
Analýza koartikulačních vlivů na časové mikročlenění souhláskových skupin
Blanka Borovičková, Vlastislav Maláč
[Articles]
Анализ коартикуляционных влияний на временное микрочленение групп гласных / L’analyse des influences co-articulatoires sur la microarticulation temporelle des groupes consonantiques
První polovina sedmdesátých let se v experimentální fonetice vyznačuje mimořádně velkým zájmem o strukturu a význam časových zákonitostí v produkci a percepci řeči. Tento zájem, který je příznačný pro celý fonetický svět,[1] není nahodilý, ale zcela zákonitě vyplývá jednak ze stále se prohlubujícího vědeckého poznání akustických zákonitostí, jednak z integračních procesů vědeckého bádání, které stále naléhavěji spojují obory v minulosti naprosto nesouvisející. Máme zde na mysli zejména výpočetní techniku, která nezadržitelně prostupuje veškerou vědeckou, zejména experimentální práci. Nadto pronikání počítačů i do nejvšednějšího dění vyžaduje, aby počítač byl schopen komunikovat s člověkem řečí v její původní, akustické podobě. Tím se stává spolupráce badatelů z oboru fonetiky a výpočetní techniky nezbytnou podmínkou vývoje vědeckého poznání.[2] Jejich spolupráce se zvláště uplatňuje ve dvou tematických okruzích. Jde o modelování produkce řeči,[3] tedy o tvoření syntetického akustického signálu, a o modelování percepce řeči,[4] tj. o automatickou analýzu řeči a její poznávání. První okruh byl vyvolán na jedné straně zavedením syntetizérů do základní metodologie fonetického výzkumu, na straně druhé velkým zájmem počítačových pracovníků, aby zajistili schopnost počítače „mluvit“. Druhý okruh, který je do velké míry podmíněn úspěšným řešením úkolů okruhu prvního, je vyvoláván naléhavou potřebou řídit stroje hlasem a snahou automatizovat analyzační fonetické postupy. Rozvoj této oblasti zvlášť uspíšilo dvouleté studium skupiny předních amerických odborníků různých vědeckých disciplín v l. 1970—1971 (Advanced Research Projects Agency of Department of Defense). Na toto studium navazoval čtyřletý mezioborový plán výzkumu s cílem vytvořit systém, který by rozuměl souvislé řeči se slovníkem 1000 slov.[5]
Rozvoj syntetizérů v druhé pol. let šedesátých nebývalou měrou rozšířil poznání percepční závažnosti zejména rychlých změn akustického spektra hlásek a jejich kombinací. Odhalení těchto zákonitostí zpětně poskytlo technice možnost připojit syntetizér jako výstupní periférii počítače. Spojení syntetizéru s počítačem (počátkem 70. let) bylo dalším kvalitativním skokem v metodologii studia fonetické stránky řeči. Možnost snadno tvořit delší řečové úseky vedla na jedné straně k výzkumu časového členění řečového signálu a na straně druhé k novým metodám zkoumání těchto zákonitostí. Ukazuje se totiž, že při výzkumu větších celků, než jsou hlásky a jejich jednoduché kombinace typu konsonant vokál (dále CV), už nelze získávat podrobné informace o struktuře řeči pouhou analýzou zkoumaných jevů. Analýza delších řečových úseků vyžaduje zkoumat rozsáhlé materiály, a pokud jsme odkázáni na čtení akustických hodnot ze spekter, pak počet takových čtení jde do mi[40]liónů. Proto se preferuje nová metoda, která spočívá v předběžném stanovení nejčetnějších zákonitostí analýzou malých materiálových sond. Na základě takto získaných výsledků je nutno vypracovat konceptuální model, který je pak ověřován poslechem. Předností tohoto způsobu je, že rychleji pronikneme do základních zákonitostí jevu a výsledky zároveň prověřujeme v technické praxi. Tímto přístupem se eliminují málo četné výjimky, a proto je nutno zdůraznit stochastickou povahu modelu.
Tyto nové směry ve fonetickém výzkumu nejsou pouze výsadou velkých zahraničních laboratoří. Dlouholetá mezioborová spolupráce v oblasti výzkumu řeči u nás má stejnou úroveň. Protože i u nás je syntéza řeči na vysokém stupni vývoje vědeckého poznání a v současné době jsou hotovy první programy pro převod psané formy řeči na její formu mluvenou pomocí počítače, mohli jsme také přejít od výzkumu frekvenční struktury řeči k výzkumu její struktury časové.
