
K použití strojů na děrné štítky pro výběr slovních tabulek při zkouškách srozumitelnosti
Blanka Borovičková, Jiřina Novotná
[Discussion]
Об использовании математических машин с перфокартами для выбора словарных таблиц при испытаниях понятности / Emploi des machines à cartes perforées pour le choix des tables de mots utilisées aux essais d’intelligibilité
[*]Dílčí etapou našeho úkolu „Stanovení objektivních kritérií a metod při hodnocení kvality zvuku přenosových zařízení s respektováním fyziologie sluchu“ je určení indexu srozumitelnosti české řeči. Srozumitelnost je totiž základním kritériem pro hodnocení kvality elektroakustického kanálu při přenosu informace prostřednictvím řeči. Elektroakustickým kanálem rozumíme jakýkoli druh spojení mezi ústy mluvčího a uchem posluchače, pokud toto spojení obsahuje elektroakustické měniče (mikrofony, reproduktory apod.) s příslušným vedením.
Srozumitelnost řeči se zjišťuje tak, že se elektroakustickým kanálem přenášejí elementy řeči, a to slabiky, slova nebo věty. Tyto elementy se sestavují do tabulek podle jejich typičnosti pro daný jazyk, především po stránce akustické. V našem případě je tedy nutné, aby každá tabulka obsahovala hláskové kombinace nebo slova pouze takového typu, s jakým se setkáváme v mluveném živém jazyce,[1] aby ve výběru materiálu byl zachován takový poměr i frekvence jejich výskytu, aby zkušební text byl zároveň spolehlivým obrazem spektrálního složení české řeči.[2]
[266]Zkoušky srozumitelnosti se provádějí za různých přenosových podmínek. Je proto nutné mít velký počet zkušebních tabulek (tj. slabik, slov nebo vět), aby se při zkouškách posluchačům zabránilo zapamatovat si sled těchto slabik nebo slov. Při měření se totiž pracuje stále s jednou skupinou posluchačů. Všech zkušebních tabulek nelze ovšem užívat při každém měření v plném rozsahu; je však třeba, aby každá jednotlivá tabulka zachovala uvedenou typičnost jazyka.
Použití strojů na děrné štítky je v některých oborech dnes již zcela běžné, v lingvistice však není u nás dosud obvyklé. Když jsme v r. 1956 začínali uvažovat o organizaci statistiky vhodné pro naši práci, rozhodli jsme se využít i metody strojového zpracování informací. V té době však byly k dispozici jen číselné stroje n. p. Aritmy,[3] kterých jsme pro naši práci nemohli dobře užít. Teprve nově konstruované stroje abecední, rozšiřující svou kapacitu i o informace abecední, umožnily nám využít strojů na děrné štítky při naší práci, a to k excerpování materiálu.
Závažná výhoda excerpce materiálu na děrné štítky záleží v tom, že je podstatně ekonomičtější než dosavadní způsob excerpce. Při excerpci na děrné štítky postupujeme stejně jako při excerpci lístkové, jen děrování je prací navíc. Manuální třídění materiálu je však podle různých hledisek nahrazeno tříděním automatickým, které dosahuje rychlosti několika tisíc štítků za hodinu.[4]
Účelem našeho zpracování materiálu pomocí děrných štítků je zjistit frekvenci slov, slovních tvarů i kmenů a koncovek, typickou pro mluvený jazyk. Při sestavování zkušebního materiálu nevycházíme tedy ze základních podob lexikálních (např. nominativu substantiv, infinitivu sloves) a z gramatických kategorií u nich určovaných (např. nominativu singuláru), nýbrž z jejich podoby v kontextu, tj. všímáme si např. výskytu různých pádů substantiv, osob u sloves apod. Protože nám jde o zvukovou podobu výpovědi, je třeba, aby náš materiál byl co možná životný a průkazný pro skutečné poměry v daném jazyce.
První pokus se zpracováním našeho materiálu pomocí děrných štítků nám potvrdil správnost naší pracovní metody, ověřil technické i jiné možnosti a objasnil nám podrobněji problematiku práce s děrnými štítky. Pro tento pokus jsme excerpovali na děrné štítky 100 slov z Fučíkovy Reportáže psané na oprátce. Teprve další etapa práce nám ovšem bude moci odpovědět na otázku, která zůstává zatím otevřená, tj. v jakém poměru bude nutno zařadit do tabulek slovní srozumitelnosti slova nestejného slabičného rozsahu.
