
Slovesa v oblasti hospodářské češtiny z hlediska kvantitativního
Helena Confortiová
[Rozhledy]
Глаголы в области экономического стиля чешского языка / Quantitative aspects of the Czech verbs from the sphere of economy
0. V tomto příspěvku uvádím některé výsledky z výzkumu sloves v hospodářské češtině z hlediska kvantitativního a srovnávám je s údaji uvedenými v tzv. frekvenčním slovníku češtiny (Jelínek - Bečka - Těšitelová, 1961) a v odborných textech technického zaměření (Bečka, 1973 a 1974).
Materiál vychází z 20 textů[1] z oborů, jimž se vyučuje na Vysoké škole ekonomické v Praze. Z každého textu jsem excerpovala prvních 500 sloves ze začátku. Slovesa reflexívní jsem přiřazovala k slovesům nereflexívním, ale při podrobném zpracování sémantickém i morfologickém jsem slovesa zvratná oddělovala od sloves nezvratných. Celkový korpus obsahuje 10 000 sloves (všech slovesných tvarů), z toho 1200 různých sloves, tj. 12 % z celkového korpusu. Toto poměrně nízké číslo ukazuje, že jde o soubor monotematický (z oblasti ekonomie), kde jednotlivé texty mají mnoho společných sloves.
1. Nejprve si všimneme rozdělení sloves podle frekvence. Slovesa dělíme podle M. Těšitelové (1974) na tři skupiny: (1.) slovesa s frekvencí nejvyšší (prvních 10 sloves), (2.) slovesa s frekvencí střední, (3.) slovesa s frekvencí nižší a nejnižší (s frekvencí 10-1).
1.1. Mezi prvních 10 nejfrekventovanějších sloves se v našem korpusu dostala slovesa: být, mít, moci, jít, musit, vytvářet (se), působit, znamenat, stát se, patřit. M. Těšitelová (1974) uvádí, že na prvních 10 nejfrekventovanějších sloves v textech stylu odborného připadá 32—34 % délky textu (N). V našem souboru je to číslo o něco nižší — 31,55 %. Je to dáno zřejmě specifikou analyzovaných textů, kde zjišťujeme velkou koncentraci slovníku (viz dále). V celkovém počtu různých sloves zaujímají v našem korpusu nejfrekventovanější slovesa 0,83 % slovníku (V).
Mezi deseti nejfrekventovanějšími slovesy nacházíme — jak zřejmo — kromě sloves gramatických (pomocných a modálních) i slovesa plnovýznamová. Zvláštní postavení má sloveso jít, kterého se užívá téměř výhradně jako synonyma k slovesu jednat se (ve spojení jde o) a je doloženo ve všech textech korpusu. Totéž platí o slovesech vytvářet (se) a znamenat, další slovesa se již ve všech textech nevyskytují. Zvláště překvapuje nízký výskyt u slovesa patřit, které je mezi texty nerovnoměrně rozloženo a jen díky vyšší frekvenci v několika textech (zvláště o RVHP a o operacích v zahraničním obchodě) se dostává mezi prvních deset nejčastějších sloves. Potvrzuje se tím, jak velký vliv na frekvenci lexikálních jednotek má tematika textu (Těšitelová, 1974).
1.2. Počínaje 11. slovesem v pořadí podle klesající frekvence se už objevují případy, kdy určitou frekvenci nemá pouze 1 sloveso, ale 2 slovesa, popř. více sloves. Nastává [126]tedy rozdíl mezi pořadovým číslem slovesa a jeho rankem (společným téže frekvenci, Těšitelová, 1977). Těšitelová (1974, s. 143—144) upozorňuje na skupinu sloves s frekvencí od 30 do 21 v odborných textech s tím, že čím více je text monotematický, tím více sloves patří do této skupiny. V našem souboru je to číslo ještě vyšší; jde celkem o 70 sloves. Dostávají se sem taková slovesa, o nichž bychom na první pohled řekli, že jsou běžná (dávat, ukázat, vidět, hledat, chtít, potřebovat, rozumět atd.; srov. FSČ).
