
O frekvenčním slovníku slovenštiny
Marie Těšitelová
[Rozhledy]
О частотном словаре словацкого языка / Sur le Dictionnaire de fréquence du slovaque
K nemnohým frekvenčním slovníkům pro slovanské jazyky přibyl v nedávné době frekvenční slovník jazyka slovenského J. Mistríka Frekvencia slov v slovenčine.[1] Pro československou lingvistiku, zejm. pro lingvistiku kvantitativní, má tento slovník zvláštní význam ještě v tom, že se v něm českému frekvenčnímu slovníku[2] dostává potřebného protějšku; dnes máme tedy pro oba naše jazyky základní díla lexikální statistiky, která mohou být základem i potenciálním zdrojem mnoha dalších prací z nejrůznějších oborů, zvl. v oblasti lexika, stylistiky i gramatiky, a to jak pro jednotlivé jazyky, tak i z hlediska porovnávacího. FSS má nadto výhodu v tom, že se poučil ze zkušeností jak domácích, tak i zahraničních v daném oboru, takže možno o něm prohlásit, že vzhledem k době posunul problematiku studia frekvence slov opět o významný kus kupředu.
Kladem slovníku především je, že se v základních otázkách lexikální statistiky nerozešel významněji s FSČ, což je nezbytným předpokladem pro porovnávací studium obou jazyků. Platí to zejména v chápání základní jednotky — slova, v podstatě grafické jednotky textu, o zaznamenávání druhu slov i morfologických kategorií. Ale důsledné chápání slova jako grafické jednotky ve FSS vede k tomu, že se složený tvar slovesný typu bol by som šiel počítá za čtyři samostatné jednotky (jako čtyři slova, kdežto ve FSČ jako slovo jedno, jeden slovní tvar, jedna jednotka). I když se jednotlivé části složených tvarů slovesných zaznamenávají v závorkách, je toto pojetí příliš mechanické a vzhledem k velkému počtu sloves o relativně velkém počtu složených tvarů slovesných (v češtině např. představují asi 46 % všech slovesných tvarů) značně ovlivňuje i počet slov ve FSS. Stejný důsledek má i uplatněná zásada, že se komparativy a superlativy adjektiv a adverbií přiřazovaly k pozitivům. Ve FSČ se uvádějí (a ovšem i počítají) samostatně pozitivy a samostatně komparativy, k nimž se připojují superlativy; ovšem i tento způsob je možno kritizovat. Uvedené rozdíly se zejména projeví při uvádění druhů slov. Totéž platí např. i o převádění slovesných substantiv k slovesům, jak to dělá FSS (FSČ je uvádí jako substantiva a je jich nemálo, zejména v odborných textech, srov. ve frekvenci vz. stavení 11,82 %, v textech odborných 17,33 %) apod.
[66]Stejně významným problémem jako vymezení slova je pro frekvenční slovníky i výběr textů; spolurozhoduje o tom, zda studujeme frekvenci slov v jazyce vůbec anebo jen ve vybraném materiálu, ve vybraných textech, což souvisí také s cílem, který si při lexikální analýze klademe. Pro J. Mistríka představuje frekvence slov v jazyce signály, „ktoré naznačujú pomery v parolovej a langovej sfére“ (s. 47). Podle našeho názoru zdůraznili bychom více význam funkčního stylu a tematiky (o tom ale dále). Celkem ve shodě s FSČ bylo v původním plánu FSS pojmout do výběru textů 7 stylových skupin vybraného materiálu (jako ve FSČ i uměleckou literaturu pro mládež, populárně vědeckou literaturu a vědeckou literaturu, nikoli však skupinu tzv. mluvených projevů, skup. 8); v průběhu práce došlo k omezení na 5 stylových skupin:[3] (1) dialogy, tj. dramata (10,53 % materiálu), (2) umělecká próza (30,17 %), (3) poezie (13,22 %), (4) žurnalistika (14,58 %), (5) naučná literatura (31,50 %). Dramata tu zřejmě zastupují — podle našich zkušeností dobře — mluvené projevy, i když dnes, pokud jde o zastoupení mluvených projevů při sestavování korpusu frekvenčního slovníku, měli bychom být náročnější a do korpusu mluvené projevy zařadit.