Než přikročíme k popisu vlastních prací, zmíníme se v krátkosti o výsledcích nejnovějších prací zahraničních. Soustředíme se především na dvě přehledové práce, D. H. Klatta, člena laboratoře počítačového výzkumu MIT,[6] a N. Umedové, pracovnice z Bellových laboratoří.[7] V obou pracích je podán obsáhlý seznam dalších publikací, které vyčerpávajícím způsobem zachycují výzkum oboru zejm. v posledních pěti letech, včetně informací o podnětném leningradském sympoziu Auditory Analysis and Perception of Speech z r. 1973, jehož podstatná část byla také věnována časové organizaci souvislé řeči.[8]
Klatt tu podává výsledky svých prací z l. 1972—1975 týkající se typů různých faktorů, které spoluvytvářejí trvání jednotlivých segmentů věty v souvislé řeči. Všímá si jednotlivě samohlásek i souhlásek a výsledky analýzy shrnuje v souboru rovnic, kterými lze vypočítat trvání jednotlivých segmentů souvislé řeči. Velká část práce je věnována percepční závažnosti změn v trvání hlásek.
Zatímco Klattova práce problematiku časového členění souhláskových skupin pouze naznačuje, jsou souhláskové skupiny podstatnou částí práce N. Umedové. Všímá si všech parametrů ovlivňujících trvání jednotlivých hlásek, i když některé běžně uznávané parametry na základě výsledků vlastní práce odmítá.
Výsledky obsáhlé analýzy souhlásek a jejich skupin jsou pak shrnuty v 7 tabulkách, které slouží jako podklad k výpočtu trvání souhlásek. Jde o model, který určuje trvání souhlásek v různých kontextech s velkou přesností — na rozdíl od modelu Klattova, který je zejména v údajích o souhláskových skupinách značně nepřesný.
Počátkem sedmdesátých let vyvstala i v našem výzkumu nezbytnost zabývat se podrobněji časovým členěním řeči.[9] Tato nezbytnost vyplynula zákonitě ze základní koncepce našeho dlouhodobého výzkumu akustické podstaty češtiny.[10] Ke konečnému cíli se dostáváme rekurentním postupem v cyklech, jejichž první fází je vždy analýza akustických spekter přirozeného signálu řeči a druhou fází percepční ověřování zjištěných zákonitostí poslechem. V druhé fázi jsme vzhledem k rozvoji [41]moderních metod přešli od přirozeného signálu dodatečně upraveného (např. potlačováním určitých kmitočtových oblastí[11]) k signálu syntetickému.[12]
Skončili jsme úspěšně výzkum podstaty akustické struktury základních řečových jednotek typu CV. Poznatelnost těchto jednotek (synteticky vytvořených) dosáhla 93 %. Při tom byly řešeny i některé obecné zákonitosti produkce a percepce řeči, jako jsou problém okluzív[13] a otázka znělosti v češtině.[14]
V těchto experimentech jsme se soustřeďovali převážně na frekvenční strukturu hlásek. Časové mikročlenění jsme řešili druhotně, jednak proto, že se naše výsledky analýzy v podstatě nelišily od výsledků počátku experimentální fonetiky J. Chlumského,[15] jednak proto, že vztahy v základních jednotkách CV jsou poměrně jednoduché (srov. B. Borovičková - V. Maláč, o. c. v pozn. 10). Teprve ve druhé části našeho výzkumu, když jsme přecházeli k sledování vyšších celků, především souhláskových skupin, se ukázalo nezbytné sledovat i časové mikročlenění. Zjistili jsme, že se časové členění souvislé řeči řídí velmi složitými zákony. V té době ještě nebyly publikovány žádné práce postihující problematiku časového mikročlenění jako celku, ani pro češtinu, ani pro jiné jazyky. Citovaná práce J. Chlumského má jen velmi stručnou zmínku o souhláskových skupinách a nejinak je tomu v literatuře zahraniční. Pokud se někteří autoři zabývali otázkou mikročlenění, pak ji spíše formulovali jako poznání hranice, za níž je hláska artikulována již mimo normu, nebo si všímali jen jedné hlásky nebo hláskové skupiny, např. okluzív v samohláskovém kontextu. Tyto hlásky byly také analyzovány ve větách, v nichž trvání je měněno buď přirozenými prostředky (např. přízvukem), nebo uměle, tj. změnami zaváděnými buď do přirozeného signálu,[16] nebo realizovaným signálem syntetickým.[17] Tento druhý způsob byl použit při odvozování modelu artikulace dvoučlenných souhláskových skupin pro účely automatické syntézy řeči. Model byl vytvořen podle výsledků analýzy akustických spekter a elektromyografického měření artikulačního úsilí při závěru okluzív. Nevýhodou tohoto modelu je, to připouští i sám autor, rozšíření zákonitostí pro explozívy na všechny souhlásky.
