
O jednom modelu rozložení délky slov
Ludmila Uhlířová
[Articles]
On a model of word length distribution
0. Tento článek vznikl v souvislosti s autorčinou účastí na multilingválním projektu „Teorie slovní délky“, jehož koordinátorem je K.-H. Best z Univerzity v Göttingen a jehož cílem je nalézt zákony rozložení slovní délky a jejich realizace v textech různých jazyků; do projektu je zahrnuto zkoumání přibližně tří desítek typologicky různých jazyků indoevropských i jiných. Ve stati se na základě empirických dat předkládá pravděpodobnostní model rozložení slovní délky v českých textech. Model potvrzuje teorii rozložení slovní délky, jak je formulována v pracích Altmanna – Besta (1994), Wimmera – Altmanna (1984), Altmanna – Erata – Hřebíčka (1994), Wimmera – Köhlera – Grotjahna – Altmanna (1994) a v některých pracích dalších, a představuje dílčí příspěvek k verifikaci dané teorie (viz též Uhlířová, 1994).
1. Pokusy o modelování distribučních vlastností elementárních i komplexních lingvistických jednotek, různě definovaných a příslušných různým jazykovým rovinám, k nimž se hlásí i tato stať, jsou založeny na hypotéze, že
(a) jejich opakování v textech není náhodné, ani chaotické, nýbrž jeví jisté pravidelnosti či zákonitosti, a to nikoli deterministické, nýbrž pravděpodobnostní. Pravděpodobnost je obecně považována za inherentní rys jazyka jakožto sémiotického systému;
(b) zákonitosti opakování[1] lze popsat pomocí modelů na vysokém stupni obecnosti, takových, které platí i pro jiné systémy s nedeterministickým chováním, a tedy technikami, které jsou replikovatelné jak v jazykovědě, tak za jejími hranicemi.
Právě důrazem na hledání, popis a vysvětlení toho, co má struktura jazyka společného s tím, jak jsou organizovány jiné systémy, se modelování distribučních vlastností jazykových jednotek řadí mezi přístupy interdisciplinární. Pro přístup, který bude aplikován níže, je přijat název synergetická lingvistika. Protože tento směr lingvistického uvažování je poměrně nový, zmíníme se nejprve stručně o tzv. synergetice, od níž je odvozen jako jeden z možných aplikačních směrů, a stručně se pokusíme začlenit filozofii synergetického přístupu do kontextu současného funkcionalistického myšlení v jazykovědě.
Synergetika je fyzikální disciplína, jejíž místo v systému věd bylo pevně definováno teprve na počátku sedmdesátých let tohoto století; za jejího otce je považován profesor Stuttgartské univerzity H. Haken. Přímo souvisí s rozvojem termodynamiky, s teorií deterministického chaosu, s teorií katastrof, s tím, že náhodný činitel vystupuje v jistých exponovaných situacích jako stimul kvalitativní změny. Jednou z hlavních myšlenek synergetiky a impulzem jejího rozvoje je axiom, že mechanismy vzniku nových kvalit v různých systémech s nelineární dynamikou (např. zmagnetování látek, vznik supravodivosti, vznik koherentního záření v laseru aj.) jsou popsatelné stejným fyzikálně-matematickým formalismem. Mezi základní pojmy synergetiky patří stacionárnost (stabilita) systémů (jevů, pohybu), jejímž opakem je nestabilita, porucha, kvalitativní změna. Tyto jevy popisuje synergetika soustavami nelineárních rovnic; hledá, velmi zjednodušeně řečeno, geometrická místa [9]bodů vyjadřujících charakteristické rysy systémů, a tato geometrická místa nazývá atraktory. Samy pojmy synergie (z řec. synergeia) a synergismus, které jsou v základu názvu synergetiky a které označují vztah dvou jevů či procesů založený na společném úsilí, na souhlasném působení, na vzájemné podpoře, spolupráci, součinnosti, byly ovšem dávno před vznikem synergetiky popsány v různých oblastech živé i neživé přírody i lidského myšlení.[2] Do jazykovědy pronikly principy synergetiky o něco později než do jiných vědních disciplín; Krempaský (1988), který podal základní poučení o synergetice a jejích aplikacích v různých vědních oblastech, uvedl příklady z astrofyziky, chemie, biologie, medicíny, ekologie, ekonomie a sociologie, s upozorněním, že ve společenských vědách, na rozdíl od věd přírodních, byly mnohé aplikace v době vydání knihy teprve ve stadiu reflexí či anticipací. Synergetická lingvistika u Krempaského ještě explicitně zmíněna není, dostává se tam však zadními vrátky, a to v kapitole o činnosti centrální nervové soustavy jako synergetického komplexního systému: činnost mozku jako paměťového centra lze simulovat pomocí tzv. slovníkového modelu, a ten je navržen s uplatněním lingvistům dobře známého Zipfova zákona.
