
Nová podoba významové báze popisu jazyka
Petr Sgall
[Články]
Новая форма семантической базы описания языка / Une forme nouvelle de la base sémantique dans la description de la langue
V diskusích o koncepci nové vědecké mluvnice češtiny připravované v ÚJČ ČSAV (viz nyní zejm. K. Horálek v SaS 38, 1977, s. 10) se uvažuje o sémantické bázi gramatiky. Na sémantické bázi je založen také popis češtiny vypracovávaný metodami algebraické lingvistiky, k jehož cílům patří ukázat, že základem přirozeného jazyka je systém s určitými vlastnostmi charakteristickými pro jazyky lidstva jako takové. Chceme-li takové vlastnosti výslovně popsat, a ne jen obrazně naznačit, potřebujeme propracovaný pojmový aparát, který ztěžuje četbu, ale zato značně zvyšuje kontrolovatelnost předpokládaných řešení.
Sémantická báze měla původně formu nekontextové gramatiky, pak jsme přešli ke gramatice závislostní; po zjištění, že výpovědní dynamičnost jednotlivých doplnění slovesa odpovídá (zejm. pokud není snížena kontextovým zapojením) tzv. systémovému uspořádání, zavedli jsme další typ pravidel („metapravidla“).[1] Přitom však bylo třeba matematicky dokazovat, že báze charakterizuje významové zápisy jako prvky nekontextového jazyka.
Nová podoba báze, kterou zde předkládáme, je v tomto směru výhodnější; má podobu zásobníkového automatu o osmi pravidlech (přesněji jde o schémata pravidel, viz tab. 1; sestavil je J. Sgall) a o zásobníkových automatech bylo už dávno formálně dokázáno, že popisují právě množinu nekontextových jazyků (o vlastnostech zásobníkových automatů jsme psali v cit. knize, zejm. s. 104—108; odchylujeme se od tehdejší definice jen nepodstatně). Automat nemá žádnou vstupní abecedu, a můžeme ho tedy nazývat gramatikou. Každé pravidlo určuje, zda při jeho uplatnění je čten na přístupném konci zásobníkové paměti (a vymazán) symbol určitého typu, dále stanoví, jak se vnitřní stav automatu mění (ve směru šipky), co se do paměti nově ukládá a co se objevuje na výstupu. Vnitřní stav má čtyři části: (1) označení, zda rozvíjíme daný výskyt slova doplněními kontextově zapojenými (KZ), nebo nezapojenými (KN) — symboly t, f; (2) slovní druh rozvíjeného slova (s vyznačením negace indexem); (3) vyznačení, zda rozvíjené slovo je KZ (a zda může být ohniskem, nebo je mu možné ohnisko podřízeno);[2] (3) posloupnost typů rozvití, které ještě lze na dané slovo uplatnit.
Zápisy mají podobu linearizace závislostních stromů, kde jsou závislé členy zapsány za svým členem řídícím (v pořadí stoupající výpovědní dynamičnosti), každý z nich je uzavřen dvojicí závorek, horní index označuje, zda je to člen KZ, a dolní index u závorky je číslem typu doplnění. Nezabýváme se tu popisem morfologických významů, ani složením významů lexikálních; třídění slovních druhů i zachycení syntaktické kombinatoriky různých tříd slov musí ovšem být značně zjemněno.
Pravidlo 1. generuje řídící slovo (vrchol závislostního stromu), pravidlo 6. generuje slovo závislé, pravidlem 8. se zachycuje typ závislosti a vracíme se k rozvíjení řídícího slova; aplikací pravidel 3. a 5. se rozhodujeme neuplatnit v daném bodě rozvití daného typu (n); pravidlo 4. odpovídá přechodu od rozvití KZ ke KN; pravidly 2. a 7. lze generovat negaci.
