
Zjišťování relevantních oblastí hlásek v češtině
Blanka Borovičková
[Articles]
Установление дифференциальных областей фонем чешского языка / Recherche des domaines relevantes des sons en tchèque
Pro vnímání akustických signálů prvků řeči jsou relevantní jak časové změny jejich frekvenčních spekter (např. změna trvání), tak změny jejich frekvenčních oblastí v diskrétních okamžicích signálů po sobě následujících. K sledování percepční závažnosti frekvenčních oblastí jsem použila výsledků rozsáhlých poslechových testů určených primárně k stanovení indexu poznatelnosti české řeči.[1] Poslechový materiál v rozsahu zhruba půl miliónu zapsaných slabik jsem zpracovala z hlediska akustické fonetiky.
Při stanovování indexu poznatelnosti české řeči nás zajímalo pouze procento správně slyšených a zapsaných slabik v jistých fyzikálně přesně volitelných podmínkách. Záměrně proměnným faktorem těchto podmínek při měření indexu byla šířka frekvenčního pásma přenosového kanálu. Celý frekvenční rozsah přenosu byl postupně zužován dolními nebo horními propustmi a při každém stupni zúžení frekvenčního pásma byla čtena stočlenná skupina slabik způsobem popsaným v publikacích uvedených v pozn. 1. Reprodukovaný akustický signál hodnotila čtrnáctičlenná poslechová skupina. Zápisy hodnocení slyšených slabik byly pak opravovány a z výsledků oprav bylo stanoveno procento poznatelnosti slabik, tj. procento slabik správně slyšených. Nehodnotili jsme pouze „správně — špatně“, ale i způsob nesprávného slyšení, tj. způsob záměn jednotlivých hlásek ve slabikách.
Podrobnější způsob hodnocení výsledků poslechových testů nám pak umožnil použít základního materiálu k dalšímu zpracování. Smyslem mé práce bylo zjistit relevantní oblasti spektrálních obrazů hlásek na frekvenční ose, tj. stanovit, které frekvenční oblasti mají nejvyšší závažnost při identifikaci hlásek a jejich kombinací subjektem. Všímala jsem si zde pouze frekvenčních složek spektra bez ohledu na jejich časový průběh.
Pro naše účely jsme materiál poslechových testů poznatelnosti upravili nejprve seskupováním zápisu slabik do tabulek tak, že na jedné tabulce byly pro jednu slabiku zapsány všechny varianty slyšené posluchači při testech ve všech frekvenčních pásmech přenosu signálu, tj. při všech způsobech frekvenčního omezení kanálu. Tento způsob měl ovšem velkou nevýhodu v tom, že i když jsme mohli dobře sledovat změny v poznatelnosti jedné slabiky v průběhu všech frekvenčních pásem, nemohli jsme sledovat změny v poznatelnosti různých hlásek a jejich kombinací v pásmu jediném. Hledali jsme způsob zpracování, který by nám umožnil rychlou orientaci v materiálu z různých hledisek. S úspěchem jsme zde použili metod mechanizace a automatizace administrativních prací pomocí děrných štítků. Tyto metody jsme aplikovali na naše problémy.
[27]Nebudu zde uvádět všechny podrobnosti projektu a jeho realizace, ale omezím se pouze na několik základních poznámek pro ilustraci této metody.
Původní materiál v rozsahu půl miliónu slabik byl převeden na děrné štítky ze skupinových tabulek. Tím bylo získáno 40 tisíc štítků pro další zpracování. Převod materiálu ze skupinových tabulek na štítky jsme provedli po vypracování projektu třídění a tabelování. Na horní prázdný okraj děrných štítků (nultý řádek) byly zapsány potřebné informace. Zápis byl proveden na pravé polovině nultého řádku tak, že bylo zapsáno postupně odleva doprava evidenční číslo štítku, číslo frekvenčního pásma, zapsaná slabika, číslo udávající celkový počet zápisů dané slabiky, počet hlásek slabiky, počet správných zápisů slabiky, počet špatných zápisů slabiky stejného druhu a konečně změna v počtu hlásek při špatně zapsaných slabikách, určující též posunutí pořadí zapsaných hlásek proti hláskám čteným. Po provedení této operace byly záznamy zakódovány, tj. převedeny do numerického kódu. Takto zakódovaný zápis do levé poloviny nultého řádku na horní polovině štítku byl instrukcí, podle níž v početní stanici byly potřebné údaje naděrovány do štítku. V zásadě bylo použito pouze horní poloviny štítku, abychom mohli další operace se základními údaji provádět na jeho polovině dolní. Převedení hlásek do numerického kódu jsme museli užít proto, že existující abecední kódy používané v administrativních pracích nejsou vhodné pro jakékoli jazykové analýzy, ani pro naše účely: nerozlišují totiž všechny české fonémy.