1.3. Slovesa s frekvencí nízkou a nejnižší (10-1) jsou samozřejmě nejpočetnější, je jich celkem 1026: tvoří 28,57 % N a 85,5 % V. M. Těšitelová (1974, s. 141) uvádí, že v textech odborných na různá slovesa s frekvencí 1-10 připadá 91—94 % V. Naše číslo je značně menší; to znamená, že slovesa v oblasti hospodářské češtiny mají ve slovníku V relativně více jednotek v pásmu vysoké frekvence a v horní části frekvence střední. Projevuje se tu závislost na tématu a vysoký index opakování (8,3). Je známo, že u slov s frekvencí 1-10 můžeme konstatovat jistou pravidelnost v tom, že počet slov s frekvencí 1 je vyšší než počet slov s frekvencí 2 a ten vyšší než počet slov s frekvencí 3 atd. (tzv. Waringova-Herdanova formule; Muller, 1968). U sloves našeho souboru platí tato pravidelnost až na výjimku, že počet sloves s frekvencí 7 je nižší než počet sloves s frekvencí 8. Uspokojivý výklad nelze zatím podat.
M. Těšitelová (1974) zdůrazňuje, že zvláštní postavení ve slovníku má počet sloves s frekvencí 1. U plnovýznamových slov (mezi něž patří i slovesa) představuje minimálně 39 %, maximálně 66 % všech lexikálních jednotek. V našem korpuse slovesa s frekvencí 1 tvoří 37,25 % V. Odpovídá to konstatování Těšitelové, že počet slov s frekvencí 1 v slovníku textů odborných je vždy nižší než v textech stylu uměleckého. — Vysoký počet sloves s celkovou frekvencí 1, což znamená, že je jich použito jen u jednoho autora a jsou tedy pro něho či spíše pro text charakteristická, obsahují texty o zemědělství a o RVHP. Přitom nejde jen o slovesa specifická pro danou tematiku (v textu o zemědělství např. slovesa krmit, ochočit, vyhynout, zrát, v textu o RVHP slovesa dostihnout, předehnat, přetvořit, svrhnout, uhájit), ale slovesa běžná, např. chodit, jíst, počkat, bát se, litovat, zapomínat (srov. FSČ).
1.4. Zastavila bych se ještě u tzv. bohatství slovníku z hlediska kvantitativního. Všimneme si rozsahu slovníku, který je dán poměrem délky textu N ke slovníku V (OLS, s. 71), tedy:
![]()
V našem případě
tedy 17,16 %.
To souhlasí s „normou“ pro odborné texty (OLS, s. 73), podle níž rozsah slovníku R je tu roven 17 %.
Při zkoumání bohatství slovníku si všimneme také tzv. rozptýlení slovníku (disperze), které je dáno poměrem plnovýznamových slov s frekvencí 1-10 ke slovníku V (OLS, s. 71):
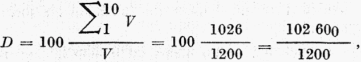
tedy 85,50 %.
V odborných textech podle OLS je průměrné rozptýlení slovníku 86 %. Naše výsledky toto zjištění potvrzují. Rozptýlení slovníku pokládá M. Těšitelová (1974) za charakteristiku, která má pro bohatství slovníku největší význam.
[127]Zastavíme se ještě u tzv. koncentrace slovníku, která je dána poměrem délky textu odpovídající prvním deseti nejfrekventovanějším slovům k délce celého textu N (OLS, s. 72).
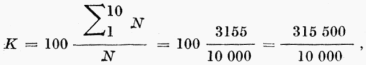
tedy 31,55 %.
V tomto případě se výsledek získaný z našeho korpusu značně liší od údaje uvedeného v OLS pro koncentraci slovníku v odborných textech (tj. 17 %). Mnohem vyšší výsledek pro koncentraci slovníku ukazuje, že tu jde zřejmě o jistou specifiku sloves v oblasti hospodářské češtiny podmíněnou tím, že velké procento sloves dosahuje frekvence vyšší a nejvyšší (srov. výše).
1.5. Sledujeme-li tabulku udávající, kolika různých sloves užil autor mezi prvními 500 slovesy, ukazuje se, že nejvíce různých sloves užívají autoři textů z oblasti hospodářských dějin, československé ekonomiky, úvěrové teorie a problematiky RVHP. V těchto textech se totiž v prvních kapitolách podává historický přehled po problematice, uvádějí se shody a rozdíly, tendence rozvoje apod.; je to pohled z širšího hlediska a potřebuje i více synonym. Nejméně různých sloves najdeme v textech týkajících se průmyslu, tržní spotřeby, operací v zahraničním obchodě a počtu pravděpodobnosti. V těchto textech jsou úvodní kapitoly monotematické. Vzhledem k celistvosti obsahové stránky a jednotné tematice se slovesa více opakují, jejich počet neroste.