Nepřekvapí, že první aplikace synergetiky v jazykovědě se zrodily v prostředí lingvistiky německé. Synergetický model Köhlerův výslovně vychází z analogie mezi biologickým vývojem a vývojem jazyka: Také jazyk je dynamický systém se samoregulačními a samoorganizujícími řídícími mechanismy, jejichž působením se mění, vyvíjí, mění svou kvalitu tak, aby výsledkem byl stabilní, rovnovážný stav a optimální adaptace vůči okolí (Köhler, 1933, s. 41). Fakt, že se v synergetické lingvistice dostávají do centra pozornosti obecné principy vývoje jazyka, není z hlediska vývoje lingvistiky jako disciplíny náhodný. Lze říci, že zkoumání obecných zákonitostí kvalitativních změn jazyka v čase je tím tématem, které je dnes v lingvistice aktuální, a synergetická lingvistika představuje jeden z možných způsobů, jak k tomuto tématu přistoupit. Také například přední reprezentant systémového funkcionalismu M. A. K. Halliday, který jako jeden z prvních upozornil na to, že v dnešní době se mění způsob organizace vědění, a to tak, že se „přesouvá od disciplín k tématům“ (Halliday, 1991, s. 40), považuje za téma číslo jedna „kladistiku jazyka, tj. způsob, jak jazyk přetrvává a také jak se mění v průběhu času“ (tamtéž). Halliday přitom zdůrazňuje, že jazyk je jen konkrétním příkladem toho, jak přetrvává jakákoli forma organizace. Köhlerův pojem dočasných, dynamických kompromisů ve vývoji jazyka je dobře srovnatelný rovněž s uvažováním představitele pragmatického směru funkční lingvistiky T. Givóna, který chápe jazyk jako „dynamický komunikační systém, v němž jedna strategie se vždy nachází v procesu přeměny v jinou“ (1979, s. 237). Podle Givóna „výsledný synchronní stav je smíšená entita, komunikativní kompromis mezi konfliktními komunikativními požadavky, v nichž se odrážejí zamrzlé otisky prozrazující kyvy a opačné kyvy komunikativního kyvadla“ (s. 269). Velmi příbuzný pojem „zamrzlých ostrovů“ má své místo například také v přístupu Beaugrandově (1994), který se zase v mnohém hlásí k myšlenkám funkcionalismu [10]pražského. A konečně Köhlerovy pojmy stability, ustáleného stavu a „flux equilibrium“ (Köhler, 1993, s. 42) nemohou nepřipomínat funkční pojem pružné stability, známý u nás od doby Mathesia.
