
K systematickému syntaktickému popisu slovanských jazyků
František Daneš
[Články]
О систематическом синтаксическом описании славянских языков / Sur la description syntaxique systématique des langues slaves
1. Současné nové směry v bádání gramatickém mají některé společné rysy. Uvedu alespoň některé nejvýraznější. Za prvé je to odklon od problematiky procedurální, a tedy od indukce a analýzy, a důraz na problematiku formy popisu gramatického systému, a tedy zdůraznění dedukce; významně se přitom uplatňuje metoda modelování. Za druhé pojem „gramatika“ se chápe značně široce, buď přímo jako „teorie jazyka“, nebo alespoň jako systém pravidel popisujících celou strukturu daného jazyka (jejími složkami jsou pak, nejnověji, syntax, sémantika a fonologie a jistým způsobem i slovník). „Ja[113]zykem“ se pak rozumí nekonečná množina všech správných vět[1] a „jazykový systém“ (langue ve smyslu de Saussurově) je vlastně gramatikou. Třetím výrazným rysem je generativní metoda jazykového popisu. Jde o generování v tom smyslu, že gramatiku tvoří uzavřený systém pravidel, pomocí něhož lze vytvořit (a popsat) všechny správné věty daného jazyka a jen tyto. (Nejde tu tedy o generování ve smyslu psychologického nebo historického procesu ani o generování konkrétního textu; generování je tu jen procesuální formou popisu vztahů mezi elementy jazykového systému.)
Z uvedených rysů plynou některé další, zejména tyto: snaha o formalizaci (a symbolizaci) popisu a o jeho úplnost (nespoléhat na jazykové povědomí toho, kdo mluvnice užívá); zásada, že způsob podání a uspořádání popisu gramatické stavby nesmí být arbitrérní, nýbrž má tvořit jasně uspořádaný systém, zdůvodněný celkovou teorií jazyka (a nikoli tedy neúplný katalog faktů a pozorování, ani jen taxonomická klasifikace).
Domnívám se, že každá práce na gramatice nějakého jazyka musí k těmto směrům zaujmout stanovisko, vyrovnat se s nimi.
2. Ve svém stručném referátu se pokusím načrtnout jedno z možných schémat popisu syntaktické (v tradičním smyslu) struktury češtiny a naznačit jeho zapojení do celkového popisu jazykového systému. Toto schéma má v jistém smyslu generativní charakter, opírá se o princip tzv. gramatiky závislostní[2] (v české i slovenské jazykovědě běžný a pro slovanské jazyky vhodný) a její základ tvoří jeden z principů pražské školy (opírající se o de Saussura a zdůrazněný Mathesiem), totiž protiklad jazykového systému a promluv (na úrovni syntaktické tedy větného vzorce a výpovědi), založený na vztahu abstraktní systémové jednotky a její realizace.
Od každého systematického syntaktického popisu musíme požadovat několik věcí. Vycházíme-li z empiricky dané množiny všech výpovědí daného jazyka, očekáváme, že syntaktická složka gramatiky dovede stanovit u každé výpovědi její obecnou syntaktickou strukturu. Tradiční mluvnice (zejm. školská) plnila tento úkol při tzv. „větném rozboru“: u každého syntaktického elementu (slova) v dané výpovědi se určilo jeho slovnědruhové a morfologické zařazení, větněčlenská platnost a konečně rozkladem věty na tzv. syntagmata se určila závislostní struktura; dále pak rozlišením větných členů základních a rozvíjejících (popř. pomocí pojmu „věty holé“) se zjišťovaly elementární struktury a jejich podoby rozvité. Pomocí uvedených ukazatelů se pak provedla elementární klasifikace vět („podle členitosti“). (Nechávám stranou pořadí jednotlivých kroků takové analýzy.)
Tento postup není však dostatečně úplný a podává spíše jen návod k analýze; nedává přehledný systematický popis syntaktického plánu jazykového systému ani uspořádaný soubor pravidel pro tvoření vět daného jazyka, resp. si tento cíl ani neklade. Pokusím se proto tento postup doplnit, prohloubit (zjemnit) a zčásti formalizovat tak, aby těmto podmínkám lépe vyhovoval.