Tím, že jsme excerpovali z každého textu 500 sloves, získali jsme sice stejně velké vzorky v jednotném korpuse, ale problém je v tom, že těchto 500 sloves bylo získáno z textů různé délky. Všimněme si proto toho, jak rozsáhlou část textu N potřebujeme, než dojdeme k pětistému slovesu. Zjistili jsme, že tato část textu se pohybuje v intervalu od 6947 do 3332 slov (rozdíl je více než dvojnásobný). Přitom ovšem velký počet všech slov v textu nemá vždy za následek velký počet sloves. Autor, který tvoří dlouhé věty, může vystačit i s menším počtem sloves; dějovosti dosahuje tím, že užívá substantiv nebo adjektiv verbálních. Někdy záleží také na počtu modálních sloves. Čím více je modálních sloves v textu, tím je menší rozsah textu N a počtu 500 sloves dosáhneme v kratším úseku textu. Určitý vztah existuje také mezi počtem různých sloves a výskytem slovesa být. Není jistě náhodné, že texty, které mají více různých sloves, mají méně výskytů slovesa být a naopak.
2. Při zpracovávání materiálu jsem si všímala i významu jednotlivých sloves. Vycházela jsem při tom ze Slovníku spisovného jazyka českého (1960—1971) a sledovala jsem, kolik významů má to které sloveso v SSJČ a kolika významů využívají autoři textů. Ukázalo se, že počet významů uvedených ve slovníku a počet významů užitých v textech se liší.
2.1. Došla jsem k zjištění, že zpravidla z několika významů, které uvádí SSJČ, se u většiny sloves v našem korpusu užívá pouze jednoho významu nebo dvou významů. Tak z 1309 sloves se 305 (tj. 23,30 %) vyskytuje pouze v 1 významu (jak jej uvádí SSJČ). Ze 2 nebo více významů uvedených v SSJČ se v našem korpuse objevuje v 1 významu 785 sloves, tj. 59,96 %, ve 2 významech 177 sloves, tj. 13,52 %, ve 3 významech 37 sloves, tj. 2,82 %. Celkem se tedy v 1-3 významech vyskytuje 1304 sloves, tj. 99,60 %, zbytek připadá na užití ve více významech (5 sloves, tj. 0,40 %).
2.2. Všimneme si skupiny sloves, u nichž SSJČ uvádí 2 významy nebo více. Sloves, u nichž SSJČ uvádí 2 významy, se vyskytuje v našem korpuse 288, tj. 22 %, z toho se pouze v 1 významu užívá 261 sloves, tj. 90,6 %, v obou významech 27 sloves, tj. [128]9,4 %. 3 významy uvádí SSJČ u 230 sloves (17,7 %), z toho bylo v našem materiálu v 1 významu doloženo 198 sloves, tj. 86 %, ve 2 významech 30 sloves, tj. 13 %, ve 3 významech 3 slovesa, tj. 1 %; dále je situace obdobná. Přitom slovesa, která se vyskytují ve 2 nebo 3 významech, se užívají hlavně v jednom z těchto významů, ve druhém nebo třetím významu jsou doložena méně často. Ve více významech než 3 se v našem korpuse vyskytuje jen 5 sloves: přijmout a stát (doloženy 4 významy), přijímat (doloženo 5 významů), mít a pracovat (doloženo 6 významů). Větší počet významů nepřekvapuje u slovesa mít, které je slovesem gramatickým, užívá se ho v různých funkcích, i když převažuje v našem materiálu význam vyjadřující stavy a vlastnosti (mít funkci, hodnotu, předpoklady, čas). Časté je také užití slovesa mít ve funkci modálního slovesa s infinitivem. — Sloveso pracovat se vyskytuje se jmény životnými i neživotnými; je slovesem celkem typickým i pro ekonomickou oblast a vyskytuje se tu v různých vazbách (pracovat na zahraničních trzích, pracovat s předpoklady, pracovat pro export).