Pojmy ekonomie, entropie a redundance, s nimiž Köhler pracuje, staví synergetickou lingvistiku do souvislostí s kybernetikou a teorií informace. Do blízkosti těchto oborů se ostatně lingvistika dostala již v padesátých a šedesátých letech a také u nás, podobně jako jinde ve světě, jí právě tato doba přinesla řadu zajímavých výsledků. Shannonova zásadní stať z r. 1951 byla přeložena do češtiny (1964) a inspirovala vznik řady cenných původních aplikací. Jestliže současná synergetická lingvistika je, obecně řečeno, na jedné straně jedinečná v tom, že se pokouší aplikovat zákonitosti známé z termodynamiky na jazyk a činí fyziku, po matematice, další přírodní vědou, která chce ovlivnit lingvistiku, na druhé straně je třeba vidět i to, že nepředstavuje nějaký ostrov, který by byl svou filozofií zcela izolován od jiných trendů jazykovědného myšlení dnešní doby.
2. Text jako předmět zkoumání synergetické lingvistiky je uvažován, jak vyplývá z výše řečeného, z hlediska procesuálního: Předpokládá se, že vzniká – jakožto nová kvalita – za určitých výchozích podmínek a určitými strategiemi, které mohou působit buď souhlasně, anebo proti sobě. Výchozí podmínky zůstávají, alespoň v bezpříznakových případech, v průběhu procesu generování textu rozumně stabilní (alespoň to o nich lze předpokládat), takže text lze považovat za synergetický systém. Má se za to, že vnitřní stabilitu textu, resp. její míru, v krajním případě pak nedostatek stability, lze odhalit za předpokladu, že budeme zkoumat text jako celek. To je kardinální zásada synergetické lingvistiky; synergetická lingvistika nepracuje s náhodnými, systematickými ani jinými výběry z textů, protože má za to, že při jakémkoli výběru existuje riziko, že se mohou některé vlastnosti textu „ztratit“. Jen text jako celek, jako individuální opus s celistvou strukturou, může představovat organizovaný, rovnovážný systém. Tento systém, resp. jeho rovnovážnost, je hledána v jazykových prostředcích, jimiž je vytvářen. V následujícím výkladu se zkoumá jediný prostředek, totiž délka slova.
3. Po těchto úvodních úvahách můžeme formulovat hypotézu o rozložení slovních délek konkrétněji. V souhlase s teorií Altmanna – Erata – Hřebíčka (1994) přijímáme předpoklad, že jestliže modelujeme empirické frekvenční rozložení slovních délek v textu vhodným pravděpodobnostním rozložením, můžeme toto rozložení interpretovat jako atraktor daného textu.
3.1. Měřenou jednotkou je tvar slova v textu (nikoli délka slova v základní, slovníkové podobě) a jednotkou, v níž se délka slovního tvaru měří, je slabika. V pravidelných případech, kterých je většina, slabičná hranice buď leží uvnitř slova, anebo je se slovní hranicí identická. Případy, které je třeba ošetřit zvlášť, jsou v našich textech dvojího druhu:
(a) České neslabičné předložky v, k, s, z se pravidelně připojují k první slabice slova následujícího a spolu s ní tvoří takzvaný složený slabičný typ. Teoreticky musíme tedy počítat i s textem, v němž počet slabik je menší než počet slov. Kdybychom učinili východiskem zkoumání rovinu fonetickou a počítali úhrnnou délku nějakého textu ve slabikách, museli bychom spojení jména s neslabičnou předložkou (v Praze, s ním, k nádraží apod.) počítat vždy jako jedno „slovo“. Tak [11]také postupuje Ludvíková (1985, s. 22 a 153). V naší úloze však je výchozí jednotkou slovo jako jednotka roviny lexikální (ovšem v příslušném tvaru v textu), a proto neslabičné předložky počítáme jako zvláštní třídu neslabičných slov.
(b) Vyskytne-li se v textu symbol neslovní povahy (např. letopočet udaný číslicemi) nebo zkratka či zkratkové slovo, je přijata zásada počítat počet slabik tak, jaký by (pravděpodobně) byl, kdyby byl příslušný výraz vysloven, tedy např. č. p. 24 ‚číslo popisné dvacet čtyři’. Jinou možností by bylo takové výrazy do rozložení slovních délek prostě nezapočítávat, což by ale znamenalo porušit synergetickou zásadu pracovat s celým textem.
