
Využití umělého akustického signálu řeči v experimentální fonetice
Blanka Borovičková, Vlastislav Maláč
[Articles]
Использование искусственного акустического сигнала речи в экспериментальной фонетике / L’utilisation du signal acoustique artificiel du langage en phonétique expérimentale
Intenzívní výzkum v oboru akustiky řeči, jehož jsme svědky v posledních letech, přinesl řadu zcela nových pracovních metod a postupů. Jednou z těchto nových možností je použití uměle vytvořeného akustického signálu řeči. Postupy využívající tohoto umělého, syntetického, signálu nazýváme syntézou. Protože jde o akustickou formu řeči, není využití syntézy v experimentální fonetice využitím jediným.
Kromě experimentální fonetiky lze syntetického řečového signálu využít především v telekomunikační praxi a v průmyslu. Využití syntetického signálu v telekomunikační praxi je představováno v podstatě snahou komprimovat frek[399]venční přenosové pásmo na minimum nebo ještě obecněji, redukovat na minimum informační tok (v bit/sec.). Klasickými představiteli této snahy jsou různé typy vokodérů.[1] Tyto postupy však zastaraly dříve, než se plně rozvinuly, a to proto, že se neočekávanou měrou rozšířily možnosti v přenosu velmi krátkých vln jednak pomocí speciálních krátkovlných vedení, jednak pomocí telekomunikačních družic. Využití syntetického signálu a postupů syntézy v průmyslu je záležitostí nejbližší budoucnosti a půjde především o komunikaci stroj-člověk. Aby lépe vynikl význam a smysl využití syntézy ve zmíněných oborech, znázornili jsme metodu syntézy graficky (obr. 1).
Analýza (blok A) nutně předchází před syntézou (blok S). Analýza je rozklad informace nesené akustickou formou řeči do množiny (souboru) fyzikálních parametrů akustického spektra. — Zachováme-li časovou posloupnost jednotlivých parametrů dvou zbývajících dimenzí spektra (frekvence a intenzity), potom fyzikální parametry akustického spektra tvoří strukturu čistě fyzikální, kterou lze vyjádřit analogovými funkcemi těchto dvou dimenzí v závislosti na čase. Z hlediska experimentální fonetiky nás však zajímá ta část fyzikálních parametrů, která je nositelem informace (zprávy nebo sdělení). Tato nová struktura, která se od struktury fyzikální liší, je ovšem určitelná pouze subjektivně; to znamená, že je určitelná poslechovým hodnocením (percepčně blok P) fyzikálních parametrů akustického spektra řeči z hlediska jazykového systému nebo jazykového kódu. Právě tento jazykový kód je základem fyzikálních parametrů na vyšší rovině, kterou nazveme rovinou fonetické struktury. Pak střední část schématu (blok FS) může představovat jednak strukturu čistě fyzikální, tj. nižší rovinu, jednak strukturu fonetickou, tj. rovinu vyšší. — Syntéza je vytváření — sklad — akustické formy informace z fyzikálních parametrů řeči.
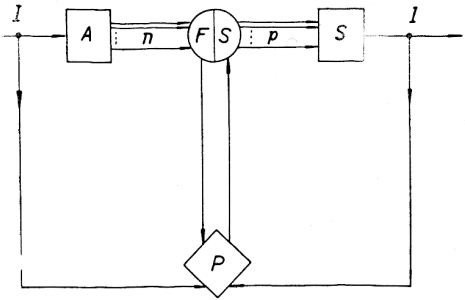
Obr. 1 — Blokové schéma začlenění analýzy a syntézy do postupů experimentální fonetiky: I — informace, akustická forma; A — blok analýzy; n — počet výstupních cest; FS — struktura fyzikálních parametrů akustického spektra řeči (první rovina) — fonetická struktura relevantních parametrů akustického spektra řeči (druhá rovina); P — blok percepčního hodnocení akustického signálu; p — počet vstupních cest; S — blok syntézy.