2.3. Zastavíme se u nejčastějších významů některých nejfrekventovanějších sloves.
U slovesa být uvádí SSJČ 3 skupiny významů: sloveso (1.) významové, (2.) sponové a (3.) pomocné. Tuto třetí skupinu přiřazuji ve shodě s FSČ k jednotlivým slovesům (tj. složené tvary slovesné počítám jako jeden tvar a řadím je ke slovesům plnovýznamovým). Sledujeme-li frekvenci prvních dvou skupin podle doložení v mém materiále, zjišťujeme, že sloveso být jako významové sloveso se vyskytuje 174×, tj. 9,7 %, jako sponové sloveso 1620×, tj. 90,3 %. U slovesa být jako u významového slovesa uvádí SSJČ celkem 18 významů. V našem materiále je z nich doloženo pouze 6; nejčastěji význam ‚existence‘ a význam ‚pojmenování konkrétních činností nebo stavů, pobytu, zdržování se‘ (např. být v čele, v rozporu, v souladu, v zájmu apod.). — Sloveso být ve funkci spony se pojí buď se substantivem, nebo s adjektivem. Substantiva a adjektiva se tu vyskytují v poměru 8 : 7 (795 substantiv, 681 adjektiv). Substantiv se v našem materiále užívá ve jmenné části predikátu nejvíce v instrumentálu (667), adjektiv naopak v nominativu (679). Adjektivum ve jmenném tvaru se vyskytuje často (78,3 %) ve funkci tzv. modálního příslovce, kdy po něm následuje buď infinitiv, nebo věty uvozené spojkami že nebo aby (nejčastější je výskyt typu je možno vyrábět).
Sloveso mít je v mém materiále druhým nejfrekventovanějším slovesem; ve významu slovesa modálního se vyskytuje v 15 % případů. U slovesa mít převládá spojení s akuzativem (mít význam, charakter, úlohu, vliv atd.). Sloveso mít se vyskytuje průměrně 20× v textu, jako modální sloveso jen 3×.
Sloveso moci se v mém materiále vyskytuje průměrně 16× v textu. Velký výskyt zjišťujeme v textech o počtu pravděpodobnosti, účetnictví a úvěrování. Např. tématem prvních kapitol textu o pravděpodobnosti je kromě vysvětlení základních pojmů náhodný jev, pravděpodobnost a kombinatorika. V textu se píše o tom, co můžeme získat, stanovit apod., uděláme-li určitý úkon, mluví se o jevu, který může nebo nemůže nastat. V textu o účetnictví se např. mluví o tom, co může být hospodařící jednotkou a hospodařícím subjektem, co mají nebo mohou dělat pracovníci informačních soustav apod. V textu o úvěrování se píše např. o tom, co může dělat dlužník a věřitel apod.
Sloveso jít se zařazuje jako první plnovýznamové sloveso mezi slovesa nejvíce frekventovaná. Z 18 významů slovesa jít (v SSJČ) jsou v našem souboru zastoupeny jen 3, z toho téměř výhradně jen význam ‚jde oč, o koho, týká se něčeho, běží oč‘ (srov. jde o období, o činnost, o počet, o vývoj, o vztahy, o vazby atd.). Sloveso jít se tedy nevyskytuje ve svém vlastním či původním významu, nýbrž ve významu v podstatě přeneseném, který je pro výskyt slovesa jít v odborných textech typický.
Zatímco u modálního slovesa moci je rozdělení frekvence v textech do jisté míry rovnoměrné, u modálního slovesa musit tomu tak není. Jeho celková frekvence je [129]značně nižší než u slovesa moci (127 proti 326). Zřejmě vzhledem k tomu, že sloveso musit zahrnuje ve svém významu složku volní (rozkaz, příkaz), nenachází v odborných textech takové uplatnění jako např. v beletrii (srov. FSČ). Nejčastěji se vyskytuje v textech o úvěrování a počítačích, kde se mluví o tom, jak musí probíhat koloběh peněz, vyskytuje se v pokynech, jak se musí provést určité operace, apod.
Slovesa plnovýznamová se vyskytují v našem materiálu zpravidla v jednom významu. Sloveso vytvářet (se) s vysokou frekvencí 95-20[2] jako sloveso nezvratné má frekvenci 78-20, zvratné 17-10. Převážná část (až na výjimku) slovesa vytvářet se používá ve významu ‚záměrnou činností působit vznik něčeho‘ (vytvářet podmínky, předpoklady, základnu, možnost). — Sloveso působit (frekv. 76-18) má v našem materiále největší výskyt ve významu ‚vykonávat vliv na koho‘ (působit na přírodu, na pracovní předmět, na rozvoj). — Sloveso znamenat (frekv. 69-20) se 28× vyskytuje ve spojení … .znamená, že..‘. — Sloveso stát se (frekv. 66-18) se vyskytuje většinou ve funkci sponového slovesa a vyjadřuje změnu stavu. Přísudkové substantivum u slovesa je vždy v 7. pádě (55 %), přísudkové adjektivum v 7. pádě (13 %) nebo v 1. pádě (10 %). — Sloveso patřit má frekvenci 65-12; je — jak zřejmo — rozloženo nepravidelně, vyskytuje se v menším počtu textů (12). Naprostá většina v našem materiálu má význam ‚mít někde náležité místo; být účastníkem, členem něčeho (o osobě); být součástí něčeho (o věci)‘ (patřit zahraničnímu kapitálu, patřit minulosti, patřit k první skupině, patřit mezi pracovní prostředky).