Náš výzkum směřující k vytvoření modelu popisujícího časové členění řeči je založen na myšlence, že v časovém mikročlenění jednotlivých hlásek v souvislé řeči se projevují dvojí účinky. Jsou to účinky jednak koartikulace, jednak realizace suprasegmentálních rysů, které postihují vyšší celky promluvy (slabiky, slova, věty). Abychom mohli obojí účinky od sebe vzájemně oddělit, rozhodli jsme se použít jako experimentálního materiálu izolovaná „slova“, v nichž se souhlásky i souhláskové skupiny vyskytují v symetrickém samohláskovém okolí. Poněvadž jde v zásadě o bezesmyslová slova typu VCCV, jsou suprasegmentální účinky maximálně potlačeny a měřením trvání jednotlivých hlásek můžeme stanovit zákonitosti časového mikročlenění dané koartikulací. Takto zjištěné zákonitosti pak ověříme v souvislé řeči jak analýzou signálu přirozeného, tak tvořením signálu syntetického. Z analýzy přirozeného signálu lze pak odečtením zákonitostí časového mikročlenění odvodit zákonitosti časového členění větších celků promluvy. Tento postup je ob[42]dobou hledání relevantních melodických průběhů (kadencí nebo melodémů). Průběh melodie věty je velmi členitý a většina dílčích změn melodie je způsobena koartikulací hláskových posloupností, jak je patrno z obr. 1. Odečteme-li mikromelodické změny, získáme typický průběh otázky zjišťovací (průběh b na obr. 1).
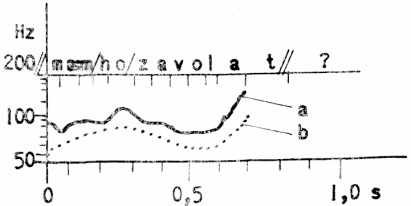
Obr. 1. Průběh melodie věty: Mám ho zavolat?
Křivka a zobrazuje úplný průběh melodie, křivka b melodii po odečtení mikromelodických změn
Je známo, že čas fyzikální se od času fyziologického liší. Tímto problémem se zabývají některé zahraniční laboratoře a došly k zajímavým i důležitým výsledkům.
Např. A. W. F. Huggins[18] zjistil, že člověk je citlivější na změny trvání u samohlásek než u souhlásek. Skupina pracovníků berkleyské univerzity[19] objevila, že soud o délce samohlásek je závislý na melodii tak, že stoupavá melodie činí samohlásku v percepci delší než melodie klesavá a nejkratší samohlásku tvoří melodie s konstantním průběhem. V téže práci je zmínka i o vlivu druhu samohlásky na její percepční trvání. Čím je samohláska vyšší, tím zní pro posluchače déle. Např. u stejného fyzikálního trvání samohlásek /a/ a /i/ hodnotilo 60 % posluchačů samohlásku /i/ jako delší.
Z experimentů z hlediska časového členění jsou pro nás nejzávažnější ty, které si všímají právě postřehnutelné změny trvání akustického signálu. S. M. Abel[20] se zabýval rozlišitelností změn v trvání filtrovaného šumu a jednoduchého tónu o frekvenci 1 kHz.
Změnou trvání segmentů řeči se zabývá D. H. Klatt (o. c. v pozn. 6) a srovnává své výsledky s výsledky experimentů Fujisakových.[21] Odmítá přijmout hodnotu 10 ms jako minimální, protože byla dosažena při mnohonásobném opakování stejného úseku promluvy (v takovém případě je posluchač schopen koncentrovat svou pozornost a minimalizovat její odklony; to neodpovídá běžným percepčním pochodům při poslechu souvislé řeči). Podle jeho experimentu právě postřehnutelná změna trvání řečového segmentu je 25 ms (tj. zhruba 20 % trvání segmentu).
Tyto hodnoty odpovídají výsledkům našeho experimentu se syntetickým slovem „papa“, v němž jsme měnili trvání první nebo druhé slabiky (s minimálními kroky 3 ms: 3 % trvání samohlásky). Při změně do 10 % trvání byly odpovědi posluchačů zcela nahodilé. Teprve nad touto hodnotou byli posluchači s to určit správně, která z obou slabik je delší.