[400]Protiklad analýzy a syntézy spočívá tedy v tom, že postup analýzy je uskutečňován zařízením (analyzátorem), které má jednu vstupní cestu a n cest výstupních, zatímco postup syntézy je uskutečňován zařízením (syntetizérem) s p vstupními cestami a jedinou cestou výstupní. — Na schematickém znázornění (obr. 1) lze dobře vystihnout rozdíly mezi využitím syntézy jednak v telekomunikacích a průmyslu, jednak v experimentální fonetice.
Systém vokodéru (využití syntézy v telekomunikační praxi) vznikne z tohoto schématu ponecháním pouze bloků A a S, které spojíme vzájemně tak, aby se počet výstupních kanálů n bloku analýzy rovnal počtu vstupních kanálů p bloku syntézy. Je zřejmé, že pro tento způsob využití syntézy není podmínkou znalost ani struktury fonetické, ani struktury fyzikální. Redukce informačního toku je dána uspořádáním obvodů analyzátoru a syntetizéru se všemi důsledky nepřesností vzniklých nerespektováním fonetické struktury.
Pro průmyslové využití syntézy, zejm. v systémech komunikace stroj-člověk, musíme do schématu zařadit blok fyzikální struktury (FS). Znalost této struktury je nezbytná pro skladování fyzikálních parametrů a jejich pozdější vybavování na vstupu syntetizéru. Na základě dosavadní znalosti fonetické struktury je zřejmé, že využití syntézy v komunikaci stroj-člověk s kvalitou vokodérové analýzy a syntézy bude dávat výsledky nedostačující.[2] Kvalita výsledného signálu by mohla být přijatelná jen tehdy, kdybychom skladovali celé povely (věty). Pro takový případ lze ovšem jít snadnější cestou prostého záznamu zvuku (buď magnetického, nebo mechanického). Vytváření syntetické řeči z menších jednotek než věta je sice teoreticky možné bez znalosti fonetické struktury, ale povede k velmi složitým zařízením na jedné straně a k řadě nepřesností výsledného signálu na straně druhé.
Je zřejmé, že pro zmíněné obory je znalost fonetické struktury nejen užitečná, ale z hlediska ekonomického návrhu skutečných zařízení, dokonce nezbytná. Přesto je v technických aplikacích fonetická struktura jen pomocným, byť nezbytným prvkem. V experimentální fonetice je naproti tomu tato struktura těžištěm a konečným cílem výzkumu. Z našeho schématu vyplývá, že syntéza je jedním ze základních postupů v určování fonetické struktury. Jinými slovy je syntéza v experimentální fonetice tím postupem, který určení fonetické struktury umožňuje, lépe řečeno, fonetickou strukturu fyzikálních parametrů řeči zpřesňuje.
V podstatě jde totiž o to, že v našem případě lze přistoupit k syntéze teprve po předběžném, alespoň hrubém určení fonetické struktury. Toto předběžné určení fonetické struktury lze odvodit ze srovnání fyzikální struktury spektra s poslechovými testy. Vyjádříme-li fyzikální parametry v diskrétních hodnotách, pak lze k určení fyzikální struktury využít matematických metod včetně statistiky s použitím počítačů. Hrubé určení struktury fonetické je nezbytné k návrhu syntetizéru, zejména k vymezení variability jeho jednotlivých obvodů. K zpřesňování předběžné fonetické struktury ve větším rozsahu lze přistoupit teprve po zařazení samočinného počítače do postupu analýzy a syntézy. Zejména metoda analýzy syntézou je základním přístupem k určování fonetické struktury v našem výzkumu vedle využití vžité fonetické praxe, prověřování výsledků fyzikální analýzy poslechem.