Do textů pro FSS bylo pojato celkem 60 textů, a to umělecký styl z let 1922—1966 (pro FSČ je v zásadě toto rozpětí 1930—1950), pro žurnalistiku 1964—1966, pro odborné texty zejm. 1947—1966. Pro daný slovník je to jistě značné časové rozpětí a nemůže být nedotčen politickým i hospodářským děním tohoto údobí v životě Slovenska i Československa. Autor sice klade důraz na slova relativně nejvíce i více frekventovaná a podmíněnost tematikou vidí tu značně omezenou. Avšak např. v odborných textech pronikají slova podmíněná tematikou i mezi slova relativně velmi frekventovaná (srov. např. ve FSČ slovo motor 701-6-17, ve FSS 43-5-16; ve FSS slovo vojna 444-5-37, ve FSČ válka 582-8-54 apod.).
Pokud jde o výběr textů pro frekvenční slovník, je podle mého názoru ve FSS problém v tom, že se od některých autorů (např. od J. Soloviče, J. Smreka apod.) volilo více textů. Náleží-li z 12 textů poezie 5 J. Smrekovi (téměř jedna šestina materiálu poezie), nelze tu nespatřovat silné vlivy jednotlivých autorů na celkový výběr textů. Vzhledem k speciálnímu slovníku textů lidové slovesnosti považuji za problematické zařazení těchto textů do korpusu.
Další závažnou otázkou, jejíž řešení rozhoduje o výsledcích statistické analýzy lexika, je rozsah textů do korpusu pojatých.
Celkový počet slov, o něž se FSS opírá, je 1,000.000 slov, která byla získána excerpcí 60 celých textů (FSČ obsahuje 1,623.527 slov z 75 textů). Tím se ovšem pracuje se souborem textů o nestejné délce N; to má své nevýhody v tom, že je často nesnadné rozlišit, kdy je daná charakteristika podmíněna délkou textu nebo jiným činitelem. Eliminace vlivu délky textu je pak většinou velmi nesnadná. Na druhé straně tím, že se pracuje s celými texty, disponuje FSS soubory (ev. podsoubory) materiálu, o němž lze říci, že reprezentuje lexikální strukturu daného textu;[4] takového materiálu možno využít ovšem ke studiu slovníku jednotlivých autorů. Zmíněné klady a nedostatky týkající se rozsahu textů najdeme i ve FSČ.
Také při volbě koeficientů pro jednotlivé lexikální jednotky doplnil a zpřesnil J. Mistrík dosavadní postupy; známé údaje z FSČ, tj. absolutní četnosti, počet stylových skupin, počet textů a údaje o distribuci v nich, doplnil o údaje Juillandovy, o disperzi, rozptýlení slov (o. c. v pozn. 3) a dále o údaje o relativní frekvenci f = f. D. I když tyto koeficienty jsou podle autora přesnější, v dané [67]podobě znesnadňují kontrolovatelnost a porovnávání s češtinou. — Výklad o všech zmíněných základních otázkách FSS spolu s přehledem nejznámějších prací o frekvenci slov, v němž se přehledu z FSČ dostává dovedení téměř do současnosti, tvoří náplň první, tzv. informační části práce (s. 11—43).
Druhá část, označená jako teoretická (s. 45—91), je pěkným dokladem toho, co ukazuje a může ukázat statistická analýza lexika. Autor tu rozlišuje v slovníku a v textu rozložení slov a) vertikální, b) horizontální. Rozložení vertikální, které je podle Mistríka podmíněno aspektem frekvenčním a sémantickým, dělí slovní zásobu na čtyři skupiny slov, a to slova: (1) konstrukční (K), k nimž řadí slova gramatická (předložky, spojky, pomocná slovesa byť a mať, zájmena odkazovací ten, ktorý; (2) subjektivně situační (S): modální slovesa, zájmena a zájmenná příslovce, částice, citoslovce a příslovce; (3) gnómická (G): číslovky, některá okolnostní a pod. příslovce, substantiva, adjektiva a slovesa plnovýznamová se širokým významem; (4) tematická a odborná (T): substantiva, adjektiva a slovesa.
