 1966. Stručný přehled je též u A. A. Leonťjeva Psicholingvistika, Leningrad 1967 (viz recenzi v SaS 29, 1968, 430—433). — O rozdílných závěrech o úloze transformační gramatiky v dekódování anglických a ruských vět viz v naší zprávě o psycholingvistické konferenci v Moskvě (1968), SaS 30, 1969, 100—102.
[18] I. M. Luščichina, O sootnošenii ustojčivosti i pomechoustojčivosti slovosočetanij, Problemy obščej social’noj i inženernoj psichologii, Leningrad 1966, 103—106 a Zavisimosť audirovanija ot organizacii rečevogo materiala, ib., 107—113.
[19] W. A. Matthews, Transformational Complexity and Short Term Recall, Language and Speech 11, 1968, 120—128.
Slovo a slovesnost, ročník 30 (1969), číslo 3, s. 276-286
Předchozí Marie Těšitelová: K frekvenci pádů v současné spisovné češtině
Následující Josef Skácel: K pojetí funkce kontaktního komunikačního okruhu z hlediska sociolingvistického
© 2011 – HTML 4.01 – CSS 2.1