[401]O postupu analýzy syntézou a jeho využití v našem výzkumu jsme psali již dříve.[3] Zde jenom zopakujeme celkové schéma našeho výzkumu (obr. 2), v kterém je patrný zejména přechod od předběžné normy relevantních oblastí, jak jsme nazvali fonetickou strukturu fyzikálních parametrů řeči, k normě konečné. Rekurentnost postupu je ze schématu zřejmá, i když je naznačena pro jednoduchost pouze jediným cyklem. Chtěli bychom zde zdůraznit, že rekurence se realizuje v obou základních strukturách, ve fyzikální i fonetické, jak jsou popsány v schematickém znázornění postupu analýzy a syntézy na obr. 1. Na obr. 2 je zachycen pouze rekurentní postup zpřesňující strukturu fonetickou (jde o bloky označené ai, resp. AI). Rekurentní postup v rovině fyzikální struktury je určen základním uspořádáním zařízení, samočinného počítače, jehož činnost je řízena postupem analýzy syntézou. Je zřejmé, že v tomto případě je syntetický signál v počítači pouze simulován v kódu počítače. K syntéze akustického signálu řeči syntetizérem (blok S) můžeme těchto informací využít až po jejich převedení do kódu syntetizéru.
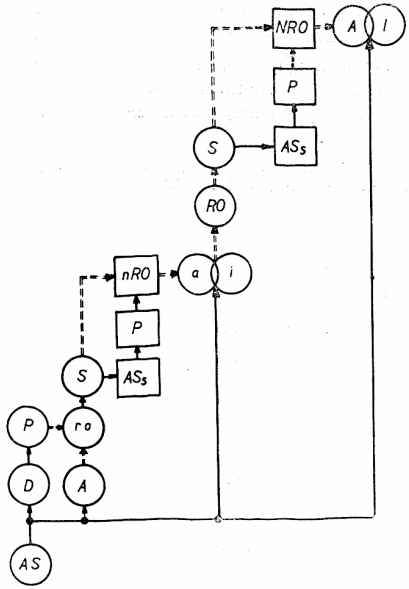
Obr. 2 — Blokové schéma pracovních postupů vedoucích k automatické identifikaci akustického signálu řeči samočinným počítačem. AS — akustický signál řeči; D — deformace akustického signálu; A — spektrální analýza akustického signálu; P — poslechové testy; ro — určení relevantních oblastí v prvním přiblížení; S — syntéza řeči; ASs — akustický signál syntetické řeči; nRO — předběžná normalizace relevantních oblastí; ai — automatická identifikace řeči podle předběžné normy; RO — statistické určení relevantních oblastí v plné šíři pozičních a stylistických variant; NRO — stanovení konečné normy relevantních oblastí; AI — automatická identifikace podle konečné normy relevantních oblastí. Plné spojnice směřují k blokům zpracovávajícím akustický signál. Čárkované spojnice směřují k blokům zpracovávajícím výsledky z předchozích bloků.
[402]V úvodu jsme se pokusili naznačit náš přístup k syntéze, tj. její využití v experimentální fonetice spolu s využitím počítačové techniky v postupech automatické identifikace řeči. Jde o perspektivní plán výzkumu. V další části našeho sdělení se chceme soustředit ve stručnosti na informaci o získaných výsledcích z první fáze našeho výzkumu. Jde v podstatě o předběžné určení relevantních oblastí (obr. 2), které je podkladem k programování řídící jednotky syntetizéru, tj. podkladem k vytvoření syntetického akustického signálu řeči. Dosavadní výsledky jsou získány srovnáním dvou druhů experimentálního materiálu. První druh experimentálního materiálu je určován ze spektrogramů,[4] druhým druhem materiálu jsou výsledky auditivních testů.[5] Materiálem jazykovým jsou symetrické kombinace českých hlásek typu CVC a VCV. Tyto skupiny obsahují všechny (matematické) kombinace pěti českých krátkých samohlásek a 25 souhlásek. 250 hláskových skupin bylo vysloveno čtyřmi mluvčími. Tím jsme získali soubor 1000 vyslovení, který byl nahrán na magnetofonový pásek. Zmíněné dva druhy experimentálního materiálu byly pořízeny z magnetofonového záznamu. Další výzkum probíhal celkem ve třech stupních.[6]
Prvním stupněm výzkumu byla spektrální analýza akustických parametrů hláskových skupin. K tomu účelu jsme zhotovili spektrogramy všech 1000 hláskových skupin[7] a snažili jsme se najít pro každý foném znaky společné nebo aspoň podobné.