Typy rozvití se dělí jednak na aktanty různého typu (každý typ rozvíjí daný výskyt slova jen jednou) a příslovečné (opakovatelné), jednak na obligatorní (séman-
[282]Tab. 1
| Zásobníková gramatika: | ||||||||||||
|
| ||||||||||||
| číslo | paměť | vnitř. stav | → | vnitř. stav | paměť | výstup | ||||||
| pravidla |
| 1 | 2 | 3 | 4 |
| 1 | 2 | 3 | 4 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
| 0 | 0 | 0 | 0 |
| t | B | h | 0 | rb, W | (bh |
| 2 | L | t | V | t | 0 |
| t | V1 | t | 0 | L | NEG |
| 3 | njk | t | C | he | s |
| t | C | he | s, njk |
|
|
| 4 | Dgn | t | C | he | s |
| f | C | he | 0 | s, Dgn |
|
| 5 | nk | f | C | he | 0 |
| f | C | he | 0 |
|
|
| 6 | njk | i | Dp | he | s |
| t | A | i | 0 | ra, Dhn, s, m | (ai |
| 7 | Dgn | f | Vj | z | 0 |
| f | V2 | z | 0 | Dgn | NEG |
| 8 | Dgn | f | C | he | 0 |
| h | D1 | gq | 0 |
| )n |
| výchozí stav: |
|
0 |
0 |
0 |
0 |
|
|
|
|
|
|
|
| koncový stav: |
|
h |
W1 |
01 |
0 |
|
|
|
|
|
|
|
| nepravý stav: |
|
h |
W1 |
0 |
0 |
|
|
|
|
|
|
|
ticky) a fakultativní; příslovečná doplnění fakultativní nazýváme volná. Podle systémového uspořádání číslujeme typy rozvití takto:
1 — všeobecný vztah (černý stůl, dva lidé)
2 — agens (konatel, včetně nositele stavu n. vlastnosti)
3 … 7 — čas: kdy, odkdy, dokdy, jak často, jak dlouho
8 — místo (kde)
9 … 13 — způsob, míra, měřítko (podle stanov), nástroj (prostředek), prostředí (kudy)
14 — adresát
15 — původ (i původce)
16 — směr odkud
17 — patiens
18 — směr kam
19 — výsledek
20 … 23 — prospěch, podmínka, účel, příčina
24 — kvantifikátor (nečíselný: každý, některý)
25 — příslušnost (Pavlův bratr)
26 — partitiv (balík papíru)
Naše gramatika předpokládá, že ve slovníku jsou u jednotlivých lexikálních významů (zatím předběžně zapisovaných jen v povrchové podobě) uvedeny rozvíjecí rámce jako posloupnosti vzestupně uspořádaných čísel označujících typy možných rozvití (horní index 1 označuje obligatornost, dolní index 1 aktant):
V: spát 211, 3, …, 13, 16, 18, 20, …, 23; mít 211, 3, …, 13, 16, 1711, 18, 20, …, 23; kupovat 211, 3, …, 13, 151, 16, 1711, 18, 20, …, 23; přijít 211, 3, …, 13, 16, 181, 20, …, 23;
N: nemoc, čas 1, 241; únava 1, 241; bratr 1, 241 251; Honza 1, 251; balík 1, 241 261; učitel 1, 171, 241 251;
Adj: černý 10; plný 11, 10; užitečný 10, 141; dva 10;
Adv: nalevo 10, 161; tady 10
[283]Platnost symbolů:
a, b jsou lexikální jednotky; ra, rb jsou jejich rozvíjecí rámce (tj. vzestupně seřazená čísla všech typů jejich možných doplnění, včetně doplnění volných);
n je číslo doplnění; v pozici indexu je n také za 0;
A je slovní druh lexikální jednotky a;
B (slovní druh lexikální jednotky b) je V, Interj nebo N (vokativ);
D je slovní druh (V, N, Adj, Adv, Pron, …) nebo W;
W je pomocný symbol pro nepřístupný konec zásobníku;
C má obdobnou platnost jako D, ale je i za symboly V1, V2, N1, Adj1, Adv1, Pron1, …;
i, h jsou proměnné za t (KZ) nebo f (KN);
g je za t, f nebo 0;
L je za symbol tvaru Dng nebo tvaru nkj;
s je posloupnost symbolů tvaru nkj;
e, j, k, p jsou proměnné za 0 nebo 1;
z má obdobnou platnost jako he, ale nikdy není za t0;
m je za symbol n, pokud má na levé straně téhož pravidla k platnost 0; jinak má m platnost 0;
q má platnost 0, jestliže he na levé straně téhož pravidla je za t0; jinak má q platnost 1;
index 0 nerozlišujeme od nepřítomnosti indexu; zásobníkovou paměť zapisujeme tak, že symbol zapsaný nejdále vlevo je na přístupném konci zásobníku (ukládá-li se tedy posloupnost mající tvar 1, 2, 4, uložíme do zásobníku nejdříve 4, pak 2 a nakonec 1, takže 1 pak bude na přístupném konci zásobníku).
Činnost gramatiky začíná od výchozího stavu; pak se aplikují jednotlivá pravidla v libovolném pořadí, pokud je vnitřní stav ve shodě s levou částí pravidla (často je možná volba mezi uplatněním dvou pravidel). Dospějeme-li k takovému vnitřnímu stavu, na který nelze žádné pravidlo aplikovat, je to buď stav koncový, a byl tedy generován významový zápis české věty, nebo je to tzv. stav nepravý, a pak se vzniklý řetěz od správně tvořeného významového zápisu věty liší tím, že neobsahuje žádné ohnisko.
Rozlišení významových zápisů s ohniskem od řetězů bez ohniska je umožněno uplatněním symbolu q v pravidle 8, které zajišťuje, že jako správně tvořené jsou charakterizovány i významové zápisy, ve kterých je ohniskem např. jen přívlastek, jako je tomu třeba u věty To je učitel angličtiny, je-li odpovědí na otázku Který je to učitel?
Gramatika také zachycuje tři možné pozice negace;[3] tři významové zápisy věty Honza nespí k vůli únavě (s normální intonací) odpovídají po řadě možným kontextům (a) …; jestli vůbec spí, tak jen proto, že si vzal prášek; (b) …; spí jen proto, že si vzal prášek; (c) …; když je takhle přetažený, nemůže nikdy usnout.