Důležitou pomůckou, která nám usnadňuje práci, je frekvenční slovník „Frekvence slov, slovních druhů a tvarů v českém jazyce“ (v tisku), sestavený J. Jelínkem, J. V. Bečkou a M. Těšitelovou. Tento slovník, který shromažďuje rozsáhlý, důkladně zpracovaný materiál (1,623.527 slov), umožňuje nám především přesně stanovit na základě zásad statistického výběru (jak je dále uvedeno podrobněji) potřebný rozsah materiálu pro naše účely. Přestože frekvenční slovník je založen na úplné excerpci 75 děl, nemohli jsme použít přímo materiálu, [267]který nám poskytuje. Neexcerpujeme totiž díla úplně, nýbrž vybíráme z nich jen určité věty podle zásad statistického výběru. Rovněž údaje, které potřebujeme, jsou jiného druhu, než jsou ty, které poskytuje frekvenční slovník. Záleží nám nejen na gramatických kategoriích, ale i na jejich zvukové podobě. To znamená, že nás zajímají hláskové kombinace slabik a jejich umístění v slově. Slovo jakožto nejmenší přemístitelná jednotka věty je pro nás určitým sledem fonémů, které vytvářejí jeho zvukovou stránku. Přitom je slovo buď nedílné, jednoslabičné, anebo se skládá z více slabik. Všímáme si také stavby slova, předpon, slovních základů, přípon atd.; jsou proto i na děrném štítku vyznačeny. A právě v této dílčí pracovní etapě soustřeďujeme pozornost na fonologické uplatnění zvukové stránky jazykového materiálu.
I. Statistická šetření. Pro zjišťování frekvence slov, slovních druhů, tvarů, koncovek apod. používáme statistického šetření.
Statistické šetření může být jednak úplné, to znamená, že zkoumáme každou jednotku daného základního souboru, jednak výběrové, kdy studujeme jenom některé jednotky. Úplné šetření má tu výhodu, že výsledné údaje jsou zjištěny zcela nebo téměř zcela přesně; výhodou výběrových šetření je úspora času a nákladů, ovšem za cenu snížení přesnosti získaných údajů. Přesnost závisí podstatně na způsobu, jímž byl výběr pořízen. Výběr je v podstatě dvojí: úsudkový, který provádí zkušený znalec podle svého uvážení, nebo na základě pravděpodobnosti, pravděpodobnostní. Úsudkový výběr sice může dát dobré výsledky, ale zatím neumíme říci, proč tomu tak je, a neumíme předvídat, kdy se tak stane. V některých případech je přesto vhodný, např. tam, kde celý rozsáhlý soubor musí být zastoupen malým počtem reprezentantů. Česká próza bude např. lépe a výstižněji reprezentována výběrem několika děl určeným znalcem české literatury než namátkou vybranými svazky z celkového souboru všech českých knih. Tímto způsobem opatřujeme si materiál i pro naši práci.
Základem pravděpodobnostního výběru je náhodný výběr jednotek, řídící se požadavkem, aby každá jednotka základního souboru měla stejnou pravděpodobnost, že se dostane do výběru. Existují různé druhy výběrů podle toho, vybíráme-li jednotky přímo z celého souboru nebo rozdělíme-li soubor nejprve do skupin (tzv. oblastí) a vlastní jednotky vybíráme pak v každé oblasti zvlášť, tzv. oblastní výběr; takto vybrané jednotky se vracejí zpět do souboru, takže jedna jednotka může být vybrána několikráte (výběr s opakováním), nebo každá jednotka může být vybrána pouze jednou (výběr bez opakování). Dále rozlišujeme výběr jednostupňový, kdy ihned přímo vybíráme zkoumané jednotky, nebo vícestupňový, kdy vybíráme nejprve větší primární jednotky a z nich teprve vlastní výběrové jednotky (sekundární).
Pro výběr vlastních jednotek — v našem případě slov — používáme výběru oblastního. Z každé stránky vybrané knihy jsme tedy náhodným výběrem dostali jednu větu, z níž jsme vyexcerpovali všechna slova.