3. Dále se zaměříme na frekvenci slovesných tvarů u sloves v oblasti hospodářské češtiny.
3.1. Co se týče kategorie osoby (a čísla), mají nejvyšší frekvenci (1.) 3. os. sg., (2.) 3. os. pl. a (3.) 1. os. pl. (Těšitelová, 1980), a to bez zřetele k času a způsobu (ve futuru se však vyskytuje stejně často 1. os. pl. jako 3. os. pl.). Tyto tři osoby jsou (až na výjimku) jedinými osobami, se kterými se v odborných ekonomických textech setkáváme. 1. os. sg. a 2. os. pl. se nevyskytují vůbec. Výjimečně nacházíme 2. os. sg. v imperativu (srovnej).
3.2. Sledujeme-li frekvenci časů, ukazuje se, že v našem materiálu má největší frekvenci (1.) čas přítomný (72,86 %), (2.) čas minulý (25,82 %) a (3.) čas budoucí (1,32 %). (Do futura jsem (ve shodě s FSČ) řadila jen formy futura složeného sloves nedokonavých (typu budu dělat) a futurum jednoduché sloves pohybových (typ půjdu), futurum sloves dokonavých jsem podle jeho formy počítala do prézentu). Rozložení časů je zřejmě specifické pro sloveso v hospodářské češtině (srov. Těšitelová, 1980, s. 117—118). I když je většina textů, o něž se opírám, psána v čase přítomném, má v některých textech významnou frekvenci čas minulý. Jsou to zejména texty s historickým zaměřením, např. text o vývoji československé ekonomiky, o hospodářských dějinách v ČSSR v 19. a 20. st., o financích v hospodářství v ČSSR a o RVHP a ČSSR.
3.3. Zjišťujeme-li frekvenci slovesného způsobu, jednoznačně převažuje indikativ (96,73 %). Podstatně nižší výskyt má kondicionál přítomný (2,93 %), zanedbatelný výskyt má imperativ (0,34 %) (jde v podstatě o 1. os. pl., a to více než v polovině dokladů v textu o pravděpodobnosti).
Z neurčitých tvarů slovesných zaujímá infinitiv skoro 13 % všech doložených slovesných tvarů. Jeho výskyt je podmíněn jednak užitím modálních sloves, jednak frekvencí modálních výrazů je třeba, lze, nelze, je nutné, je nutno, je možné, je možno apod. — Na okraji zůstávají ojedinělé výskyty přechodníku (přítomného) v textu o RVHP.
3.4. Zastavme se u frekvence slovesného rodu v našem materiále. Celkem tu zjišťujeme: tvarů aktivních 8677 (86,77 %), tvarů pasívních 1323 (13,23 %). Trpný rod — [130]jak známo — může být vyjádřen buď formou pasíva složeného, nebo pasíva zvratného. V odborných textech se užívá více pasíva složeného. V našem materiálu (1323 pasívních tvarů) připadá na složené pasívum 870 tvarů (tj. 65,76 %), na reflexívní pasívum 453 (tj. 34,24 %).
Za povšimnutí stojí fakt, že některá slovesa se vyskytují převážně v pasívu. Podle frekvence seřazena jde v našem materiálu o tato (nejčastější) slovesa:
| Pořadí | Sloveso | Absolutní frekv. pasíva v počtu textů | Celková frekv. slovesa v počtu textů |
| 1. | spojit | 31—12 | 32—13 |
| 2. | dát | 29—12 | 34—12 |
| 3. | určit | 18— 8 | 26—11 |
| 4. | podřídit | 18— 3 | 19— 4 |
| 5. | dosáhnout | 17— 8 | 51—14 |
| 6. | charakterizovat | 15— 8 | 31—13 |
| 7. | sepnout | 13— 8 | 14— 9 |
| 8. | řídit | 13— 7 | 35—11 |
| 9. | založit | 12— 7 | 13— 8 |
| 10. | podmínit | 11— 8 | 15— 8 |
Jak z tabulky vidíme, v některých případech (slovesa jsou vytištěna proloženě) má právě pasívum velký vliv na frekvenci slovesa vůbec. Není jistě náhodné, že většina těchto sloves patří mezi slovesa dokonavá.
4. Abychom mohli náležitě zhodnotit naše výsledky, srovnáme je s nějakou „normou“, ev. analogickou prací apod. (Těšitelová, 1977).
