
Kombinatorické vlastnosti soustavy českých grafémů
Lubomír Doležel, Jan Průcha
[Articles]
Комбинаторные свойства системы чешских графем / Les qualités combinatoriques du système des graphèmes tchèques
Shrnutí. Tato práce je příspěvkem ke kvantitativnímu popisu grafematické soustavy spisovné češtiny. Zjišťuje se závislost mezi: a) relativní četností grafémů (xi) a jejich valencí (vi) (koeficient korelace rxv = 0,6); b) relativní četností grafémů a entropií (Hi) jejich valenčního pole (koeficient korelace rxH = 0,5). Hodnoty korelace jsou stanoveny pro abecedu jako celek a také zvlášť pro její třídy (samohlásky krátké, samohlásky dlouhé, souhlásky). Na základě získaných výsledků se dochází k závěru, že kombinatorní schopnosti grafému (nazývané v dosavadní literatuře také „funkční zatížení“) závisí ve spisovné češtině podstatně na četnosti grafému. Potvrdí-li se tato zjištění také analýzou jiných jazyků, bude možno tvrdit, že tím statistická lingvistika odhalila základní zákon kombinatoriky grafémů (a možná jazykových prvků vůbec).
[167]1. Úvod. Kombinatorní jevy v přirozeném jazyce upoutávaly často pozornost lingvistů. Zvláště od vzniku fonologie věnovali se mnozí badatelé popisu kombinatorních pravidel ovládajících vytváření posloupností fonémů. V dosti početných jejich pracích šlo o vystižení systémových vztahů fonémů a fonémových skupin, tedy o rozbor kvalitativně strukturní. V rámci tohoto pojetí se dospělo až k formulaci obecného kalkulu pro popis fonémů a jejich kombinatorních vztahů v jazykových systémech. Máme tu na mysli práci Hararyho a Papera,[1] v níž se předkládá popis distribuce fonémů japonštiny v termínech teorie tříd. Glosematický přístup začlenil nadto do zkoumání kombinatoriky jazyka i analýzu náhodnosti výskytu či nevýskytu jazykových prvků a jejich spojení.[2]
I přes značný počet prací věnovaných rozboru kombinatorních vztahů ve fonologickém systému jazyka je pojetí v nich uplatňované, pojetí kvalitativně strukturní, jednostranné a vyžaduje, aby bylo spojeno s rozborem „funkčního zatížení“ jazykových prostředků a jejich skupin, tedy s pojetím kvantitativně strukturním. To již před desetiletími zdůrazňoval V. Mathesius[3] ve svých metodologicky závažných studiích o českém lexiku. Mathesius zkoumal, i když na statisticky značně omezeném souboru a především pro účely lingvistické komparatistiky, funkční zatížení fonémů a jejich skupin v dvoufonémových až čtyřfonémových slovech češtiny a němčiny. Na jeho práci navázal později J. Vachek[4] analýzou skupin fonémů v rozsáhlejším již souboru pětifonémových českých slov. Konkrétní výsledky těchto i některých dalších prací, zvláště B. Trnky a J. Krámského,[5] zde nehodláme shrnovat a hodnotit, avšak chceme navázat na jejich zaměření, totiž kvantitativně strukturní přístup.
Kvalitativně strukturní analýza popisuje kombinatorní vztahy mezi prvky jazykového systému, strukturní podmínky výskytu prvků a jejich skupin, popř. i rozbor typů skupin. Taková analýza vychází jen z registrace protikladu „výskyt — nevýskyt“, bez zřetele k počtu výskytů. Pro kvantitativně strukturní analýzu je však právě počet výskytů vyjádřený v relativní četnosti nebo pravděpodobnosti základním údajem, z něhož je možno čerpat bohatou informaci o kvantitativní stránce jazyka. Tím je na jedné straně umožněno opřít tuto analýzu o metody moderní matematické statistiky, na druhé straně lze z jejích výsledků budovat popis kvantitativní struktury jazyka a výklad jeho funkčních vlastností.
Na grafematické úrovni prováděli analýzu tohoto druhu nejnověji (ovšem pro speciální účely strojové lingvistiky) K. Korvasová a B. Palek.[6] Zkoumali výskyt grafémů v různých pozicích kmenů slov elektrotechnického slovníku a zjišťovali korelaci mezi délkou kmenů a entropií grafémů v různých pozicích. Těžištěm druhé jejich práce[7] je zjištění četností digramových skupin písmen a pravděpodobností [168]různých typů následnosti samohlásek a souhlásek v těchto skupinách. Cílem autorů je využít zjištěných hodnot pro vytvoření optimálního kódu pro zakódování českých textů při strojovém překladu. Jejich výsledky jsou proto omezeny jak tematickým výběrem materiálu (elektrotechnický slovník) a jeho rozsahem (88 658 písmen), tak i speciální úpravou materiálu (zkoumají se „kmeny“, nikoli celá slova, což ovlivňuje hodnoty četností grafémů a digramových skupin).
V této práci se pokoušíme, navazujíce na uvedené práce pražské školy, prozkoumat některé základní kombinatorické vlastnosti soustavy českých grafémů. Máme dnes k dispozici spolehlivější údaje o relativních četnostech grafémů a jejich digramových skupin (digrafů), které jsou získány z různých textů současné psané češtiny. Tyto hodnoty jsou publikovány v studii L. Doležela;[8] vycházejí z nich všechny výpočty obsažené v naší práci. V citované studii (s. 166—167) jsou rovněž podrobnější informace o výběru materiálu a stanovení abecedy; nebudeme je zde proto opakovat.