Naproti tomu není nutné se zabývat problémy slabičné hranice, protože počet slabik v slovním tvaru není ovlivněn tím, kam hranici ve slovech se souhláskovými skupinami umístíme.
3.2. Statistické šetření bylo provedeno na materiále deseti povídek B. Hrabala z třetího svazku jeho sebraných spisů.[3] Záměrně byly vybrány texty o rozsahu nepřesahujícím tři tisíce slov. Dosavadní pozorování totiž ukazují, že čím delší je text, tím složitější je modelovat a testovat rozložení slovních délek v něm (hodnota χ2 roste s rozsahem výběru). V termínech synergetické lingvistiky lze také říci, že čím delší je text, tím snáze může dojít k destabilizaci samoorganizujících podmínek působících v průběhu jeho postupného vzniku v čase a tím snáze se může proměnit i jeho atraktor (bylo by však zjednodušené tvrdit, že míra stability, resp. nestability atraktoru je lineární funkcí času).
3.3. Výpočty[4] prokázaly, že nejvhodněji lze modelovat rozložení slovních délek v daných textech pomocí rozšířeného pozitivního binomického rozložení, které v jednotlivých textech vykazuje různé lokální modifikace. Toto rozložení lze odvodit z useknutého binomického rozložení, popsaného u Altmanna – Erata – Hřebíčka (1994). Označíme-li x počet slabik ve slově, fx empirickou četnost slov dané slabičné délky, N délku textu v počtu slovních tvarů a položíme-li pro třídu x = 0 pravděpodobnost 1 – α, pak všechny ostatní třídy mají pravděpodobnost αPx a platí pro ně
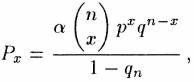
kde x = 1, 2 … n, n ∈ N, 0 < p, α < 1 a q = 1 – p.
Empirické a teoretické hodnoty rozložení pro deset textů jsou uvedeny v tabulce spolu s hodnotami textu χ2 o r stupních volnosti. Shoda empirického a teoretického rozložení je u všech deseti textů velmi dobrá i přesto, že jde o texty poměrně dlouhé (u delších textů můžeme operovat s koeficientem C = χ2/N).
Tím, že modelujeme celé rozložení a nezůstáváme pouze u jediné statistické charakteristiky (jakou je například průměr, modus nebo medián), respektujeme skutečnost, že hodnoty proměnné fx (tj. frekvence tříd slovních délek v textu) nejsou na [12]sobě nezávislé. Předpokládaná proporcionální závislost je ovšem dána souhrou velkého počtu činitelů jazykově systémových, žánrových, individuálně stylových apod. Přijmeme-li názor, že jazykový systém je složité paradigma poskytující mluvčímu příslušného jazyka možnost volby prostředků na všech rovinách gramatiky i slovní zásoby, pak ovšem jiné možnosti voleb má mluvčí jazyka flektivního a jinak může volit mluvčí jazyka aglutinačního. Volba zasahuje i syntagmatickou osu jazyka: Je známo, že každý jazyk má svůj vlastní, metaforicky řečeno „národní“ rytmus, specifická pravidla střídání kratších a delších slovních tvarů ve větě, střídání tvarů přízvučných a nepřízvučných aj.