[43]Zajímavé jsou výsledky experimentů zjišťujících přesnost produkce segmentů řeči, které publikoval ve své disertační práci S. G. Nooteboom.[22] Zjistil, že přesnost vyslovování slabik byla menší než 10 ms a u jednoho mluvčího dokonce kolem 3 ms. Naproti tomu Čistovičová a Koževnikov[23] uvádějí ve své práci hodnotu 10—15 ms.
Na základě našich experimentů jsme se rozhodli číst trvání hlásek ve spektrech s přesností 10 ms. Uvážíme-li, že je to zhruba hodnota trvání jednoho hlasivkového pulsu u mužského hlasu, mohli bychom větší přesnost zaručit jen stěží. Tím jsme schopni zjistit přesnost čtení 10—20 % i u hlásek trvajících pouze 50 ms; to nastává v některých případech v souvislé řeči, jak ukazuje obr. 2.
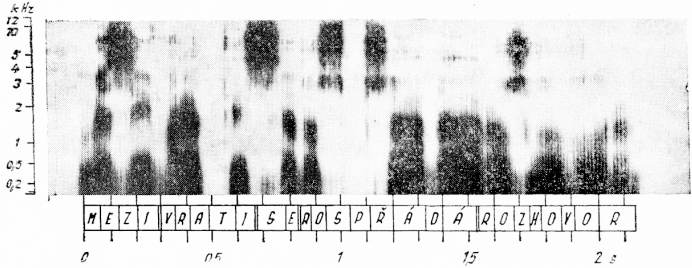
Obr. 2. Trojrozměrný spektrogram věty: Mezi vraty se rozpřádá rozhovor
Zde je zobrazeno trojrozměrné spektrum věty Mezi vraty se rozpřádá rozhovor. Na vodorovné ose odečítáme čas, na svislé kmitočet (výšku jednotlivých formantů) a zčernání je mírou hlasitosti příslušných částí spektra. Vyznačení časové dimenze pod spektrem je děleno po 100 ms; kmitočet je udáván v kHz. Pod obrázkem jsou vyznačeny ve vodorovném směru jednotlivé hláskové segmenty, do nichž jsou vepsány hlásky věty. Obrázek spektra ukazuje také potíže při určování trvání dílčích segmentů. Nejsnazší a zároveň také nejpřesnější je čtení trvání okluzí, zejména u neznělých okluzív. Bez velkých obtíží lze odečítat trvání frikativ s výjimkou /v/. Největší nejistotu máme při odečítání sonor /r, l/ a souhlásky /j/, jejichž spektrum vokalického charakteru se spojuje se spektrem sousedních samohlásek často jen pozvolnými změnami formantové struktury. To způsobuje nepřesnost v určení středu přechodu, který tvoří hranici segmentu. Akustické spektrum souvislé řeči lze tedy, až na malé výjimky, dělit na segmenty z hlediska artikulačního. Z hlediska precepčního však hranice segmentů obecně s hranicí hlásky nesouhlasí.[24]
Výchozím experimentálním materiálem pro náš výzkum jsou bezesmyslová izolovaná slova, tvořená souhláskami nebo skupinami souhlásek v symetrickém samohláskovém okolí, v němž se vyskytuje všech pět krátkých samohlásek.
U slov s jednotlivými souhláskami jsme použili souhlásky všechny. U souhláskových skupin
[44]
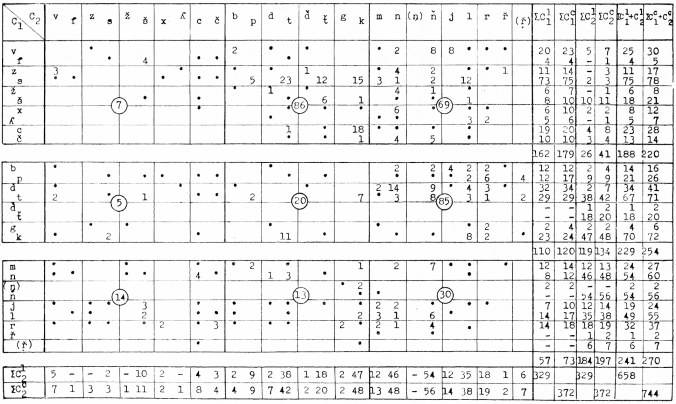
[45]jsme vycházeli z výsledků šetření J. Novotné-Hůrkové,[25] která zjišťovala četnost výskytu souhláskových skupin v souboru 22 000 slov statisticky vybraných z mluvených projevů (rozhlasové odborné besedy). I když v češtině se nevyskytují všechny teoreticky možné kombinace souhlásek, je jejich variabilita značná; materiál Novotné-Hůrkové vykazuje celkem 409 různých typů souhláskových skupin, z nichž nejčetnější jsou skupiny dvojčlenné. V mediálním postavení bylo zjištěno 216 typů, v iniciálním 114 a ve finálním postavení pouze 17. (Dvojčlenných typů různých je celkem 236.) K dalšímu zpracování jsme vybrali skupiny, jejichž četnost byla větší než 0,1 %. Tím jsme získali 80 typů dvojčlenných skupin mediálních, 38 iniciálních a 2 finální. Z tříčlenných skupin nám zbylo po tomto omezení jen 21 typů, u čtyřčlenných 5 typů a u pětičlenných už jen typy 2.