Použití pravděpodobnostního výběru umožňuje využít teorie pravděpodobnosti k stanovení přesnosti údajů získaných šetřením. Ukážeme si to na jednoduchém příkladě. Pro zjednodušení budeme předpokládat, že zjišťujeme frekvenci substantiv v určité knize. Předmětem šetření bude tedy základní soubor všech slov v dané knize, jednotkou šetření bude slovo; zkoumaným znakem bude pak příslušnost k druhu „substantivum“. Značí-li N počet všech slov v knize, N1 hledaný počet substantiv, n počet slov ve výběru a n1 počet substantiv ve výběru, potom pro N1 dostaneme odhad
![]()
Jeho přesnost si vyjádříme pomocí tzv. intervalu spolehlivosti: s pravděpodobností 95 % bude hledané číslo N1 ležet v intervalu
![]()
Tento vzorec pro přesnost odhadu X platí, pokud je n1 (n-n1) větší než 30; v opačném případě je třeba použít jiných metod.[5]
[268]II. Strojové zpracování informací z oboru jazykovědy. Je samozřejmé, že tak složitou skutečnost, jakou je gramatická stavba jazyka, nemůžeme formálně zachytit ve vší její úplnosti. Z tohoto předpokladu tedy vycházíme už při excerpci a třídění našeho materiálu. Statistické zpracování jazykového materiálu pomocí děrných štítků je zatím pouhým pokusem, který má své hranice. Omezili jsme se proto jenom na nejdůležitější gramatické kategorie, které mají pro přenos výpovědi stěžejní význam. Při určování těchto kategorií používáme jako normativních příruček Příručního slovníku jazyka českého, Slovníku spisovného jazyka českého (zatím jen do hesla „mžurka“) a Stručné mluvnice české od Havránka a Jedličky (vydání z roku 1959).
Místo s běžnými excerpčními lístky pracujeme přímo se standardními návrhovými štítky, z nichž pořizujeme štítky sdružené.[6]
Horní i dolní polovina každého štítku je pomyslně rozdělena na dvě stejné polovice, takže vznikají čtyři pole:
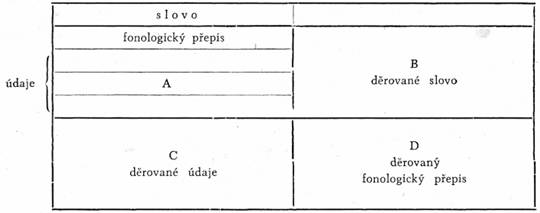
Na poli A vyznačujeme kromě vlastního slova a údaje o jeho druhu ještě údaje o gramatických kategoriích, např. u jmen rod, číslo, pád, vzor; u přídavných jmen rozlišujeme i přídavná jména složená, tvrdá a měkká, jmenná a přivlastňovací, dále zájmena osobní, zvratná, přivlastňovací, ukazovací, tázací, vztažná, záporná a neurčitá. U sloves např. jsou to údaje o osobě, čísle, času, způsobu, třídě a vidu, zvláštní údaj je pro sloveso pomocné, sponové a zvratné. Všechny tyto údaje zaznamenáváme podle předem přesně určeného pořadí. Kromě toho ukládáme na štítky ještě informace týkající se slovotvorných formantů a fonologický přepis slova. Do pole A se zásadně žádný záznam neděruje, takže původní záznam zůstává za všech okolností nedotčený. Naproti tomu pole B, C a D jsou určena pro děrování podle předem pevně stanoveného programu — projektu. Do pole B se děruje slovo, do pole D fonologický přepis a do pole C údaje o klíči[7] a identifikační znaky.
Sdružený štítek umožňuje, aby se záznamy v jednotlivých polích prováděly i v časově odlišných obdobích. Odborného jazykovědného a fonetického zpracování je třeba jen při záznamech v poli A, záznamy v ostatních polích provádějí pracovnice, zacvičené do obsluhy strojů na děrné štítky, podle projektu nebo instrukcí. Ke každému údaji, který je excerptorem vypsán, je nutno připsat číselné vyjádření podle klíče. Po skončení této práce se vyděrují do štítku [269]příslušné informace. Děruje se slovo, jeho fonologický přepis a klíče. Vyděrované údaje jsou přezkoušeny, popřípadě opraveny.
Vzhledem k tomu, že užíváme sdružených štítků, na nichž jsou zachyceny všechny důležité původní záznamy, uvažujeme o tom, že z naděrovaných štítků celého našeho slovního materiálu pořídíme automaticky na opakovači tzv. štítky oběžné se všemi vlastnostmi základní kartotéky. Opakovač pracuje rychlostí několika tisíc štítků za hodinu. Pracně pořízený dokumentární materiál by tak zůstal zachován provždy.