Obr. 4 — Tabulka nejčetnějších záměn za (i) z obr. 3 v jednotlivých půloktávových pásmech (číslo za hláskou udává počet záměn).
| kHz | |||||||||||
|
|
| 2 |
|
|
|
|
|
|
|
|
|
| 0.3 | U |
| 04 | JI | 01 |
|
|
|
|
|
|
| 0.4 | U |
| 05 | JI | 01 |
|
|
|
|
|
|
| 0.6 | U |
| 11 | O | 02 |
|
|
|
|
|
|
| 0.7 | O |
| 12 | U | 02 | E | 02 |
|
|
|
|
| 0.9 | O |
| 11 | U | 03 | OO | 01 |
|
|
|
|
| 1.1 | O |
| 08 | U | 05 | BU | 01 | KO | 01 | A | 01 |
| 1.4 | OU |
| 03 | U | 02 | E | 01 | U | 01 | OO | 01 |
| 1.7 | JI |
| 01 | U | 01 | E | 01 |
|
|
|
|
| 2.0 | KI |
| 05 | HI | 01 |
|
|
|
|
|
|
| 3.0 |
|
|
|
|
|
|
|
|
|
|
|
| 4.5 | F |
| 01 |
|
|
|
|
|
|
|
|
| 6.5 | A |
| 03 | E | 02 | O | 02 |
|
|
|
|
| 9.0 | E |
| 01 | O | 01 |
|
|
|
|
|
|
Každý samohláskový foném se vyskytoval na spektrogramech v 300 variantách, každý souhláskový foném v 60 variantách.
V druhém stupni bylo nahrávky souboru 1000 vyslovení použito pro přípravu audi[403]tivních testů. Akustický signál řeči byl filtrován půloktávovými pásmovými filtry. Celý frekvenční rozsah 0,1—12,0 kHz byl rozdělen do 14 pásem. Signál takto modifikovaný byl zaznamenán 16 posluchači-vysokoškoláky. 3/4 miliónu jejich odpovědí jsme zpracovali počítačem Epos a získali jsme jednak 3000 histogramů správných odpovědí na každou reprodukovanou hláskovou variantu v závislosti na půloktávovém frekvenčním pásmu (ukázka jednoho z histogramů na obr. 3), jednak 3000 tabulek hláskových záměn pro jednotlivá půloktávová pásma (ukázka na obr. 4).
Obr. 3 — Histogram iniciálního (i) z hláskové kombinace (ibi). Počet správných odpovědí v % pro jednotlivá půloktávová pásma (značeny jsou střední frekvence v kHz).
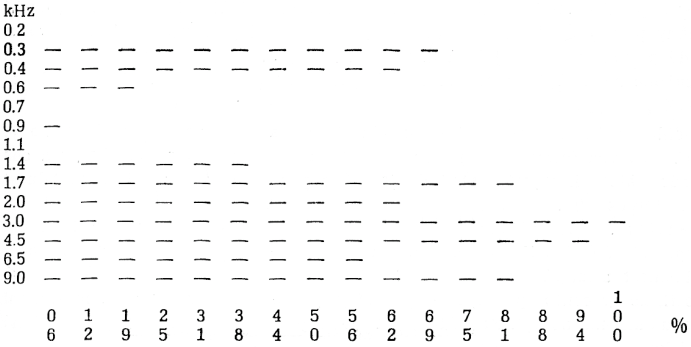
Abychom mohli hodnotit histogramy vzájemným srovnáváním, rozdělili jsme si procento správných odpovědí do tří kategorií relevance: (1) do tří správných odpovědí — irelevantní kategorie, (2) od čtyř do 12 správných odpovědí — kategorie střední relevance, (3) od 13 do 16 správných odpovědí — kategorie maximální relevance.