Přesto dosavadní empirické testy provedené na materiále z různých jazyků, které byly popsány v literatuře, ukazují, že různé texty (a různé jazyky) vyhovují nevelkému počtu modelů a jejich modifikací. Wimmer – Altmann (1994) zmiňují Conwayovo-Maxwellovo-Poissonovo rozložení, Poissonovo rozložení, negativní binomické, binomické, hyper-Poissonovo, hyper-Pascalovo, Pólyovo a ještě některá další, s lokálními modifikacemi. Rovněž rozšíření českého materiálu by pravděpodobně vedlo k nalezení dalších modelů. Zatím jsme dospěli pouze k nalezení jediného modelu, který vyhovuje pro desítku textů jednoho žánru od téhož autora z téhož období jeho tvorby. Tento model se řadí mezi ty modely, které už byly popsány různými autory pro texty v různých jazycích (např. na materiále polském, viz J. Samborová, osobní sdělení). V tomto smyslu přinášejí analyzované české texty dílčí empirické potvrzení obecného mechanismu, jímž se rozložení slovních délek zdá řídit. Zároveň však jeví i řadu vlastností specifických.
Nejfrekventovanější slovní třídou ve všech analyzovaných textech je shodně třída slov jednoslabičných, f1. Zároveň je to třída, která vykazuje v jednotlivých textech největší frekvenční variabilitu, totiž od 32 % do 47 %. Mezi nejčetnější jednoslabičná slova v Hrabalových povídkách patří navazovací a slučovací a, zvratné se, si, předložky na, do, za, po, bez, spojka že, tvary pomocného a sponového být (jsem, je, by), tvary zájmen 1. a 2. osoby (mi, mne, ty, vám), některá další slova v širokém smyslu deiktická (tak, tam, ten, tu, ty, je) a další. Deset nejčetnějších slovních tvarů z třídy f1 pokrývá 7,10 %–15,25 % celého textu, což lze považovat za specifickou charakteristiku daných textů (s rostoucí délkou textu procento pokrytí klesá). Třída f1 má nejvyšší index opakování ze všech tříd, totiž od 2,84 do 6,51 v jednotlivých textech (roste, dle očekávání, s délkou textu). Pro porovnání uveďme, že index opakování pro všechny fx>1 leží v intervalu 1–1,7 v závislosti na délce textu a s rostoucím x klesá. Jinými slovy, třídu jednoslabičných slov v textech tvoří relativně nízký počet různých slov, která se často opakují. Všechny slovní třídy s x > 1 jsou naopak tvořeny vysokým počtem různých slov, která se opakují podstatně méně často.
Frekvenční variabilitou se dále vyznačuje třída slov trojslabičných, tedy slov převážně z tematické vrstvy slovní zásoby textů. Ty tvoří 14 %–21 % všech slovních tvarů v textech. Naproti tomu třída slov dvojslabičných jeví relativní frekvenční stabilitu v různých textech – rozpětí hodnot činí jen 4 %. Frekvenční stabilitu jeví i uzavřená čtyřprvková třída f0, dále třída f4 a všechny třídy f s indexem větším než 4.
Ukazuje se tedy, že kdybychom chtěli hledat specifické charakteristiky autorova stylu v daných textech, měli bychom podrobněji zkoumat především třídy f1 a f3. Obecně z tohoto pozorování vyplývá, že pro studium vztahu proporcionality mezi [13]třídami fx a pro interpretaci lokálních modifikací pravděpodobnostních hodnot NPx nemusí být nejdůležitější vždy třídy sousední.
3.4. Uzavíráme. Jestliže synergetická lingvistika poskytla pro danou kvantitativní úlohu obecně filozofické a metodologické zázemí, které se snad může jevit z hlediska některých jiných kontextů lingvistického uvažování jako poněkud odtažité, pak zcela konkrétní je samo vyústění úlohy, totiž nalezení kvantitativního modelu (atraktoru) rozložení slovních délek. Modelování kvantitativních charakteristik jazyků a textů prohlubuje naše poznání o nich a zařazuje je do interdisciplinárního kontextu: Kdybychom se například zabývali automatickým rozpoznáváním souvislé řeči, pak jedna z otázek, kterou bychom si museli položit, by se týkala pravděpodobnostní struktury mezislovních předělů, a tedy i pravděpodobnostního rozložení slovních délek v počtu slabik.
LITERATURA
Altmann, G. – Best, K.-H.: Zur Länge der Wörter im deutschen Texten. Glottometrica, 15, 1994.