Jak se projevuje omezení našeho výběru na četnost větší než 0,1 % v celém souboru, je možno sledovat na příkladu dvojčlenných mediálních skupin v tab. I (na s. 44). Tabulka je maticí, v jejíchž řádcích můžeme číst první souhlásku skupiny (druh souhlásky je vyznačen v prvním sloupci), a ve sloupcích čteme druhou souhlásku skupiny u jednotlivých hodnot četnosti, které jsou číselně uvedeny jen u četností větších než 0,1 %; četnosti menší jsou vyznačeny tečkou. Ve výpočtech jsme pracovali s přesností desetin promile; zde jsme hodnoty pro větší přehlednost zaokrouhlovali.
U souhláskových skupin jsme se v první části výzkumu zaměřili nejprve na nejčetnější skupiny dvojčlenné v postavení mediálním. 80 souhláskových skupin a pět krátkých samohlásek vytvořilo celkem 400 slov typu VCCV. Takto vzniklá slova jsme dali přečíst profesionálnímu mluvčímu a ze záznamu jsme pořídili trojrozměrné spektrogramy a z nich jsme odečítali trvání jednotlivých hlásek.
Tab. II. Střední hodnoty trvání hlásek v ms (v řádcích označených t̄u až t̄Hi) a odchylky trvání těchto hodnot v dC (v řádcích označených ∆tu až ∆tHi) od celkové střední hodnoty trvání hlásky ve slově (168 ms)
|
|
|
|
|
| Hi |
|
|
| t̄Hi |
|
|
|
|
|
| |
|
|
| V̅ | C̅1 | C̅2 | V̅ | ΣVC1C2V | |
| t̄u | ms |
| 116 | 193 | 155 | 224 | 688 |
| ∆tu | dC |
| —0,2 | 0,2 | 0,6 | 0,1 | 0,1 |
| t̄o | ms |
| 122 | 183 | 140 | 232 | 677 |
| ∆to | dC |
| 0,0 | —0,1 | 0,1 | 0,1 | 0,0 |
| t̄a | ms |
| 131 | 184 | 135 | 241 | 692 |
| ∆ta | dC |
| 0,4 | 0,0 | —0,1 | 0,1 | 0,1 |
| t̄e | ms |
| 122 | 189 | 129 | 233 | 673 |
| ∆te | dC |
| 0,0 | 0,1 | —0,2 | 0,2 | 0,0 |
| t̄i | ms |
| 114 | 178 | 128 | 205 | 626 |
| ∆ti | dC |
| —0,2 | —0,2 | —0,3 | —0,4 | —0,3 |
| t̄Hi |
|
| 121 | 186 | 137 | 227 | 671 |
| ∆tHi | dC |
| —1,4 | 0,4 | —0,8 | 1,3 |
|
[46]V dalším postupu jsme se snažili sdružovat více hodnot v jedinou hodnotu průměrnou, abychom potlačili vliv individuální variability výslovnosti. Nejprve jsme zjišťovali, zda můžeme zanedbat vliv různého samohláskového okolí.
K tomu účelu jsme určili střední hodnoty trvání hlásek z pěti souborů 80 slov se stejným samohláskovým okolím. Výsledky jsou na tab. II. (s. 45) v lichých řádcích označených t̄u až t̄i. Ze středních hodnot trvání hlásek u všech 400 slov (předposlední řádka tabulky označená t̄Hi) jsme vypočetli odchylky trvání hlásek v jednotlivých souborech (v tabulce jsou uvedeny v sudých řádcích označených ∆tu až ∆ti).
Změny trvání nevyjadřujeme v absolutních mírách času (např. v ms), ale poměrovým číslem. Pro toto poměrové číslo zavádíme proti běžnému lineárnímu zobrazení např. v procentech, zobrazení logaritmické, které vyjadřujeme v dC,[26] nám umožňuje vzájemně porovnávat změny trvání jednotlivých hlásek přesto, že vlastní trvání hlásek se mění v širokém rozmezí.