Za základní systémovou jednotku syntaktickou pokládám větný vzorec. Tento pojem postihuje jádro každé syntaktické struktury (a v tom smyslu se [114]stýká s tradičním pojmem „holé věty“ školských mluvnic) a lze jej charakterizovat jako minimální konfiguraci distinktivních syntaktických rysů (popř. i některých rysů „redundantních“, nedistinktivních, avšak konstantních, invariantních). Ukazuje se, že pro češtinu lze za konstitutivní elementy vzorců pokládat vztah syntaktické závislosti, dále slovní druhy, některé morfologické kategorie a z malé části též slovosled. Větné vzorce tvoří hierarchicky uspořádaný systém, budovaný na principu protikladů, a lze jej zjistit např. postupem analogickým s postupem klasické pražské fonologie.[3] Jako příklad lze uvést např. vzorec (PROp1 →) VF → S4. Sled symbolů ve vzorci je irelevantní; v případě, že má slovosled platnost gramatickou, je to zvlášť vyznačeno.
Druhou složkou syntaktického systému jsou derivační pravidla. Jsou založena na principu syntaktické ekvivalence (tj. na možnosti substituovat nějakou složku vzorce složkou jinou). Jsou to jednak pravidla rozvíjecí (např. S ≡ S → A, VF ≡ VF → ADV), jednak rozšiřovací (např. S ≡ S1 + S2 + … + Sn). Vedle toho je třeba ještě počítat se substitučními pravidly v užším smyslu (např. PROp3 ≡ S) a s existencí potenciálních elementů (míst) vzorce (jsou vyznačeny závorkami). Kromě toho se v derivacích objevují omezující pravidla slovosledná a dále pak všeobecná i speciální pravidla o gramatické shodě.
Ke každému vzorci vi existuje množina derivačních pravidel Ri = {r1, r2, … }, která zároveň vymezuje množinu jeho derivací Di = {d1, d2, … dyi}. Množiny Ri, Rj, … nejsou nutně disjunktní. Každé jednotlivé derivaci di1 vzorce di odpovídá nějaká množina pravidel Ri1, jejichž aplikací byla ona derivace odvozena. Např. k vzorci vi: (PROp1 →) VF → S4 lze utvořit aplikací množiny pravidel Ri1 derivaci di1:
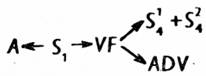
nebo v jiné notaci:
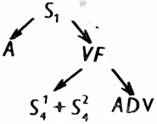
Je zřejmé, že množinu Ri1 tvoří tato pravidla: (r1) „dosazení na potenciální místo“ („škrtnutí závorek“); (r2) PROp3 ≡ S; (r3) S ≡ S → A; (r4) VF ≡ VF → ADV; (r5) S ≡ S1 + S2; přičemž každé pravidlo bylo (v tomto případě) aplikováno jen jednou. Pro názornost uveďme konkrétní příklad: větná výpověď (neboli stručně věta) Očekáváme přátele představuje jednu z možných realizací vzorce vi a věta Stará matka netrpělivě očekávala syna a dceru pak jednu z realizací derivace di1.
Systém větných vzorců a soubor derivačních pravidel vymezují abstraktní systém všech v daném jazyce možných větných struktur, neříkají však nic o způsobu promluvových realizací těchto struktur. I v rámci tradiční mluvnice zůstává např. nejasné, zda máme výpovědi jako Očekáváme přátele a Očekával [115]jste přítele pokládat za dvě varianty jedné a téže věty, popř. kolik je takových variant; podobně je tomu u různých variant slovosledných; nebo proč máme pokládat výpovědi jako Očekáváme přátele a Hledáme houby za dvě různé věty, když se syntakticky v ničem neliší; atp. Rovněž syntaktická homonymie zůstávala soustavně teoreticky do značné míry neinterpretována, pokládala se spíše za jakousi anomálii a příležitostnou nepatřičnost stylistickou. Obecně lze pak říci, že druhé dvě složky stavby jazyka, totiž morfologie a lexikon, nebyly dostatečně a ujasněně zapojeny do syntaxe.
Proto druhý komponent syntaktického popisu, jehož návrh předkládám, obsahuje zobrazení cesty, která vede od větného vzorce ke konkrétním výpovědím na něm založeným. (Ovšem i tyto výpovědi vykazují jistý stupeň zobecnění na rozdíl od jednotlivých jedinečných „výpovědních událostí hic, ego, nunc“.) Vztah mezi „větou“ a „výpovědí“ neodpovídá zcela vztahu mezi „langue“ a „parole“; soudím, že tato dichotomie (ostatně nikdy, pokud jde o pól „parole“, plně ujasněná) je příliš schematická a nahrazuji ji stupňovitě postupujícím zobecňováním od „výpovědní události“ až k „větnému vzorci“ (srov. práci citovanou v pozn. 3).