Z tohoto základního štítkového materiálu je možno provádět operace umožňující řadu pohledů. V první fázi jsem se soustředila na stanovení relevantního pásma jednotlivých hláskových variant. Určení tohoto pásma jsem provedla v zásadě dvojím způsobem. První způsob (dále označený I) je obdobou stanovení indexu poznatelnosti a záleží v tom, že jsem vynášela procento poznatelnosti jednotlivých hláskových variant v závislosti na mezné frekvenci dolní a horní propusti.
Tím jsem získala pro každou hlásku dvojici křivek. Tam, kde tyto křivky protínají přímku procházející bodem odpovídajícím 95 % poznatelnosti, získáme krajní body vymezující frekvenční pásmo nejvyšší váhy při identifikaci hlásky. Abych získala tyto informace ze základního materiálu, musela jsem dvojím způsobem seskupit základní soubor štítků a provést poměrně složitou operaci, která k počtu nesprávně zapsaných slabik přičtla pro jednotlivé případy ještě ty, v nichž sledovaná hlásková varianta byla zapsána správně, i když některá jiná část slabiky byla nesprávná a celá slabika tím spadala zřejmě do oblasti špatně hodnocených slabik. Počet těchto částečně správných slabik byl přičten k počtu slabik zcela správných a pak bylo teprve možno provést výpočet procenta poznatelnosti pro danou hláskovou variantu. Celý tento postup byl prováděn většinou automaticky na strojích. Při hodnocení hlásek jsem v první etapě nebrala v úvahu vliv sousedství ostatních hlásek, ale rozlišovala jsem pouze mezi hláskovým postavením na začátku, uprostřed a na konci slabiky. Tímto seskupováním jsem získala pomocí dvojích součtových štítků konečný soubor asi tisíce štítků, který měl tři základní skupiny, hodnotící hlásky podle jejich postavení v slabice. V konečné sestavě[2] jsou pak vždy pro jednu hláskovou variantu sestaveny hodnoty procenta poznatelnosti hlásky v závislosti na mezné frekvenci dolní a horní propusti.
Druhý způsob (dále označován II) sloužící k stanovení relevantního frekvenčního pásma jednotlivých hláskových variant byl získán z výsledků poslechových testů, při nichž jsme přenosový kanál upravovali pásmovými propustmi. Šířka propusti byla vždy zhruba v rozsahu poloviny oktávy. Výsledky slabikové poznatelnosti byly zpracovány pomocí děrných štítků jako v případě I. Výsledný graf má pouze jednu křivku, udávající procento poznatelnosti jednotlivých hláskových variant v závislosti na střední frekvenci pásmové propusti. V těchto grafech jsou [28]oblasti maximálního příspěvku k poznatelnosti vyznačeny místy maximálních hodnot procenta poznatelnosti.
Jako příklad uvádím samohlásku a ve středním postavení, charakterizovanou křivkami na obr. 1 a 2. Je to jeden z častých případů, kde hodnocení podle způsobu I na první pohled nevyhovuje. Nelze totiž stanovit frekvenční pásmo vyznačené body křivek poznatelnosti o hodnotách 95 %. Obě frekvence se vzájemně překrývají, takže docházíme k absurdnímu závěru, že pro přenos samohlásky a
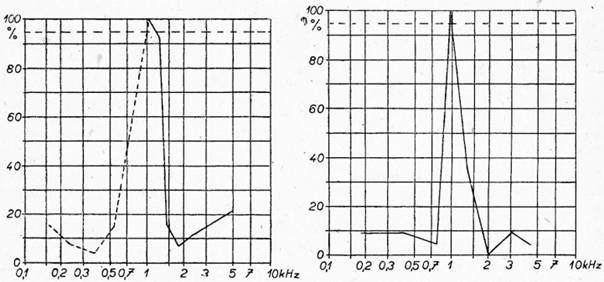
Obr. 1 — křivky I — samohláska a Obr. 2 — křivka II — samohláska a
nepotřebujeme žádné frekvenční pásmo. Matematicky lze vyjádřit tento jev jako výskyt negativního frekvenčního pásma. Abychom uvedli tento absurdní závěr na pravou míru, musíme uvážit, jakým způsobem byly hodnoty na obr. 1 získány.