Porovnáme-li vypočtené hodnoty ve sloupcích tab. II., pak zjistíme, že vliv samohláskového okolí na trvání souhlásek není velký, za předpokladu, že percepční poznatelnost změny trvání je jeden dC (20 %). Největší odchylku vykazují slova se samohláskou /i/, ale zkracují se jen o 0,3 dC. U jednotlivých hlásek jsou odchylky v rozsahu 0,0 až 0,6 dC, které nesouhlasí s odchylkami naměřenými ve slovech VCV; velmi často určitá samohláska způsobila prodloužení ve slovech VC1C2V a ve slovech VCV způsobila tatáž samohláska zkrácení slova. Vliv samohláskového okolí na trvání slov VCV jsme ověřovali ještě u dalších tří mluvčích; výsledek je negativní, změny trvání slov nepřesahují hodnotu ±0,1 dC a změny jednotlivých hlásek těchto slov nepřekročily hodnotu ±0,2 dC.
Protože nám analýza hodnot prokázala, že změny trvání v závislosti na samohláskovém okolí slov jsou pod prahem percepční závažnosti, sdružovali jsme v dalším zpracování vždy všech pět slov s různým samohláskovým okolím a se stejnou souhláskovou skupinou.
Jestliže změny v trvání jsou tak malé, jak ukazuje tab. II., můžeme také v dalším výzkumu časového členění zanedbávat nesymetrii samohláskového okolí. To nám velmi usnadní práci zejména při sledování změn trvání souhláskových skupin v souvislé řeči.
V posledním řádku tabulky jsou ještě vypočteny hodnoty odchylek ∆tHi průměrného trvání iniciální a finální samohlásky a obou souhlásek slova od čtvrtiny průměrného trvání slova VC1C2V (tím získáme průměrné trvání hlásky ve slově t̄H = 168 ms). Tato variabilita (počítaná ve vodorovném směru) je podstatně vyšší než variabilita hlásek v závislosti na samohláskovém okolí (počítaná ve svislém směru, ve sloupcích tabulky). Velký rozdíl v trvání mezi iniciální a finální samohláskou slova (2,7 dC, tj. téměř dvojnásobek) nepřekvapuje a byl zjištěn již [47]v pracích Chlumského (srov. o. c. v pozn. 15). Na druhé straně je velmi zajímavý rozdíl trvání mezi souhláskou na prvním a druhém místě skupiny (1,2 dC). Prodlužování první a zkracování druhé souhlásky skupiny souhlasí totiž s poznatkem Umedové (o. c. v pozn. 7, s. 885), která zjistila pro angličtinu tuto obecnou tendenci v chování souhlásek: Jsou kratší, následují-li po souhlásce, a delší, následují-li po samohlásce, dokonce bez ohledu na slovní hranici.
Jestliže tedy docházíme ke stejnému zjištění u tak rozdílných jazyků, jakými angličtina a čeština bezesporu jsou, můžeme soudit, že mnohé změny v trvání souhlásek, jako např. prodlužování první souhlásky skupiny a zkracování souhlásky druhé, tkví především v zákonitostech koartikulačních, a ne jazykových.
Termínem koartikulační zákonitosti rozumíme v tomto případě především ty zákonitosti, jimiž se řídí změny artikulačních orgánů, které vyplývají z fyzikálních vlastností mluvidel. Myslíme tu zejména na setrvačné hodnoty, které jsou překonávány silami svalů při přechodu z jednoho artikulačního postavení do druhého (od realizace jedné hlásky k následující). Zákonitosti jazykové jsou v této souvislosti především pravidla těch jazykových prostředků (např. přízvuku), která se uplatňují změnou trvání větších segmentů promluvy, než je hláska; tyto účinky jsou tedy měřitelné na více než jednom segmentu, přičemž tímto segmentem může být buď slabika, nebo větší celek promluvy.
Tím ovšem nepopíráme rozdílnost kvality hlásek v různých jazycích. Sronáváme-li však hlásky tvořící třídy podle artikulační příbuznosti (např. frikativy) jako celek, pak zvláštnosti různých jazyků ustupují a do popředí vystupují podobnosti; např. klesající trvání v řadě tříd: frikativy, okluzívy, jedinečné. Takové rysy jsou si podobné proto, že odrážejí podobné poměry artikulačního úsilí mezi jednotlivými třídami.[27]
K artikulačním zákonitostem patří i percepční závažnost tranzientů (přechodných dějů). Jde při tom o tranzienty jak v souhlásce samé, tak v samohlásce, která následuje. Závažnost těchto tranzientů je znakem obecným, platícím ve všech jazycích. Zjištěné zkracování druhé souhlásky skupiny proti souhlásce první vysvětlujeme především percepční závažností tranzientů následující samohlásky. První souhláska skupiny nemá totiž k dispozici samohlásku, na níž by se nezbytné přechodové jevy realizovaly, a proto si musí vytvořit k realizaci tranzientů náhradní prostor.