Altmann, G. – Erat, E. – Hřebíček, L.: Word length distribution in Turkish texts. Glottometrica, 15, 1994.
Beaugrande, R. de: Function and form in language theory and research: The tide is turning. Předneseno v Praze dne 2. 5. 1994.
Givón, T.: On Understanding Grammar. New York – San Francisco – London 1979.
Halliday, M. A. K.: Towards probabilistic interpretations: In: E. Ventola (ed.), Functional and Systemic Linguistics. Berlin – New York 1991, s. 39–61.
Hřebíček, L. – Altmann, G.: Prospects of text linguistics. In: L. Hřebíček – G. Altmann (ed.), Quantitative Text Analysis. Wissenschaftlicher Verlag, Trier 1993, s. 1–28.
Köhler, R.: Synergetic linguistics. In: Contributions to Quantitative Linguistics. Proceedings of the First International Conference on Quantitative Linguistics, QUALICO, Trier 1991. Kluwer Academic Publishers, Dordrecht – Boston – London 1993, s. 41–51.
Krempaský, J. a kol.: Synergetika. Bratislava 1988.
Ludvíková, M.: Kvantitativní charakteristiky českých fonémů. In: M. Těšitelová a kol., Kvantitativní charakteristiky současné češtiny. Praha 1985, s. 11–28.
Shannon, C. E.: Predikce a entropie tištěné angličtiny. In: Teorie informace a jazykověda. Praha 1964, s. 75–88.
Uhlířová, L.: How long are words in Czech? Glottometrica, 15, 1994.
Wimmer, G. – Altmann, G.: The theory of word length: Some results and generalizations. Glottometrica, 15, 1994.
Wimmer, G. – Köhler, R. – Grotjahn, R. – Altmann, R.: Towards a theory of word length distribution. Journal of Quantitative Linguistics, 1, 1994, s. 98–106.
R É S U M É
On a model of word-length distribution
The present study is a contribution to a multilingual project on word-length theory, realized in the theoretical framework of synergetic linguistics, and supplying original Czech data.
[14]Tabulka
rozložení délky slova v počtu slabik v Hrabalově próze
| Text č. 1 | 2 | 3 | 4 | 5 | ||||||
| x | fx | NPx | fx | NPx | fx | NPx | fx | NPx | fx | NPx |
| 0 | 36 | 36,00 | 27 | 27,00 | 50 | 50,00 | 9 | 9,00 | 70 | 70,00 |
| 1 | 352 | 337,11 | 391 | 371,88 | 1321 | 1297,64 | 182 | 185,98 | 806 | 786,01 |
| 2 | 340 | 360,66 | 328 | 342,73 | 896 | 919,65 | 176 | 171,82 | 796 | 803,35 |
| 3 | 216 | 214,37 | 172 | 175,47 | 409 | 410,37 | 111 | 98,77 | 452 | 437,90 |
| 4 | 82 | 76,45 | 56 | 53,90 | 144 | 129,26 | 30 | 39,54 | 110 | 134,27 |
| 5 | 15 | 16,35 | 7 | 9,93 | 15 | 30,53 | 8 | 11,69 | 19 | 21,95 |
| 6 | 2 | 2,06 | 1 | 1, 9 | 7 | 5,61 | – | 2,64 | 2 | 1,52 |
| 7 |
|
|
|
| 2 | 0,94 | 1 | 0,46 |
|
|
| 8 |
|
|
|
|
|
| 3 | 0,10 |
|
|
|
| n=7 | n=7 | n=19 | n=16 | n=6 | |||||
|
| α=0,9654 | α=0,9725 | α=0,9793 | α=0,9827 | α=0,9690 | |||||