Třídění se dá provést podle všech děrovaných sloupců, ať již obsahují informace číselné nebo abecední, od začátků nebo od konců slov, tedy dvojím způsobem. Jednak je možno zpracovat všechny děrné štítky (celý náš slovní materiál), jednak můžeme vhodným vytříděním pořídit součtové štítky pro slova, která se opakují (např. běžné spojky apod.), a potom pracovat už pouze s těmito štítky. (Součtový štítek zastupuje skupinu štítků se stejnými údaji; proti prvotním štítkům má navíc údaj o frekvenci excerpovaného hesla.)
Pro každé slovo je určen jeden štítek. Jen předložky jsou uloženy na štítku společně se slovem, ke kterému se vztahují; pro ně vyhrazujeme na štítku určitý počet prvních sloupců.
Slovní materiál zachycený na štítcích můžeme tedy automatickým tříděním rozložit na slovní druhy, zjistit celkový počet jednotlivých slovních druhů, ty pak roztřídit podle gramatických kategorií, zjistit počet stejně dlouhých slov, souhláskové skupiny na počátku, uprostřed a na konci slova, a to u slova napsaného ortograficky stejně jako u fonologického přepisu, vytřídit slova podle předpon, slovních základů a přípon.
Všechna třídicí hlediska můžeme libovolně kombinovat. U vytříděných štítků automaticky zjistíme jejich frekvenci a kromě toho nám stroj vytiskne příslušné seznamy slov podle uvedených hledisek.
Zjištěním frekvence např. morfologických prvků získáváme statistický přehled prostředků českého skloňování a časování, který bude mít podle našeho názoru význam nejen pro naši práci, ale může sloužit jako pomocný materiál i pro jiná odvětví lingvistická, jako je mluvnická analýza jazyka, typologie jazyků apod. Statistické zkoumání vztahu rodu substantiv a koncovek a srovnání získaných výsledků s poměry v jiných jazycích prokazuje z hlediska typologického příbuznost různých jazyků. Frekvence morfologických prostředků ukazuje pak z hlediska typologie důležité vlastnosti češtiny, jako např. synonymii koncovek apod. Právě tak přispěje k vyjasnění problému homonymie koncovek.
Zaznamenáním fonologického přepisu textu ukládáme na štítek informace o funkčním uplatnění akustické podoby hlásek, resp. jejich kombinací v češtině. (Při fonetickém přepisování textu, kdy se snažíme co nejpřesněji zachytit zvukovou podobu českého jazyka, vycházíme z normativní příručky Výslovnost spisovné češtiny, zpracované B. Hálou na základě výsledků jednání ortoepické komise ÚJČ ČSAV.)
Nadto si všímáme také syntaktických dvojic, abychom zhruba zjistili funkci slova ve větě. Tříděním materiálu podle různých hledisek získáváme možnost objasnit si do jisté míry i vzájemné vztahy gramatických tvarů podle jejich funkce syntaktické a sémantické. Zjištění frekvence slovních typů nejdůležitějších pro českou slovní zásobu, dále přehled slabikové a slovní struktury charakteristické pro češtinu a konečně i zjištěná frekvence hlásek objasní rovněž některé problémy entropie češtiny. Provedení podrobné jazykovědné analýzy, potřebné při ukládání jazykového materiálu na děrné štítky, pomůže do značné míry i při sestavování instrukční sítě pro vstup a výstup samočinných počítačů. Pokud jde o statistiku kmenů a koncovek, získanou pomocí děrných štítků, lze říci, že nám do jisté míry usnadní stanovení hranice mezi kmenem a koncovkou, což přispívá k vyřešení jednoho z nejdůležitějších problémů strojové analýzy. Zjištění o homonymii koncovek a homonymii kmenů lze použít při rozlišení homonymie kmenů slovesných a jmenných, protože náš materiál je možno kdykoli roztřídit nejen podle kmenů a koncovek, ale zároveň i podle jmen a sloves.
[270]Závěrem můžeme říci, že výběr slov k sestavení zkušebních tabulek pro měření srozumitelnosti české řeči při přenosu a jejich zpracování pomocí strojů na děrné štítky se nám plně osvědčuje. Velkou důležitost má pro nás možnost třídit materiál z různých hledisek. Při sestavování slov do tabulek jsme se setkali např. s názory, že slovní materiál pro zkoušky srozumitelnosti by měl sestávat ze slov převážně jednoslabičných; tento názor je častý i u zahraničních badatelů a jistě oprávněný pro některé jazyky. Čeština však není v zásadě jazykem monosylabickým, ba právě naopak. A právě vzhledem k této povaze češtiny je nutné, aby v slovních tabulkách jazykové srozumitelnosti byla zastoupena slova podle počtu slabik, a to v takovém poměru, jaký zjišťuje statistický průzkum textů pomocí děrných štítků. Při této příležitosti jsme si znovu ověřili známou skutečnost, že jednoslabičná slova tvoří v češtině menšinu, a proto zařazujeme do tabulek i slova víceslabičná, morfematicky více rozvitá.