V souladu s naší hypotézou dvoukanálového řízení artikulace (blíže o tom v o. c. v pozn. 10, s. 9—12) je první souhláska skupiny artikulována na artikulačním postavení neurčité samohlásky, která se v četných případech vyskytuje jako zvláštní prvek mezi oběma souhláskami skupiny, na němž se nezbytné tranzienty první souhlásky realizují. Toto naše vysvětlení změn trvání v dvojčlenných souhláskových skupinách současně potvrzuje názor, že z percepčního hlediska mají tranzienty následující samohlásky podstatně větší význam než tranzienty samohlásky předcházející.
Dosavadní výsledky našich experimentů můžeme uzavřít tímto konstatováním: Potvrzuje-li námi zjištěná zákonitost (rozdílné trvání souhlásky na prvním a druhém místě skupiny) domněnku samostatných vlivů koartikulačních a jazykových (prozodických prostředků), pak další výzkum v oblasti časového mikročlenění není jen opodstatněný, ale nutný k určení správných hodnot časové dimenze prozodických rysů.
[48]R É S U M É
Analysis of Coarticulation Effect upon Microtiming in Czech Consonant Clusters
Our timing research of Czech is based on the assumption of different levels resulting the final consonant duration in continuous speech. First the microtiming, the lowest level of timing structure which is formed by coarticulation, was determined by means of VCCV type words analysis. The 80 most frequent two-consonant clusters were embeded in five different vowel symmetrical environments. Variations of sound duration were measured as a time ratio in logarithmic scale which basic unit forms decichron (dC) defined by the equation: 1 dC = 10 log10tm/tr, where tm is a measured sound duration and tr is a reference duration. The analysis of microtiming was realized with respect of the perceptually just noticeable difference. The first results of these analysis support the existence of different timing levels. Prolongation of the first and shortening of the second consonant in a cluster show us both the importance of vowel transitions for consonant perception and an agreement with the results of N. Umeda for English. Because of discovering finer microtiming sound structure further research is needed.
[1] L. V. Bondarko, Zvukovoj stroj sovremennogo russkogo jazyka, Moskva 1977, s. 16n., 140n.
[2] L. V. Bondarko - N. G. Zagorujko - V. A. Koževnikov - A. P. Molčanov - L. A. Čistovič, Model vosprijatija reči čelovekom, Novosibirsk 1968, 1—59.
[3] H. Wakita - G. Fant, Toward a Better Vocal Tract Model, Quarterly Progress and Status Report 1, Stockholm 1978, 9—29.
[4] M. P. Granstrem - V. A. Koževnikov - Ju. I. Kuzmin - D. M. Lisenko - L. A. Čistovič, Voprosy teorii i metodov issledovanija vosprijatija rečevych signalov, Sensornyje sistemy, Informacionnyje materialy, vyp. 32, No. 2, Leningrad 1971, s. 142n.
[5] K tomu srov. L. R. Rabiner, Scanning in Issue, Proceedings of the IEEE 64, No. 4, 1976, 403—404.
[6] D. H. Klatt, Linguistic Uses of Segmental Duration in English: Acoustic and Perceptual Evidence, The Journal of the Acoustical Society of America (JASA) 60, 1976, 1208—1221.
[7] N. Umeda, Consonant Duration in American English, tamtéž 61, 1977, 846—858.
[8] Auditory Analysis and Perception of Speech, ed. by G. Fant and M. A. A. Tatham, New York 1975.
[9] Termínem časového členění překládáme anglický výraz timing a v nejširším významu slova jím rozumíme ‚strukturu trvání určitých jednotek souvislé řeči‘. Přitom zavádíme termín časové mikročlenění pro ‚strukturu trvání jednotek nejmenších‘, tj. hlásek a jejich kombinací na úrovni slabiky.
[10] B. Borovičková - V. Maláč, The Spectral Analysis of Czech Sound Combinations, Praha 1967.
[11] B. Borovičková, Zjišťování relevantních oblastí hlásek v češtině, SaS 25, 1964, 26—30.