Obě křivky byly měřeny postupně za sebou, takže stoprocentní poznatelnost hlásky a byla až do mezné frekvence horní propusti asi 1 kHz a 95 % poznatelnosti až do frekvence asi 1,15 kHz. (Tuto hodnotu vytíná na přímce 95 % poznatelnosti křivka získaná postupným omezováním frekvenčního pásma zdola horními propustmi, vyznačená na obrázku plnou čarou.) Křivka poznatelnosti dolních propustí vytíná hodnotu 95 % poznatelnosti na frekvenci asi 1 kHz. Je tedy negativní šířka pásma asi 150 Hz.
Ve většině případů je formant samohlásky tvořen dvěma až třemi harmonickými frekvencemi základní frekvence hlasu, jejichž amplituda se zhruba liší o 5 až 10 dB, takže můžeme jednotlivé složky formantu považovat zhruba za rovnocenné. Jinak řečeno, formant není tvořen jediným diskrétním bodem na frekvenční ose, ale vytíná frekvenční pásmo 100—400 Hz podle výšky základního tónu hlasu a podle počtu harmonických frekvencí formantové oblasti.
Pro identifikaci samohlásky poslechem předpokládáme, že druhý formant má největší závažnost a že v některých hláskových kombinacích postačí k poznání samohlásky (obr. 2). Pro identifikování formantu pak stačí jediná frekvence z celé oblasti pro určení jeho umístění na frekvenční ose. Za těchto předpokladů musíme pro náš případ samohlásky a opravit mezné frekvence v obou případech minimálně o 150 Hz (pro případ pouhých dvou harmonických frekvencí na formant) a negativní šířka pásma 150 Hz se změní na pozitivní šířku 150 Hz v pásmu [29]asi od 1 kHz do 1, 15 kHz. Kontrolujeme-li výsledek hodnocení grafů z obr. 1 křivkou z obr. 2, docházíme k naprosté shodě: pro identifikaci samohlásky a v interkonsonantickém postavení je relevantní a postačující frekvenční oblast druhého formantu, která je pro mluvčího č. 1 v oblasti 1—1,15 kHz.
Jako druhý příklad uvádíme hodnocení samohlásky i na obr. 3 a 4. Šířka oblasti maximální poznatelnosti samohlásky je větší než v prvním případě a křivka vedle toho ukazuje ještě druhé maximum procenta poznatelnosti. Toto druhé
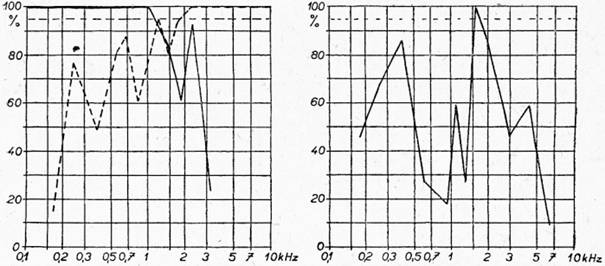
Obr. 3 — křivky I — samohláska i Obr. 4 — křivka II — samohláska i
maximum odpovídá frekvenční oblasti prvního formantu samohlásky i. Značná šířka relevantního frekvenčního pásma druhého formantu je způsobena tím, že při měření poznatelnosti byly čteny pro různé frekvenční podmínky slabiky obecně různé. Odlišné hláskové sousedství samohlásky způsobuje frekvenční pohyb samohláskových formantů, zejména formantu F2.