Podle mých zkušeností jsou celkem nesporné první dvě skupiny, ať už je nazveme jakkoli; pokud jde o skupinu třetí (gnómická slova), pokládám tu za problematickou zejména kategorii číslovek, jejíž zastoupení je i u velkého materiálu (ať už FSS nebo FSČ) značně nahodilé, závislé na tematice a na chápání např. složených číslovek. Číslovky vůbec představují speciální kapitolu v lexiku, zvláště pak při lexikální analýze. Pokud jde o skupinu čtvrtou, je třeba podle mých zkušeností z lexikální statistiky (zejména u jednotlivých textů) rozlišit dvě skupiny slov tematických a odborných, a to (1) slova relativně velmi frekventovaná, která se týkají tématu samého (např. motor v pojednání o spalovacích motorech, model při pojednání o modelech v lingvistice apod.) a pronikají mezi slova relativně velmi frekventovaná, a (2) slova středně, ev. málo frekventovaná, která se k hlavní tematice přidružují, popř. volně s ní souvisí, např. matematický, algebraický, aparát, konfigurace apod., máme-li nějaké odborné téma o modelování v lingvistice. Slova s nízkou a nejnižší frekvencí mají svou vlastní problematiku;[5] k těmto otázkám se v našem časopise ještě vrátíme. — Jistá pásma slov tu nesporně existují, jejich hranice jsou však vágní a jsou do značné míry podmíněna mnoha činiteli, funkčním stylem, formou projevu apod.; problémem je potom vymezení jejich množin, s nimiž autor pracuje.
Horizontálním rozložením slov rozumí autor řazení slov v textu vedle sebe; soustřeďuje se při tom zejména na vztah délky textu N k jeho slovníku V (autor však pracuje se symbolem L, kterého Guiraud sice také užívá, ale v ne dost jasném smyslu „normálního“ lexika, vedle V, tj. počet různých slov, vocabulaire).[6] Vedle Guiraudovy míry pro tzv. bohatství slovníku (srov. i o. c. v pozn. 6), rozsahu R, disperze D a koncentrace C uvádí J. Mistrík i svůj index kompaktnosti textu (v jeho terminologii gravitnosti textu)
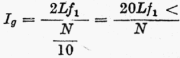
a index exkluzívnosti jednotlivých slov (týká se slov s frekvencí 1)
![]()
a variabilnosti
![]()
[68]Je třeba ocenit, že autor počítá s tím, že všechny hodnoty uvedených charakteristik závisí na mnoha činitelích, především na délce textu. — Pozornost věnuje autor i stylistickému zabarvení slov; i přes zjištění, že tu jsou rozdíly ve frekvenci slov vzhledem k jejich závislosti na tematice, podmíněné dobou i jinými činiteli, je autor přesvědčen, že slohová vrstva se může exaktně vyčlenit, ale že je třeba její pojetí revidovat, vzhledem k mnoha činitelům, které se při jejím vymezení uplatňují.
V třetí části, nazvané opisná, se J. Mistrík soustředil na distribuci slov ve FSS; pokouší se kvantitativně vyčlenit jádro slovní zásoby, které podle něho tvoří slova, která se vyskytla ve všech pěti stylových skupinách. Celkem je to 2 573 slov, jejich úplný seznam je tu rovněž uveden (s. 114—124). Autor k tomu došel — podle mého názoru — užitečnou analýzou, kolik slov je společných v jednotlivých dvojicích skupin, např. v druhé skupině je 19 130 slov, v třetí skupině 13 689 slov, z toho společných 8 230 slov, apod. O vhled do sémantických otázek při kvantitativní analýze slovníku pokouší se autor uváděním statistických dat o protikladných výrazech (např. adj. velký 1484 — malý 728) apod.; kvantifikaci výrazů pro světové strany, číslovky apod. (např. v slovenštině a češtině má prý největší frekvenci slovo západ, v ruštině a v němčině slovo východ, v angličtině, francouzštině a španělštině sever) pokládám za náhodnou a závislou na výběru materiálu (ve větší míře, než podle mého názoru autor předpokládá).
Po třech uvedených částech následuje jádro práce: (1) frekvenční slovník slovenštiny (s. 131—275), (2) abecední slovník s údaji o frekvenci slov v slovenštině (s. 279—723).