Důvod této kategorizace je neznalost hranice statistické významnosti procenta správných odpovědí. (Kategorizace nám umožňuje stanovit pravděpodobnost, s jakou se vyskytne hodnota např. pěti správných odpovědí v kategorii 1, 2 nebo 3.)
Třetí stupeň výzkumu spočívá ve sloučení výsledků dvou stupňů předchozích, srovnáním výsledků spektrální analýzy a výsledků poslechových testů. Tímto způsobem jsme získali v prvním přiblížení percepční znaky jednotlivých hlásek (nebo podle obr. 2 předběžné relevantní oblasti hláskových spekter).
Pokusíme se nyní podat co možná nejstručnější informaci o dosažených výsledcích ve dvou základních oddílech. V prvním popisujeme jednotlivě samohlásky, v druhé skupiny souhlásek. I když v této naší stati zvlášť nezdůrazňujeme význam fonetického kontextu, nikdy jsme jej při hodnocení výsledků nepouštěli ze zřetele. Zejména jsme si všímali jednotlivých hláskových variant na pozadí základní fonetické jednotky CV se samohláskovou artikulační dominancí, jak jsme ji podrobněji definovali podle naší hypotézy produkce řeči ve zmíněné publikaci (v pozn. 2).
Pokusíme se nejprve uvést několik našich poznatků, které jsme získali srovnáváním samohlásek. Vedle řady známých skutečností, které naše práce potvrzuje, našli jsme některé zajímavé skutečnosti nové.
Nezbytná přítomnost prvních dvou formantů pro poznatelnost samohlásek je dobře známým tvrzením.
[404]Ale pro české (i) je postačující přítomnost pouze jediného formantu. Zcela zřejmá je postačitelnost formantu F1. U F2 je poznatelnost v jediném půloktávovém pásmu nejen maximální, ale často stoprocentní. Zde ovšem není vyloučeno, že nepřítomnost formantu F1 je suplována formantem F3. Je totiž zajímavé, že tato druhá oblast relevance samohlásky (i) je velmi široká a pokrývá oblast všech vyšších formantů F2 — F5. Tato kompaktní formantová oblast je patrna i na spektrogramech. Oblast maximální relevance u vyšších frekvencí pokrývá pásma 2,0, 3,0 a 4,5 kHz. Dolní oblast v pásmu 0,2, resp. 0,3 kHz, u ženských mluvčích má nejčastěji poznatelnost (relevantnost) střední.
Samohláska (e) má dvě oblasti relevance, které odpovídají frekvencím F1 a F2 spektra. Pásmo první oblasti je 0,4, 0,6 a 0,7 kHz v závislosti na hlasové poloze, druhé je pro všechny polohy 2,0 kHz. Ale procento poznatelnosti je v obou oblastech velmi nízké; v řadě případů nedosahuje ani druhé kategorie, tj. kategorie střední relevance. Z toho usuzujeme na nezbytnou přítomnost alespoň dvou prvních formantů samohlásky k její správné percepci.
Třetí samohláska (a) má pouze jedinou oblast relevance v pásmu 1,1 kHz. To je způsobeno tím, že oba formanty (a) jsou vzdáleny od sebe pouze o půl oktávy a oba formanty padají alespoň svými částmi do jediného pásma poznatelnosti. Poznatelnost je nejčastěji stoprocentní.