Překrytí křivek typu I, tj. negativní frekvenční pásmo, na obr. 3 je v rozmezí 700 Hz — 2 kHz. Je to maximum překrytí mezi všemi samohláskami, které je způsobeno největší vzdáleností frekvencí formantů F2—F1. Závažnost formantu F1 je téměř rovnocenná se závažností formantu F2, jak soudíme z vysokých a vzájemně rovných hodnot procenta poznatelnosti v obr. 3 a 4. Hodnota procenta poznatelnosti pro oba formanty F2 a F1 je 100 %. Z toho opět vyplývá, že pro identifikaci samohlásky i v interkonsonantickém postavení stačí jediný formant, buď F2 nebo F1. Jinými slovy, že každý z těchto formantů je užitečně redundantní. Ale i zde není porušena nadřazenost vyšší závažnosti formantu F2 nad formantem F1, což se projevuje větší šířkou oblasti maximální poznatelnosti samohlásky formantu F2 proti formantu F1 (obr. 4).
Když jsem uvedeným způsobem zhodnotila všechny samohlásky, došla jsem k závěru, že pro jejich percepci je nejzávažnější druhý formant F2. Druhé místo v pořadí závažnosti má formant první F1 a na třetím místě je formant F3. Toto pořadí neplatí u samohlásky u, kde třetí formant vykazuje ve výsledcích vyšší závažnost než první. Pokles závažnosti prvního formantu a vzestup třetího se jeví již u samohláskových variant o. Jinak lze říci, že s výjimkou u platí pořadí percepční [30]závažnosti jednotlivých formantů stejně, jak byly určeny již při fyzikálním hodnocení samohlásek.[3]
Závěrem bych ráda zdůraznila, že poslechové testy jsou v akustické fonetice pouze částí výzkumné metody. Neoddělitelnou částí tohoto výzkumu je získání fyzikálních parametrů zkoumaných hlásek a jejich kombinací nejlépe z trojrozměrných spektrogramů typu „visible speech“. Teprve vzájemným srovnáním výsledků obou metod jsme s to odpovědně určit apercepční hodnoty řeči.
R é s u m é
FESTSTELLUNG DER RELEVANTEN LAUTGEBIETE IM TSCHECHISCHEN
Der Artikel beschreibt zwei Methoden auditiver Teste und ihre Auswertung zum Zwecke der Feststellung der Wichtigkeit der ersten drei Formanten bei den tschechischen Vokalen. Bei der ersten Methode wird das Frequenzband der übertragenen Silben abwechselnd mittels Tief- oder Hochpässe, bei der zweiten Methode mittels Filter, deren Breite eine halbe Oktave beträgt, eingeschränkt. Die statistische Verarbeitung der Angaben wurde mit Hilfe von Lochkartenmaschinen durchgeführt. An einigen Beispielen werden scheinbare, bei der ersten Methode vorkommende Inkongruenzen erklärt. Abschliessend wird die Rangordnung der Wichtigkeit der Formanten für die Sprachperzeption angeführt, und zwar F2, F1, F3 für alle Vokale ausgenommen u, für welches die Rangordnung F2, F3, F1 gilt.
[1] В. Вorovičková, V. Maláč, Fonetická problematika měření indexu poznatelnosti, SaS 22, 1961, 41—48; K problematice subjektivního hodnocení přenosových cest, Slaboproudý obzor 23, 1962, 374—377, Index poznatelnosti české řeči, tamtéž, s. 625—630.
[2] Sestava je zápis výsledných hodnot provedený tabelátorem děrnoštítkového stroje.
[3] B. Borovičková, Percepční identifikace samohláskových pozičních a stylistických variant, SaS 24, 1963, 151—156.
K percepčně identifikačním testům patří i poslech akustického signálu deformovaného v jeho třetí dimenzi, intenzitě. Výsledky těchto testů nejsou ještě úplné, a proto je v této práci zatím neuvádíme, podobně jako výsledky určení percepčně identifikační závažnosti souhlásek. Dokončení tohoto výzkumu si vyžádá provedení dalších rozsáhlých poslechových testů a jejich zhodnocení.
Slovo a slovesnost, volume 25 (1964), number 1, pp. 26-30
Previous Jaromír Bělič: Celonárodní slovní zásoba ne plně spisovná a nespisovná
Next Karel Petráček: Lingvistická charakteristika semitského kořene ve světle nových metod
© 2011 – HTML 4.01 – CSS 2.1