Frekvenční seznam obsahuje celkem 9 568 lexikálních jednotek uspořádaných podle klesající frekvence, a to do frekvence 3 (FSČ obsahuje 10 000 lexikálních jednotek do frekvence 13-6-10). U každého slova je vedle koeficientu absolutní frekvence uveden i koeficient frekvence relativní (srov. výše); jako novum je tu dále to, že slovo provází jednak pořadové číslo, jednak tzv. rank (obvykle nazývaný poř. číslo); tato čísla souhlasí jen u slov s největší frekvencí. Při klesající frekvenci roste počet slov s touž frekvencí; v tom případě mají všechna tato slova stejný rank, ale různé pořadové číslo. Ačkoli se autor zmiňuje i o tzv. Zipfově zákoně r×f=C (rank slova násobený frekvencí je konstantní, s. 88n.), problematice většího počtu slov s týmž rankem pozornost nevěnuje, i když by se to v daném případě nabízelo. Kladem seznamu také je, že se po skupině deseti slov uvádí kumulativní relativní frekvence (tak skupině s posledním slovem odpovídá kumulativní relativní frekvence 97,33 %).
Abecední seznam obsahuje 21 823 nejfrekventovanějších slov v slovenštině, vyloučena jsou slova s frekvencí pouze v jediném textu (FSČ obsahuje 26 257 slov, vyloučena jsou slova s frekvencí 2 a 1). Každá lexikální jednotka je tu provázena 8 číselnými koeficienty: absolutní frekvence, počet stylových skupin, počet textů, distribuce v jednotlivých stylových skupinách (absolutní frekvence v skupině a počet textů), jako ve FSČ, navíc je tu předposledním údajem disperze a relativní frekvence (viz výše). — Jako doplněk jsou k slovníku připojeny seznamy 500 nejfrekventovanějších slov v angličtině, češtině (podle FSČ), francouzštině, němčině, polštině, rumunštině, ruštině a španělštině.
FSS je cenné a užitečné dílo, v němž se dobře obráží poslední období i dnešní stav bádání v oblasti lexikální statistiky. Ocenila bych zvlášť i obsáhlé úvodní části, v nichž autor jednak shrnuje svá vlastní studia v této oblasti, jednak aplikuje řešení badatelů jiných. Dobře tu ukazuje, jak cenný materiál frekvenční slovník přináší, i naznačuje, co z něho mohou vytěžit jiní. Stejně dobré frekvenční slovníky bychom potřebovali i pro jiné slovanské jazyky.
[1] Vydalo Vydavateľstvo Slovenskej akadémie vied, Bratislava 1969, 726 s.; dále jen FSS.
[2] J. Jelínek - J. V. Bečka - M. Těšitelová, Frekvence slov, slovních druhů a tvarů v českém jazyce, Praha 1961; dále jen FSČ.
[3] Srov. např. týž počet stylových skupin v slovnících Juillandových: Al. Juilland - E. Chang-Rodriguez, Frequency Dictionary of Spanish Words, Hague 1964 (srov. SaS 26, 1965, s. 273n); Al. Juilland - P. M. Edwards - I. Juilland, Frequency Dictionary of Rumanian Words, Hague 1965 (SaS 30, 1969, s. 188n.).
[4] Srov. M. Těšitelová, On the statistical choice of language material for the purposes of lexical analysis, Prague Studies in Mathematical Linguistics 4 (v tisku).
[5] Srov. M. Těšitelová, On the so-called vocabulary richness, Prague Studies in Mathematical Linquistics 3 (v tisku) a též v SaS 27, 1967, 421—426, zvl. s. 423n.
[6] Srov. též J. Mistrík, Matematičesko-statističeskije metody v stilistike, VJaz 1968, č. 3, s. 42—52.
Slovo a slovesnost, ročník 32 (1971), číslo 1, s. 65-68
Předchozí Petr Piťha: Harrisova kniha o matematických vlastnostech jazyka
Následující Jarmila Panevová: Nové svazky sborníku Mašinnyj perevod i prikladnaja lingvistika
© 2011 – HTML 4.01 – CSS 2.1