Tato cesta tedy vychází od nejobecnějšího syntaktického útvaru, od větného vzorce, a lze ji znázornit jakožto postupnou aplikaci pěti různých operací. Každá taková operace představuje vlastně pravidla pro realizaci elementů roviny vyšší na rovině o stupeň nižší, přičemž každému útvaru roviny vyšší odpovídá zpravidla (i když ne nutně) více (většinou mnoho) útvarů na nižším stupni; a dále pak v postupném provádění realizačních operací představuje každá operace postupnou „konkretizaci“, tj. postupné ubývání obecnosti: čím nižší je realizační rovina (tj. čím vyšší je její číslo), tím četnější a méně obecné (zobecněné) syntaktické útvary reprezentuje.
I.
vi = (PROp1 →) VF → S4
di1 = S1 → VF → S4 → A
První operace, zvaná derivování, představuje přechod od roviny větných vzorců na rovinu jejich derivací: každému vzorci odpovídá na této rovině alespoň jedna (zpravidla však mnohem více) derivace; pravidla pro tuto operaci představuje množina pravidel derivačních.
II.
rybář-1 → přines- → ryb-4 → mal-
Druhou operací se přiřazuje ke každé derivaci příslušná množina všech možných jejích lexikálních obsazení; vznikají tak různé (a zpravidla značně početné) lexikální variace dané derivace. (Lexikální jednotky jsou tu reprezentovány tvarotvorným kmenem slova.) Tato operace tedy předpokládá systematické zpracování lexika daného jazyka, a to takové, které u každé lexikální jednotky uvádí nejen její rysy sémantické, nýbrž i relevantní rysy syntaktické (např. rekci a jiná omezení týkající se možností syntaktického užití dané jednotky). Např. je zřejmé, že do derivace S1 → VF → S4 lze na místo VF dosadit jen takovou slovesnou lexikální jednotku, u které lexikální popis uvádí rekci s akuzativem. (Vedle toho existují ovšem i omezení rázu sémantického; ta však nerozhodují o gramatické (syntaktické) správnosti věty, [116]nýbrž jen o její „smysluplnosti“, resp. „(sémantické) normálnosti“; oba jevy nejsou však na sobě závislé.)
III.
|
|
rybář rybáři |
|
| přinese přinesl přinesl by byl by přinesl přinesou přinesli přinesli by byli by přinesli |
|
|
rybu ryby |
|
|
malou malé |
|
(1) rybář přinese rybu malou, (2) rybář přinesl rybu malou, … (5) rybář přinese ryby malé, … (9) rybáři přinesou rybu malou, … (12) rybáři byli by přinesli rybu malou, (13) rybáři přinesou ryby malé, … (16) rybáři byli by přinesli ryby malé.
Třetí operace přiřazuje ke každé lexikální variaci všechny její možné morfologické paradigmatické modifikace. Tato operace předpokládá systematicky zpracovanou morfologii, obsahující i všechny syntakticky relevantní údaje. Z hlediska této operace se jednotlivé lexémy každé lexikální variace dělí do čtyř tříd: (1) lexémy s morfologickými kategoriemi syntakticky vázanými, (2) lexémy s morfologickými kategoriemi syntakticky nezávisle proměnnými, (3) lexémy s morfologickými kategoriemi syntakticky závisle proměnnými, (4) lexémy bez morfologických paradigmatických kategorií. Přitom platí, že některé lexémy mohou patřit do více tříd (vzhledem k různým kategoriím: např. u subst. může být pád vázán, avšak číslo nezávisle proměnné). Při této operaci se též aplikují pravidla kongruenční (u kategorií syntakticky závisle proměnných) a dále pak mizejí symboly označující závislost (pokud nejsou vázány slovosledně).
IV. Čtvrtou operací se přiřazuje ke každé paradigmatické modifikaci množina všech jejích přípustných slovosledných variací. (Zřejmě ovšem jen takových, které nejsou podmíněny gramaticky. Gramaticky podmíněný pořádek slov, ať už s funkcí znaku distinktivního, nebo pouhé konstanty, je vyjádřen už ve vzorcích, resp. v derivačních pravidlech, a projeví se na této rovině jako omezení variačních možností; symbol tohoto gramatického pořádku slov ovšem při této operaci mizí.)
V. Poslední operací je intonační ztvárnění: ke každé slovosledné variaci se přiřazuje množina jejích intonačních podob; toto ztvárnění záleží v realizaci syntakticky relevantních intonačních forem. (Intonačními formami se tu rozumějí systémové zvukové prostředky suprasegmentální, tedy typy intonačních kontur, umístění intonačního centra, předěly.) — V jazykových projevech realizovaných graficky odpovídá této operaci analogická operace grafická; ta však disponuje prostředky mnohem chudšími.