Statistické zpracování hláskových kombinací charakteristických pro češtinu nám osvětluje také skutečnost, kterou jsme zjistili při zkouškách srozumitelnosti, že totiž existuje podstatný rozdíl mezi různými jazyky v celkovém procentu srozumitelnosti (správně slyšených slov) při stejných přenosových podmínkách.
Použití metody zpracování informací z oblasti lingvistiky pomocí děrných štítků poskytuje dále ještě možnost dodatečně rozšiřovat nebo zužovat kritéria původně stanovená a tím také zpřesňovat zpracování a prohlubovat jeho kapacitu. Tyto úpravy, prováděné i během zpracovávání děrných štítků, umožňují využít základního kmenového fondu štítků i podle zcela nových hledisek. Zároveň lze provádět i různé rozbory (např. rozbor starších i novějších literárních děl téhož autora apod.).
Pokud jde o náš materiál, počítáme v budoucnosti s prohloubením a rozšířením jazykovědné analýzy, především s vypracováním podrobné statistiky z oblasti morfologie, což přispěje značnou měrou k řešení problematiky akustické samočinné analýzy a syntézy řeči, která je nutným předpokladem pro řešení naléhavých a aktuálních úkolů z oboru mechanizace a automatizace. V tomto případě jde o hlasové ovládání strojů a v budoucnosti o mluvený vstup a výstup samočinných počítačů.
[*] Za spolupráce V. Maláče z Výzkumného ústavu n. p. Tesla, J. Zelinky z n. p. Aritma a F. Zítka z Matematického ústavu ČSAV.
[1] Srov. J. Vachek, K jazykovědné problematice zkoušek slabikové srozumitelnosti, SaS 17, 1956, 40—47. Odpověď B. Borovičkové, tamtéž, 110—114. J. Vachek, Odpověď na repliku dr. B. Borovičkové, tamtéž, 178—181. M. Romportl, K diskusi o zkouškách slabikové srozumitelnosti, SaS 18, 1957, 62—63.
[2] Spektrální složení řeči je tvořeno dvěma základními složkami: 1. formantovým složením hlásek, resp. hláskových kombinací, 2. frekvencí hlásek, resp. jejich kombinacemi. Formantem rozumíme tu část akustického hláskového spektra, která se uplatňuje při rozlišování hlásek. Nejde nám tedy o pouhou akustickou podobu hlásek a jejich kombinací, ale zajímá nás především funkční uplatnění této akustické podoby. Rozhodující jsou ty části spektra, které vnímáme při rozlišování hlásek; např. znělost, která je za určitých podmínek přenesena elektroakustickým kanálem, bude zaznamenána jen těmi posluchači, v jejichž jazyce má svou vlastní funkci.
[3] Děrovače číselné jsou schopny pracovat jen s čísly, abecední pracují s kódem pro čísla i s kódem pro písmena, a mohou tedy zaznamenávat slova, popř. i text.
[4] U číselných třídiček je to asi 20.000 štítků za hodinu, jestliže třídíme jedním sloupcem, to znamená, že hledisko je vyjádřeno jednomístným číslem (0—9); u elektronického třídiče je třídění, pokud jde o číselné údaje, asi třikrát rychlejší, stroj tedy zpracuje asi 60.000 štítků. To odpovídá stejnému počtu slov za hodinu. Jestliže jde o třídění podle abecedních znaků, je rychlost asi poloviční. Třídičkou musí štítky projít tolikrát, kolika sloupců je užito jako klíče pro hledaný jev.
[5] J. Hájek, Teorie výběrových šetření (skripta pro ČVUT), Praha 1955.
[6] Na sdružený štítek s upraveným předtiskem se nejprve manuálně vypíše excerpční záznam. Údaje takto vyznačené se potom do téhož štítku děrují.
[7] Klíčem rozumíme číselnou soustavu, užívanou v našem případě pro vyjádření jisté řady pojmů.
Slovo a slovesnost, volume 21 (1960), number 4, pp. 265-270
Previous Jaroslav Stuchlík: K fenomenologii patologických jazykových novotvarů
Next Jitka Štindlová: Retrográdní slovníky
© 2011 – HTML 4.01 – CSS 2.1