(1) (spíf (Honzat)2 (únavaf)23 NEG)0 — linearizace stromu z obr. 1,
(2) (spít (Honzat)2 (únavaf)23 NEG)0,
(3) (spít NEG (Honzat)2 (únavaf)23)0.
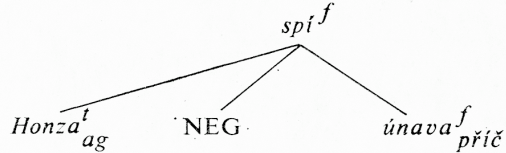
Obr. 1
[284]Horní indexy u symbolů pro slovní druhy zajišťují, že 2. a 7. pravidlo se nemohou aplikovat opakovaně a že NEG stojí buď za ohniskem klauze (prav. 7; v dosahu negace je pak ohnisko), nebo za KZ slovesem (prav. 2; v dosahu negace je pak jen sloveso samo). Protože považujeme za správně tvořenou a smysluplnou českou větu i např. větu Nepřišel jsem ne pro nemoc, ale proto, že jsem neměl čas, připouštíme uplatnění 2. i 7. pravidla na týž výskyt slovesa (viz odpovídající významový zápis v obr. 2).
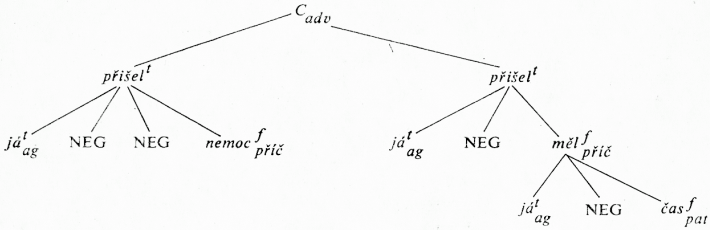
Obr. 2
Pořadí uplatněných pravidel pro zápis (1): 1 (výstup: „(spíf“; paměť: „211, 3, …, 13, 16, 18, 20, …, 23, W“), 6 (výstup: „(Honzat“; paměť: „1, 251, Vt2, 3, …, 13, 16, 18, 20, …, 23, W“), 3, 3 (přitom postupně vyjímáme z paměti čísla 1 a 25, neboť slovo Honza nemá mít žádné KZ rozvití), 4 (přecházíme k možnosti rozvití KN), 5, 5 (opět nerozvíjíme), 8 (výstup: „)2“; slovo Honza už rozvito nebude, vracíme se k rozvíjení řídícího slovesa 3, 3, …, 3 (opakuje se sedmnáctkrát, neboť sloveso už nemá mít další KZ rozvití; čísla dosud možných rozvití se postupně přenesou do 4. části vnitřního stavu), 4 (přecházíme k rozvitím KN), 5, 5, …, 5 (opakuje se šestnáctkrát a z paměti se postupně vyjímají čísla neuplatněných doplnění), 6 (výstup: „(únavaf“; v paměti nyní je posloupnost „1, 241, Vf23, 23, W“), 3, 3, 4, 5, 5, 8 (výstup: “)23“; slovo únava zůstalo bez rozvití), 5, 7 (výstup: „NEG“; do paměti zpět ukládáme symbol W), 8 (výstup: „)0“).
Pořadí uplatněných pravidel pro zápis (2) je shodné s pořadím pro (1); rozdíl je jen v tom že hodnota vrcholu stromu má index t, nikoli f. Pro (3) se pořadí liší v tom, že hned po uplatnění pravidla 1 aplikujeme prav. 2; prav. 7 se tu neuplatňuje.
R É S U M É
A New Form of a Semantic Base
A pushdown automaton generating linearizations of dependency trees is described. The generated strings can be interpreted as semantic representations of sentences; the distinction between topic and focus, as well as the scale of communicative dynamism are represented by relatively simple means.
[1] Původní podobu báze jsme popsali v knize Generativní popis jazyka a česká deklinace, Praha 1967; čistě závislostní gramatiku navrhujeme v PSML 2, 1967, 203—225; o metapravidlech píšeme spolu s E. Hajičovou a V. Koubkem ve sb. Explizite Beschreibung der Sprache … III, Praha 1977, 5—80.
[2] K definici ohniska viz P. Sgall — E. Hajičová — E. Buráňová, Aktuální členění věty v češtině, v tisku v nakl. Academia, odd. 1.15.
[3] Viz E. Hajičová, Negace a presupozice ve významové stavbě věty, Praha 1975, zejm. s. 93n. a s. 100.
Slovo a slovesnost, ročník 39 (1978), číslo 3-4, s. 281-284
Předchozí Přemysl Adamec: Složené propozice a jejich syntaktické realizace v ruštině
Následující Miroslav Komárek: K pojetí povrchové a hloubkové struktury
© 2011 – HTML 4.01 – CSS 2.1