Poněvadž jde o operaci poslední, je zřejmé, že její výstup tvoří už hotové větné výpovědi (ovšem brané izolovaně, bez kontextu a situace). Tím způsobem jsme tedy obdrželi nakonec množiny větných výpovědí založených vždy na jednom a témž větném vzorci (přiřazených k němu). Nejen že jsme tím překlenuli proluku mezi abstraktními syntaktickými strukturami a konkrétním sledem konkrétních jazykových prvků v realizované výpovědi, proluku, o níž někteří stoupenci Chomského gramatické teorie tvrdí, že je pro závislostní [117]gramatiku nepřeklenutelná, a tím jsme specifikovali a popsali vztah mezi tím, co Šaumjan nazývá „genotypem“ a „fenotypem“ a Curry zase „tektogramatikou“ a „fenogramatikou“ (a co naopak u Chomského koncepce zůstává nevyjasněné a nerozlišené), nýbrž jsme i zároveň naznačili možnost soustavného popisu hierarchického uspořádání větných výpovědí. Toto uspořádání by ještě lépe vyniklo, kdybychom načrtnuté generativní zobrazení převedli na zobrazení pomocí postupně zjemňovaného rozkládání množiny všech výpovědí na (nikoli nutně disjunktní) podmnožiny stále vyššího řádu. Dostali bychom tak soustavu množin (tříd) větných výpovědí spojených nejprve příslušností k témuž vzorci, na I. stupni rozkladu by se pak každá taková třída rozdělila na podtřídy vět patřících k téže derivaci, na II. stupni by šlo o třídy vět spojených nejen týmž vzorcem a touž jeho derivací, avšak též stejným lexikálním obsazením, atd. — A konečně náš postup dovoluje přesně definovat a vysvětlit syntaktickou homonymii a stanovit její typy i podmínky jejího výskytu.[4]
3. Náš výklad představuje jen dílčí pokus, budovaný na základě češtiny, vhodný však patrně pro slovanské jazyky vůbec a skýtající, doufám, předpoklady i pro studium porovnávací. Nechci ovšem vůbec tvrdit, že naše schéma podává úplný a plně adekvátní popis syntaktické složky jazykového systému a jejího fungování. Především nechává stranou sémantickou rovinu syntaktického plánu. Jak jsem naznačil před časem jinde,[5] i na této rovině lze předpokládat jisté vzorce a bude úkolem dalšího bádání zjistit jejich vztahy k vzorcům na gramatické rovině syntaktického plánu a zapojit je do celkového popisu (modelu) jazykového systému. Je rovněž zřejmé, že větné vzorce a jejich derivace v našem smyslu, budované na principu vztahu závislosti, postihují základní gramatickou strukturu věty, nepostihují však zcela všechny systémové složky výpovědi; musíme tedy předpokládat některá další pravidla, přistupující k tomuto strukturnímu základu (srov. i ve školské mluvnici např. tzv. „volné“ větné členy, slova bez větněčlenské platnosti, tzv. „větná příslovce“ apod.), atd. Pokládám za pozoruhodnou myšlenku S. Marcuse (srov. SaS 1964, s. 240), že jazyk nebude patrně možno zobrazit jedním modelem, nýbrž hierarchizovanou soustavou modelů (jako by se zde hlásila analogie pojetí jazyka jako systému systémů). A doplnil bych ji myšlenkou Andrejevovou,[6] že je třeba určit formalizovatelný „subjazyk“ uvnitř jazyka; ten je důležitý nejen pro kybernetiku, ale neméně i pro lingvistiku, neboť právě onen neformalizovatelný „zbytek“ nám pomůže objevit v jazyce ony důležité vlastnosti, které z něho dělají více než pouhý znakový kód pro stroj nebo strojové bytosti.
R é s u m é
ON SYSTEMATIC DESCRIPTION OF THE SYNTACTIC STRUCTURES OF SLAVIC LANGUAGES
1. Preliminary remarks: The recent development of studies in structural grammar may be characterized by several features (e. g. deduction, formalisation, generative models, etc.). Every work on a particular grammar must take these new trends into account.
[118]2. A sketchy account of one of the possible models of Czech syntactic structure: The presented conception is based on the principle of dependency grammar (as developed by S. Karcevskij and the Prague School) and on the fundamental opposition between an abstract linguistic system (la langue) and its particular realization in concrete utterances (de Saussure, V. Mathesius). It elaborates, completes and systematizes the traditional “sentence analysis (parsing)”.