4.1. Za „normu“ v našem případě pokládáme jednak FSČ, zejména skupiny E a G (populárně vědecká a vědecká literatura), jednak TTZ. FSČ vychází samozřejmě z mnohem rozsáhlejšího materiálu, než je korpus našeho výzkumu. Čerpá z různých funkčních stylů českého jazyka, zatímco náš materiál je omezen na oblast hospodářské češtiny, tedy na odborné texty z nedávné doby (srov. výše), kdežto FSČ se opírá o texty vydané mnohem dříve v průběhu 20 let. A v jazyce, jako i v jiných oblastech našeho života, došlo v poslední době k rozmachu vědeckotechnické revoluce, která poznamenala písemný projev autorů posunem i v lexikální zásobě a přirozeně i ve frekvenci jejích jednotek. Toto všechno je třeba mít na zřeteli při interpretaci našich výsledků.
4.1.1. Porovnávala jsem nejprve prvních 50 sloves v mém materiálu a ve FSČ. (Srov. tabulku na konci článku.) Zjistila jsem, že společných je tu pouze 10 sloves: být, mít, moci, musit, jít, znamenat, stát se, vést, začít, dát. Jsou to tedy slovesa pomocná, modální a některá plnovýznamová, širokého významu, který zpravidla potřebuje nějaké doplnění. Porovnáme-li prvních 100 sloves ve FSČ a v mém materiálu, vzroste počet společných sloves na 20, přibývají tato slovesa: patřit, tvořit, dojít, odpovídat, platit, růst, ukazovat (se), činit, říci a pracovat. Jsou to většinou slovesa se širokým významem, která se zde neužívají zpravidla v původním, základním významu, ale v dalším, odvozeném, srov.: odpovídat ve významu ‚být ve shodě, v souladu s čím‘, platit ve významu ‚mít platnost‘, ukazovat se ve významu ‚jevit se‘.
4.1.2. Srovnávala jsem dále z hlediska FSČ, kolik sloves a s jakým umístěním v mém materiále se shoduje s prvními 50 nejfrekventovanějšími slovesy z FSČ. Tak 12 sloves z FSČ (z prvních nejčastějších 50) najdeme mezi prvními 100 slovesy v mém materiále; 14 sloves z FSČ mezi 300 slovesy; 17 sloves mezi ostatními slovesy mého materiálu; 7 sloves z FSČ v mém materiálu doloženo není. Jsou to slovesa, která [131]vyjadřují stav, vnímání a city člověka: slyšet, dívat se, sedět, cítit (se), věřit, smět a půjdu.
Docházíme tedy k závěru, že FSČ a texty z oblasti hospodářské češtiny mají málo společných nejfrekventovanějších sloves. (Jen 52 % nejfrekventovanějších sloves z FSČ najdeme v mém materiále mezi slovesy s vysokou a střední frekvencí.)
4.1.3. Vzhledem k mému specializovanému materiálu ukazuje se výhodnější srovnávat nejfrekventovanější slovesa nikoli s FSČ jako celkem, ale se skupinami E a G. Tak z celkového počtu 1200 sloves mého materiálu jich ve FSČ nacházíme 1049, tj. 87,4 %. Z tohoto počtu nacházíme hlavně nebo převážně ve skupinách E a G 824 sloves; ostatní slovesa (225) se více objevují v jiných skupinách FSČ. Vezmeme-li za základ 1049 sloves, můžeme konstatovat, že slovesa našeho korpusu se hlásí ve FSČ většinou do populárně vědeckých nebo vědeckých textů, poměr je 78,55 % (ve skupině E a G): 21,45 % (v ostatních skupinách).
Není bez zajímavosti všimnout si, že většina shodných sloves se vyskytuje v textech skupiny G (590 sloves). Se skupinou E se v mém materiálu shoduje celkem 234 sloves. Jejich poměr je 28,4 % (ve skupině E): 71,6 % (ve skupině G). Tedy většina sloves je typická právě pro vědecký jazyk; to jen potvrzuje specializovaný výběr materiálu v oblasti hospodářské češtiny. Největší frekvenci ve FSČ ve skupinách E a G mají tato slovesa, která se shodují s mým materiálem : tvořit (se), vznikat, stanovit, zjistit a působit.
Sloves, která nejsou ve FSČ doložena, je v mém materiálu celkem 151 (tj. 12,6 %); představují je více než z jedné třetiny (52) slovesa cizího původu, dvě třetiny (99) tvoří slovesa domácího původu nebo počeštělá.