Samohláska (o) má dvě oblasti relevance 0,6 a 1,1 kHz, které v kategorii střední relevance splývají do oblasti jediné. Maxima lze určit pouze při podrobnějším hodnocení. Vzdálenost mezi oběma formanty je stále ještě malá, přibližně jedna oktáva. Ze skutečnosti, že procento správných odpovědí je pouze zřídka v kategorii maximální relevance, soudíme na nezbytnou přítomnost obou prvních formantů (o) k správné percepci hlásky.
Poslední samohláska (u) přes svou spektrální podobnost s předcházejícím (o) má naprosto rozdílnou charakteristiku relevance. Nelze najít žádné konstantní frekvenční pásmo relevance, jak tomu bylo u předcházejících samohlásek. Oblasti maximální poznatelnosti se mění ve velmi širokém rozmezí v pásmech 0,2—2,0 kHz. Přesto je maximum relevance v pásmu 1,4 kHz. Toto maximum se posunuje k vyšším frekvencím u samohlásky ve spojení s palatálami (ď, ť, ň, j) a se souhláskami (ž, š, č). Ale podle spektrogramů frekvenční pásmo 1,4 kHz (popř. 1,7 kHz) nesouhlasí ani s jednou z frekvencí F1, F2 a F3 samohlásky (u). Ve jmenované frekvenční oblasti je na spektrech (u) pouze tranzient F2. Předpokládáme tedy, že základním znakem poznatelnosti samohlásky (u) je tranzient jejího druhého formantu. Tento náš předpoklad je podepřen touto skutečností: frekvence prvních dvou formantů (u) jsou velmi nízké (F2 v průměru 0,6—0,9 kHz). To znamená, že formantové frekvence jsou určovány jedinou harmonickou frekvencí hlasu, zejména u vyšších hlasových poloh. Tyto harmonické frekvence se mění se změnou základní frekvence F0. Tím vzniká nejistota v určení výšky formantu, která pak způsobuje percepční orientaci k jinému znaku, k formantovým tranzientům (tranzient je převážně znak časové dimenze).
Na rozdíl od relevantních oblastí samohláskových, které jsou soustředěny převážně do frekvenční dimenze akustického spektra, je situace v relevantních oblastech souhláskových podstatně složitější. To je způsobeno především tím, že spektrum konsonantů je tvořeno změnami všech tří dimenzí akustického signálu.
Z hlediska produkce řeči uvažujeme konsonanty, v souhlase s naší hypotézou (o. c. v pozn. 2), jako jisté přesně definované zkreslení (narušení) posloupností samohláskových artikulací. Přesto, že naše poslechové testy byly prováděny hlavně k určení relevantních oblastí frekvenční dimenze, lze z rozporů mezi výsledky spektrální analýzy a výsledky poslechových testů usuzovat na rele[405]vanci některých parametrů druhých dvou dimenzí spektra, časové nebo intenzitní, jak tomu bylo i u samohlásky (u).
Na základě výsledků naší práce (srovnáním analýzy a poslechu) dělíme české konsonanty do tří základních skupin. Kritérium selekce je jednak shodnost nebo podobnost relevantních oblastí souhlásek, jednak jejich vzájemná záměnnost v poslechových testech.
První skupinu souhlásek tvoří frikativy, afrikáty a souhláska (ř). V druhé skupině jsou explozívy. Skupinu třetí tvoří nazály, likvidy a souhláska (j).
Základním charakteristickým znakem první skupiny je šumová část spektra. Jednotlivé konsonanty jsou tedy vzájemně diferencovány relevantní oblastí frekvenční dimenze. Afrikáty jsou nadto ještě diferencovány svým trváním; jejich okluze (fonační pauza) nemá zvláštní význam. (Na význam pauzy způsobené okluzí soudíme podle procenta poznatelnosti na jedné straně varianty iniciální, na straně druhé variant mediální a finální. Stoupne-li poznatelnost v druhém případě — proti prvnímu — podstatně, usuzujeme na značný význam okluzní pauzy. V opačném případě je okluzní pauza nevýznamná.) — Znělost frikativ není tvořena pouze periodickou částí spektra. U vyšších frekvencí je evidentně nahrazena modulací šumové části spektra v rytmu hlasivkových pulsů (o.c. v pozn. 4). — Poslechové testy ukazují ještě na další oblasti relevance, které jsou velmi překvapivé, zejména u nízkých frekvencí neznělých frikativ. Oblasti relevance u středních frekvencí jsou patrně způsobeny tranzienty formantů následujících samohlásek (zejména druhého, ačkoli to nelze z výsledků poslechových testů jednoznačně prokázat).