|
| p=0,2629 | p=0,2350 | p=0,0730 | p=1097 | p=0,2902 | |||||
|
| χ32=2,37 | χ32=2,64 | χ12=1,05 | χ32=5,38 | χ32=5,98 | |||||
|
| P=0,50 | P=0,45 | P=0,31 | P=0,15 | P=0,11 | |||||
|
| C=0,0023 | C=0,0027 | C=0,0004 | C=0,0102 | C=0,0026 | |||||
|
| ||||||||||
| Text č. 6 | 7 | 8 | 9 | 10 | ||||||
| x | fx | NPx | fx | NPx | fx | NPx | fx | NPx | fx | NPx |
| 0 | 14 | 14,00 | 9 | 9,00 | 71 | 71,00 | 52 | 52,00 | 31 | 31,00 |
| 1 | 279 | 252,71 | 199 | 192,98 | 984 | 1015,28 | 824 | 842,86 | 677 | 646,08 |
| 2 | 235 | 243,32 | 150 | 162,70 | 815 | 818,07 | 619 | 634,85 | 442 | 470,93 |
| 3 | 115 | 124,95 | 73 | 73,16 | 452 | 408,05 | 273 | 265,65 | 203 | 209,77 |
| 4 | 31 | 36,09 | 27 | 18,50 | 138 | 140,91 | 94 | 66,69 | 71 | 63,71 |
| 5 | 3 | 5.93 | 1 | 2,66 | 26 | 35,68 | 11 | 10,95 | 13 | 13,93 |
| 6 |
|
|
|
| 7 | 6,84 |
|
| 1 | 2,58 |
| 7 |
|
|
|
| 3 | 1,01 |
|
|
|
|
| 8 |
|
|
|
| 1 | 0,196 |
|
|
|
|
|
| n=6 | n=6 | n=15 | n=7 | n=13 | |||||
| α=0,9793 | α=0,9803 | α=0,9716 | α=0,9722 | α=0,9784 | ||||||
| p=0,2780 | p=0,2512 | p=0,1032 | p=2007 | p=0,1083 | ||||||
| χ22=5,97 | χ12=3,40 | χ22=6,79 | χ22=12,20 | χ33=5,32 | ||||||
| P=0,05 | P=0,07 | P=0,03 | P=0,0022 | P=0,15 | ||||||
| C=0,0087 | C=0,0074 | C=0,0027 | C=0,0065 | C=0,0037 | ||||||
[1] O principu opakování a o jeho „důležité pozici ve filozofii vědění“ viz podrobněji ve studii Hřebíčka – Altmanna, 1993, s. 13.
[2] Např. v medicině se synergismem léků rozumí zesilování účinku dvou nebo více současně podávaných léků. Z anatomie známe synergisty, tj. svaly, které pomáhají funkci některého jiného svalu; jejich opakem jsou antagonisté. Pojem synergismu je znám i ve filozofii a v teologii. Adjektivum synergický znamená ‚jevící znaky synergismu’; adjektivum synergetický je významově odlišné a znamená ‚využívající pojmového a matematického aparátu synergetiky’.
[3] B. Hrabal: Jarmilka. In: Sebrané spisy, sv. 3. Pražská imaginace, Praha 1992. Laskavostí kolegů spravujících Počítačový korpus češtiny mi byly dány k dispozici texty povídek na disketách. Analyzovány byly tyto texty: 1. Expozé panu ministru informací, 2. Lednová povídka, 3. Únorová povídka, 4. Blitzkrieg, 5. Křtiny, 6. Očekávej mě, 7. Dětský dům, 8. Romantici, 9. Umělé osudy, 10. Setkání.
[4] Veškeré testy hypotéz o typech rozložení laskavě provedl prof. G. Altmann z Univerzity v Bochumi.
Slovo a slovesnost, volume 56 (1995), number 1, pp. 8-14
Previous red. (= Redakce): Slovu a slovesnosti úvodem
Next Jaroslava Hlavsová: Funkce a adekvátnost vzájemné interpretace mluveného a psaného textu
© 2011 – HTML 4.01 – CSS 2.1