Sloves s vyšší frekvencí, která jsou společná pro FSČ a můj materiál, jak zřejmo, je málo. Slovesa, která mají v mém materiálu velkou frekvenci, nacházíme také většinou ve FSČ ve skupinách E a G, zejména ve skupině G. Pokud se některá ze sloves mého materiálu ve FSČ nevyskytují, jsou to slovesa související s rozvojem vědy a techniky posledních let a slovesa specifická pro určitý obor ekonomické oblasti.
4.2. Srovnejme náš materiál, slovesa v oblasti hospodářské češtiny, se slovesy v TTZ (Confortiová, 1974). Jako tomu bylo při srovnávání sloves v mém materiálu a ve FSČ, i zde musíme mít na zřeteli, že náš korpus je početně malý ve srovnání s materiálem TTZ. Přesto počet 10 000 jednotek jednoho slovního druhu dovoluje vyvozovat některé závěry s obecnější platností.
4.2.1. Srovnáme-li 50 nejfrekventovanějších sloves v mém materiálu a v TTZ zjistíme, že je tu 25 sloves společných (tedy celá polovina). Jsou to tato slovesa
být, mít, moci, jít, musit, vytvářet (se), působit, umožňovat, docházet, tvořit (se), vznikat, měnit (se), vést, dosáhnout, používat, probíhat, odpovídat, vytvořit (se), dát (se), určovat, vyžadovat (si), nazývat (se), platit, předpokládat, spojit.
100 nejfrekventovanějších sloves v mém materiálu a v TTZ ukazuje, že společných je 52 sloves, tedy více než polovina. K uvedeným slovesům přibývají tato:
znamenat, patřit, projevovat (se), zvyšovat (se), dojít, vycházet, řídit (se), růst, vyjadřovat, nastat, změnit (se), vyrábět, zůstávat, sloužit, vzniknout, určit, ukazovat (se), provádět, sledovat, činit, říci, pracovat, uvést, uplatňovat, označovat, lišit (se), uvádět.
4.2.2. Srovnávala jsem dále nejfrekventovanější slovesa v TTZ s mým materiálem. Zjistila jsem, že z prvních nejfrekventovanějších 50 sloves v TTZ je 32 sloves doloženo v prvních 100 slovesech mého materiálu, 12 sloves ve 300 slovesech, 5 sloves mezi dalšími slovesy. Tedy většinu (88 %) nejfrekventovanějších sloves z TTZ najdeme i mezi relativně častými slovesy v oblasti hospodářské češtiny.
[132]Odborný jazyk, ať už se týká oblasti technické, přírodovědné nebo ekonomické, má tedy v základní slovní zásobě společnou značnou část sloves, jež nejsou tak úzce specializovaná jako substantiva. Pro obecné odborné vyjadřování je třeba sloves, která můžeme označit jako všeobecně odborná. Tato slovesa vyjadřují většinou abstraktní vztahy a vytvářejí spojení a vazby mezi termíny vyjádřenými substantivy apod. (Bečka, 1973). Jazyk odborných textů technického zaměření a jazyk oblasti hospodářské češtiny ukázaly mnohé shodné rysy.
4.2.3. Všimněme si ještě sloves, která jsou doložena v mém materiálu, nikoli však v TTZ. Z 1200 sloves je to 473 sloves, tedy 3 : 2. Rozdíl je dán zřejmě tím, že slovesa užívaná k přesnému postihování pojmů a jejich vztahů v odborných textech mají nízkou frekvenci; jsou však pro odborné vyjádření nutná a jednotlivé obory se v nich navzájem liší.
5. Závěr. Specifika sloves v oblasti hospodářské češtiny se projevuje:
(1.) v slovní zásobě a jejím „bohatství“ (velká koncentrace slovníku; velké procento sloves se nachází v pásmu vysoké frekvence a v horní části frekvence střední);
(2.) v rozložení významů některých sloves, zvláště nejvíce frekventovaných (většina sloves se vyskytuje zpravidla v jednom významu);
(3.) v rozložení morfologických kategorií slovesa (frekvence 3. os. sg. a pl. a 1. os. pl.; převaha indikativu, a to většinou v prézentu a v aktivu);
(4.) ve srovnání s normou jazyka (FSČ) a odborných textů (TTZ) slovesa s vyšší frekvencí se shodují většinou s užitím ve skupinách E a G FSČ, nikoli s FSČ jako celkem; TTZ se s mým materiálem shodují ve slovesech s vyšší frekvencí, liší se ve slovesech s frekvencí nízkou.