Společným znakem druhé skupiny konsonantů, explozív, je velká závažnost okluzní pauzy. Rovněž periodická část znělých explozív má veliký význam v protikladu k stejnému parametru předchozí skupiny, kde byl význam periodické části téměř zanedbatelný. Relevance spektra exploze není stejná pro všechny členy skupiny a stoupá v řadě explozív (p, t, ť, k) (b, d, ď, g). U znělých explozív je význam spektra exploze menší než u jejich neznělých protějšků. Podobně relevance tranzientů, zejména druhého formantu následující samohlásky, není konstantní. Naše poznatky z poslechových testů rovněž potvrzují větší význam následující samohlásky pro poznatelnost explozív proti samohláskám předcházejícím.
Třetí skupina, nazály, likvidy a konsonant (j) má jako společný znak skokovou změnu intenzity formantové struktury spektra. Přitom se formantová struktura jednotlivých členů skupiny vzájemně liší.
Získané výsledky jsou směrnicí k programování syntetických hláskových skupin jednak v jejich plné formě, jednak v jejich formě redukované. Redukcí v tomto případě rozumíme takové změny fyzikálních parametrů, které eliminují nepodstatné nebo méně podstatné složky akustického spektra řeči tak, abychom mohli určovat závažnost složek relevantních. Je samozřejmé, že hodnocení syntetických signálů budeme provádět opět skupinovým poslechem. Syntetický signál budeme vytvářet na našem československém syntetizéru, který koncepčně vychází ze švédského typu OVE II.[8]
[406]Stručný výčet hlavních výsledků z prvních tří stupňů našeho výzkumu uzavíráme konstatováním, že nás nepřekvapuje řada poznatků, které nejsou s to dát jednoznačné odpovědi na hledané relevance fyzikálních parametrů jednotlivých hlásek, resp. minimálních fonetických jednotek CV (rekurentnost postupů na obr. 2 to dokazuje). Překvapuje nás však množství a rozsah nových problémů, které ze skončených etap vyplývají. Některé nejistoty v určování relevance jistě plynou ze způsobu uspořádání poslechového testu. O těchto nevýhodách jsme již psali dříve (o. c. v pozn. 2 a 3), stejně jako o výhodách postupu syntézy, k němuž v dalším, čtvrtém stupni našeho výzkumu přistupujeme. Úkolem syntézy tedy bude jednak potvrdit ty výsledky, které se zdají být z předchozího výzkumu zřejmé, jednak hledat odpovědi na skutečnosti, které nám zatím zřejmé nejsou.
R É S U M É
The Using of Synthesis in Experimental Phonetics
The authors try to explain synthesis as a possible method may be used in experimental phonetics. According to the block diagram in Fig. 1 it is evident that the synthesis must be procede both by the spectral analysis and by auditory or perception evaluation of speech signal. These two stages of research enable the selection of the relevant parameters of speech spectra. By them it is possible to alter the structure of physical parameters of the speech spectra, (determined by analysis procedure) into the phonetic structure, which is the structure in a higher level. Only then it is possible to start the programming of synthetic speech signal. The second part of this paper introduces the results from the comparison of the first two stages of research (spectral analysis and auditory test). This results are divided in two groups of findings. The first one describes the vowel findings and the second one the consonant findings.