As the basic systemic unit of the syntactic level of grammar is considered the sentence pattern; it may be roughly defined as a minimal configuration of distinctive (constitutive) syntactic features (the features being, in Czech: the relation of dependence, word classes, some morphological categories, partly the word order); e. g.: (PROp1 →) VF → S4. The set of all patterns represents a system; each grammatical sentence represents a realization of one of these patterns. The way leading from an underlying pattern to a set of all utterances based upon it (i. e. the process of all its possible realizations) can be described by the following succession of five operations:
(I) Derivation: by applying a proper subset of derivational rules on a given pattern one obtains a set of its derivations (e. g. ![]() . In derivations (as well as in patterns) only symbols denoting abstract grammatical categories and relations occur; in this respect, derivation is essentially different from the following operations which effect successive “concretizations” of the abstract scheme: the higher the running number of an operation, the less abstract (less general) are the structures produced by it.
. In derivations (as well as in patterns) only symbols denoting abstract grammatical categories and relations occur; in this respect, derivation is essentially different from the following operations which effect successive “concretizations” of the abstract scheme: the higher the running number of an operation, the less abstract (less general) are the structures produced by it.
(II) Filling in of lexical items: each word class symbol of a derivation is substituted (or realized) by one of the set of corresponding lexical items; in this way a set of lexical variations of the given derivation is produced. This operation presupposes a systemic description of the lexicon (every lexical item must be characterized not only by its semantic, but also by its syntactically relevant grammatical features).
(III) Morphological modifying: by this operation a set of morphological (paradigmatic) modifications is adjoined to each lexical variation. This operation presupposes a systemic description of the morphological component of grammar.
(IV) Variations of word order (unless they are conditioned or restricted by the rules of grammar contained in patterns and/or derivations).
(V) Intonational formation of the sentence. (In written or printed utterances a corresponding, but rather poorer, graphic formation takes place.) — It is clear that the output of this last operation yields sentences in the sense of concrete utterances.
3. Final remarks: Our scheme makes possible, at the same time, to describe the hierarchical ordering of all grammatical sentences (particularly by means of a set-theoretical procedure) and allows to define and to explicate the syntactic (constructional) ambiguity, to determine its types and conditions of its occurrence.
The advanced tentative model gives account of a certain aspect of syntax only. Thus, e. g., the semantic plan has been purpously left aside at this first stage of research. Nevertheless, the semantic counterpart of grammatical sentence patterns is, undoubtedly, a significant component of any syntactic system; and our scheme admits of its future incorporation. It is also probably true that not all systemic items of grammatical sentence structures can be described in terms of dependence (therefore a small set of additional rules must be assumed). Etc. etc. It appears, that any natural language, being a “system of systems”, might be described by means of hierarchically ordered models only, and that the formalisation of the whole of a language, without any residue, may never be attained.
[1] Srov. k tomu bystrý postřeh K. Hausenblase v TLP 1, Praha 1964, s. 68, o tom, že obdobnou definici — i když ovšem jinak zdůvodněnou — nalézáme u starších gramatiků, např. i u J. Gebauera: „Jazyk je úhrn vět“ (Mluvnice česká, 1890, s. 187).
[2] Jde o princip známý z ženevské školy, rozpracovaný Karcevským („syntagma“) a pak v pražské škole zejména Havránkem a u nás běžný jeho zásluhou dokonce i v školních učebnicích („syntaktická“ nebo větná dvojice“).
[3] Podrobněji o tom viz v autorově přednášce Větný model a větný vzorec, otištěné ve sb. Čs. přednášky pro V. mezinárodní kongres slavistů, Praha 1963, s. 115—124.
[4] Srov. k tomu autorovu stať Opyt teoretičeskoj interpretacii sintaksičeskoj mnogoznačnosti, VJaz 1964, č. 6, s. 3—16.
[5] Viz závěr cit. stati A Three Level Approach to Syntax, TLP 1, 1964, s. 225—236; srov. k tomu též P. Sgall, Zur Frage der Ebenen im Sprachsystem, tamtéž s. 95—106.
[6] Srov. jeho stať Model as a tool of linguistic description, Word 18, 1962, 65—69.
Slovo a slovesnost, ročník 26 (1965), číslo 2, s. 112-118
Předchozí Oldřich Leška, Pavel Novák: K otázce „strukturní analýzy“ jazyka
Následující Jozef Ružička: Vzťahy medzi morfológiou a syntaxou
© 2011 – HTML 4.01 – CSS 2.1