| Pořadí | Sloveso | Frekv. absol. | Pořadí | Sloveso | Frekv. absol. |
| 1. | být | 1794 | 26. | ovlivňovat | 47 |
| 2. | mít | 400 | 27. | používat | 47 |
| 3. | moci | 326 | 28. | odpovídat | 45 |
| 4. | jít | 137 | 29. | probíhat | 45 |
| 5. | musit | 127 | 30. | začínat | 45 |
| 6. | vytvářet (se) | 95 | 31. | začít | 44 |
| 7. | působit | 76 | 32. | vytvořit (se) | 43 |
| 8. | znamenat | 69 | 33. | dát (se) | 41 |
| 9. | stát se | 66 | 34. | řídit (se) | 41 |
| 10. | patřit | 65 | 35. | uskutečňovat (se) | 41 |
| 11. | představovat (si) | 64 | 36. | vycházet | 41 |
| 12. | umožňovat | 64 | 37. | zkoumat | 41 |
| 13. | docházet | 63 | 38. | určovat | 40 |
| 14. | projevovat (se) | 60 | 39. | vyžadovat | 40 |
| 15. | tvořit (se) | 60 | 40. | nazývat (se) | 39 |
| 16. | vznikat | 60 | 41. | zabývat se | 38 |
| 17. | měnit (se) | 59 | 42. | platit | 37 |
| 18. | stávat se | 58 | 43. | dosahovat | 35 |
| 19. | vést | 58 | 44. | považovat | 35 |
| 20. | existovat | 57 | 45. | předpokládat | 35 |
| 21. | vyplývat | 52 | 46. | plnit | 34 |
| 22. | dosáhnout | 51 | 47. | růst | 34 |
| 23. | zvyšovat (se) | 50 | 48. | rozvíjet (se) | 33 |
| 24. | zvýšit (se) | 49 | 59. | spojit (se) | 33 |
| 25. | dojít | 48 | 50. | využívat | 33 |
[133]LITERATURA
BEČKA, J. V.: Lexikální složení českých odborných textů technického zaměření, díl I. a II. Praha 1973 a 1974. Zkratka TTZ.
CONFORTIOVÁ, H.: On the problem of verbs in specialized texts. PSML, 5, 1976, s. 69—89.
JELÍNEK, J. - BEČKA, J. V. - TĚŠITELOVÁ, M.: Frekvence slov, slovních druhů a tvarů v českém jazyce. Praha 1961. Zkratka FSČ.
MULLER, Ch.: Initiation à la statistique linguistique. Paris 1968.
Slovník spisovného jazyka českého. Praha 1960—1971. Zkratka SSJČ.
TĚŠITELOVÁ, M.: Otázky lexikální statistiky. Praha 1974. Zkratka OLS.
TĚŠITELOVÁ, M.: Kvantitativní lingvistika. Lingvistické příručky FF UK. Praha 1977.
TĚŠITELOVÁ, M.: Využití statistických metod v gramatice. Praha 1980.
R É S U M É
Quantitative aspects of the Czech verbs from the sphere of economy
The Czech verbs from the sphere of economy reveal characteristic properties which are manifested in the following features: (1.) in the so-called richness of verbal vocabulary (i.e. a great number of verbs appearing in the zone of high frequency and in the upper part of the medium frequency zone); (2.) in the number of meanings of some high frequency verbs (the majority of meaningful verbs having, as a rule, one meaning); (3.) in the frequency of morphological categories of verb (a high frequency of the third person singular, the third person plural and the first person plural; a prevalent use of indicative in the present tense and active voice); (4.) a comparison with the Frequency Dictionary of Czech shows that the high frequency verbs of economic Czech are present mostly in the groups E and G; the TTZ verbal inventory is in agreement with economic Czech in the high frequency zone, but disagrees in the low frequencies.
[1] Texty byly vydány v letech 1972—1976, z toho z r. 1972 pochází pouze 1 text; při výběru textů jsem se řídila potřebami jednotlivých fakult a tzv. směrových kateder na VŠE, použila jsem tedy titulů, které patří v jednotlivých oborech k základním. Nebylo možno dodržet zásadu, aby excerpovaný text byl vždy knihou, proto 40 % textů tvoří skripta.
[2] První číslo udává absolutní frekvenci slovesa, druhé počet textů, ve kterých se vyskytuje.
Slovo a slovesnost, ročník 43 (1982), číslo 2, s. 125-133
Předchozí Eva Macháčková: Vztah příčiny a následku vyjádřený slovesy způsobit, vést k, vyvolat aj.
Následující Ján Horecký: Semiotické výskumy v československej jazykovede
© 2011 – HTML 4.01 – CSS 2.1