[12] B. Borovičková - V. Maláč, Využití umělého akustického signálu řeči v experimentální fonetice, SaS 29, 1968, 398—406.
[13] B. Borovičková - V. Maláč - M. Sedláková, Nové směry ve výzkumu explozív, SaS 35, 1974, 307—315.
[14] B. Borovičková - V. Maláč, Klasifikace znělosti u explozív v češtině, SaS 36, 1975, 285 až 294.
[15] J. Chlumský, Česká kvantita, melodie a přízvuk, Praha 1928.
[16] A. W. F. Huggins, On the Perception of Temporal Phenomena in Speech, JASA 51, 1972, 1279—1290.
[17] I. H. Slis, Synthesis by Rule of Two-Consonant Clusters, Annual Progress Report of the Institute for Perception Research 9, 1974, 64—69.
[18] A. W. F. Huggins, Just Noticeable Differences for Segment Duration in Natural Speech, JASA 51, 1972, 1270—1278.
[19] W. S. Y. Wang - I. Lehiste - C. K. Chuang - N. Darnovsky, Perception of Vowel Duration, JASA 60, 1976, Suppl. No. 1, s. 92.
[20] S. M. Abel, Duration Discrimination of Noise and Tone Burst, JASA 51, 1972, 1219—1223.
[21] H. Fujisaki - K. Nakamura - T. Imoto, Auditory Perception of Duration of Speech and Non-Speech Stimuli, Auditory Analysis and Perception of Speech, New York 1975, 197—220.
[22] S. G. Nooteboom, Production and Perception of Vowel Duration, Institute for Perception Research, Eindhoven 1972.
[23] L. A. Čistovič - V. A. Koževnikov, Mechanizmy rečeobrazovanija i vosprijatija složnych zvukov, Moskva 1966.
[24] Vlivem koartikulace nastává značný přesah spekter sousedních hlásek. Nejvýznamnější jsou tranzienty (změny) formantů následující samohlásky u okluzív (blíže o tom B. Borovičková - V. Maláč - M. Sedláková, o. c. v pozn. 13).
[25] J. Novotná-Hůrková - J. Michálková, Statistické zpracování kombinací konsonantických fonémů (1. etapa), Laboratorní výzkumná zpráva fonetické laboratoře 1971; J. Michálková - J. Novotná-Hůrková, Souhláskové skupiny podle frekvence výskytu (2. etapa), J. Novotná-Hůrková, Sledování základních zákonitostí navazování nejčetnějších souhláskových spojení, Laboratorní výzkumná zpráva fonetické laboratoře 1972.
[26] K zavedení logaritmického zobrazení časových změn v trvání hlásek nás vedou dva důvody: Prvním z nich je různá váha poměru dvou hodnot lišících se více než o 10 %. Např. poměr čísel 80 a 100 je již dost odlišný podle toho, kterou z obou hodnot považujeme za výchozí. Vycházíme-li z hodnoty 80, pak hodnota 100 je o 25 % větší; vycházíme-li naopak z hodnoty 100, pak je hodnota 80 menší jen o 20 %. Čím větší je rozdíl obou porovnávaných hodnot, tím větší je rozdíl obou procentuálních změn. Vyjádříme-li však poměr 80 a 100 v logaritmické míře a použijeme-li jako pracovní jednotku decichron (dC), pak v obou případech je vyjádřen poměr hodnotou 1,0 dC. Název jednotky jsme převzali podle návrhu Gregova a Rossova (A. P. Fraisse - J. Piaget, Experimentaľnaja psichologija, Moskva 1966, s. 289). Jde o využití zákona Weberova-Fechnerova (s. 241—313; K. V. Bardin, Problema porogov čuvstvitel’nosti i psichofizičeskije metody, Moskva 1976, s. 10n.). Změna rovná jednomu dC je změnou percepčně právě postřehnutelnou (cca 20 % původní hodnoty) a dvojnásobek (polovina) je vyjádřen zvětšením (zmenšením) základní hodnoty o 3 dC.
[27] V. Maláč - B. Borovičková, Towards a Secondary Mark of Voicing in Czech, 14. akustická konferencia Akustika reči a vnímanie zvuku, 1. část, Bratislava 1976, 109—113.
Slovo a slovesnost, volume 41 (1980), number 1, pp. 39-48
Previous Vincent Blanár: Lexikálny význam a označovaná skutočnosť v jazykovozemepisnom aspekte
Next Libuše Kroupová: Vztah významu gramatického a lexikálního u předložek
© 2011 – HTML 4.01 – CSS 2.1