[1] B. Borovičková — V. Maláč, Zasedání komise o analýze a syntéze mluvené řeči ve Varšavě, SaS 25, 1964, 241—242.
[2] B. Borovičková — V. Maláč, The Spectral Analysis of Czech Sound Combinations, Rozpravy Čs. akademie věd, SV, 1967, ř. 77, sešit 14, 68 s.; srov. zde s. 448n.
[3] B. Borovičková — V. Maláč, K automatické identifikaci řeči samočinným počítačem, Slaboproudý obzor 26, 1965, 385—390; Analýza řeči, studijní zpráva 671/64, VÚST elektroakustika 1964, 23 s.
[4] Detailní popis postupů použitých při hodnocení akustických spekter hláskových kombinací spolu s podobnými výsledky této práce jsou obsaženy jednak v o.c. v pozn. 2, jednak v laboratorních zprávách: B. Borovičková — V. Maláč, Analýza řeči, dílčí zpráva 696/64, VÚST elektroakustika 1964, 87 s.; Analýza řeči, závěrečná zpráva 786/66, VÚST elektroakustika 1966, 193 s.
[5] V. Maláč — B. Borovičková, Syntéza řeči, dílčí zpráva I. 841/67, VÚST elektroakustika 1967, 74 s.
[6] B. Borovičková, Spektrální analýza češtiny, kandidátská práce, rukopis 1962, 319 s.; táž, K otázce spektrální analýzy mluvené řeči, SaS 22, 1961, 263—268; táž, Zjišťování relevantních oblastí hlásek v češtině, SaS 25, 1964, 26—30.
[7] Trojrozměrné spektrogramy v dimenzích čas, frekvence, intenzita byly zhotoveny na speciálním spektrografu čs. výroby. Podrobnější popis v o.c. v pozn. 2 a v laboratorní zprávě A. Brabce Zvukový spektrometr, závěrečná zpráva 614/63, VÚST elektroakustika 1963, 54 s.
[8] Vlastní jednotka syntetizéru OVE II je podrobně popsána v publikaci stockholmské laboratoře Fantovy Speech Communication Laboratory. (srov. dále). Náš syntetizér vybudovaný v l. 1965—1968 (ve spolupráci fonetické laboratoře ÚJČ ČSAV, katedry teoretické elektroniky ČVUT a sektoru elektroakustiky VÚST) se ve vlastní jednotce koncepčně shoduje se zařízením OVE II. Přepracovali jsme pouze hodnoty (zejména frekvenční) jednotlivých obvodů tak, aby vyhovovaly hodnotám fyzikálních parametrů zjištěných naším dosavadním výzkumem pro české hláskové skupiny. Řízení jednotlivých funkcí našeho syntetizéru je koncipováno na základě digitální techniky již podle našeho návrhu. Dosavadní zařízení hodláme v budoucnosti přepracovat podle provozních zkušeností s prvním typem a jistě i s využitím zkušeností zahraničních. V prvním typu syntetizéru jsme dbali ještě přísně na ekonomické využití toku informace. V druhém typu již půjdeme cestou maximálních požadavků z hlediska experimentální fonetiky a hledisko ekonomické postavíme až na místo druhé. Teprve v technických aplikacích se vrátíme opět k hlediskům přísně ekonomickým. — G. Fant, Speech Analysis and Synthesis, The Royal Institute of Technology Stockholm, 1962, 63 s.; V. Maláč, Syntéza řeči, studijní zpráva 768/65, VÚST elektroakustika 1965, 29. s.; týž syntéza řeči, využití syntetizéru 887/67, VÚST elektroakustika 1967, 13 s.
Slovo a slovesnost, volume 29 (1968), number 4, pp. 398-406
Previous Josef Štěpán: K problematice složitého souvětí v současné spisovné češtině (Pokus o dynamický popis)
Next Jiří Lípa: O nevěrohodnosti ciganologa H. v. Wlislockého
© 2011 – HTML 4.01 – CSS 2.1