2. Makrostrukturní popis soustavy digrafů. Při makrostrukturním popisu nám jde o stanovení obecných kvantitativních charakteristik soustavy digrafů (nebo obecně: grafémových skupin), čili o zjištění kombinačních schopností abecedy jako celku. Protože ve skupinách grafémů je relevantní uspořádání prvků (skupina AB je odlišná od skupiny BA) a protože ve skupinách se může každý prvek libovolněkrát opakovat (např. NN, ONO atd.), jsou skupiny grafémů z hlediska kombinatoriky tzv. variace s opakováním.
Kombinační schopnosti abecedy jsou vystiženy variačním poměrem, který definujeme jako poměr počtu realizovaných grafémových skupin k teoreticky možnému počtu skupin.[9] Teoreticky možný počet variací s opakováním je udán výrazem nk, kde n je počet prvků a k je třída variací. Označíme-li počet realizovaných grafémových skupin jako r, potom je variační poměr udán vzorcem:
![]()
kde n je počet grafémů v abecedě a k je třída grafémových skupin. Pro případ digramových skupin má vzorec tvar:
![]()
Dosadíme-li do tohoto vzorce zjištěný počet realizovaných digrafů (r = 1028) a teoreticky možný počet variací s opakováním druhé třídy z abecedy o 42 prvcích (422 = 1764), dostáváme hodnotu variačního poměru soustavy digrafů v psané češtině:
![]()
Hodnota variačního poměru ukazuje, že efektivnost využití digramových skupin je v češtině poměrně nízká; realizována je jen zhruba polovina z možných digrafů.
[169]Ve fonologické soustavě češtiny zjistil analogickou skutečnost Mathesius.[10] Z konfrontačního kvantitativního studia českých a německých slov vyvodil poznatek, že česká fonologická soustava může teoreticky vytvářet skoro o 50 % více skupin než německá, ale že čeština využívá těchto možností s efektivností téměř o polovinu menší než němčina. (To se vysvětluje typologickými vlastnostmi češtiny, v níž je výrazná tendence obměňovat strukturu slova několika prvky současně, takže není nutné vyčerpávat většinu možných spojení.) Nadto lze ještě, ze srovnání Mathesiových výsledků s Vachkovými,[11] dojít k závěru, že se zvyšováním počtu teoretických možností ve fonémových skupinách vyšších tříd (tříčlenných a vícečlenných) klesá zároveň velmi značně efektivnost jejich využití. Exaktně tuto zákonitost ještě dokázat nelze, a to ani pro grafematickou soustavu, protože nemáme zatím k dispozici četnosti trigrafů a grafémových skupin vyšších tříd (počet možných trigrafů v češtině je 74 088, počet tetragrafů již 3 111 696), ale předběžné údaje ji potvrzují.
3. Mikrostrukturní popis digrafů. Každý jednotlivý grafém je možno charakterizovat několika kvantitativními znaky náhodné povahy, zejména relativní četností, valencí a entropií valenčního pole. Relativní četnost (xi) je pojímána ve smyslu matematické statistiky; hodnoty relativních četností českých grafémů přejímáme z práce citované v pozn. 8. Valenci grafému určujeme pro případ digrafů jako poměr počtu grafémů, s nimiž daný grafém vytváří digramové skupiny (a), k celkovému počtu grafémů (A), tedy
![]()
Entropie valenčního pole (Hi(2)) je entropie rozložení podmíněných pravděpodobností grafémů, které s daným grafémem vytvářejí digramovou skupinu; je počítána podle známého Shannonova vzorce.[12] Protože v této stati považujeme za rozhodující pro kombinatoriku grafémů závislosti ve směru odleva doprava, je jak valence, tak entropie valenčního pole uvažována pouze pro zadní pole grafému.
Uvedené náhodné znaky nabývají u každého grafému různých hodnot, takže můžeme získat obraz jejich rozložení. V tabulce 1 jsou uspořádány grafémy podle klesajících relativních četností (xi), k nimž jsou přiřazeny příslušné hodnoty valence (vi(2)) a entropie valenčního pole (Hi(2)).
Při porovnání rozložení xi s hodnotami rozložení vi(2) a rozložení Hi(2) možno pozorovat:
a) V rozložení vi(2), které není záměrně uspořádáno podle klesajících hodnot, projevují hodnoty vi(2) vcelku rovněž tendenci k poklesu. Podobnou tendenci je možno shledat i při konfrontaci rozložení xi s rozložením Hi(2). Je tu však více odchylek a tendence k poklesu není v rozložení H tak výrazná jako u hodnot vi(2).
b) Projevují se dost značné rozdíly v rozložení relativních četností, valencí a entropií mezi třídami abecedy, zvláště mezi třídou samohlásek krátkých a třídou samohlásek dlouhých.
4. Korelace kvantitativních znaků v české abecedě a jejích třídách. Tato jen intuitivně založená zjištění se pokusíme doká[170]zat exaktně korelační analýzou. Omezíme se na zkoumání závislosti dvojic kvantitativních znaků (relativní četnost — valence; relativní četnost — entropie) a určíme jednak formu korelace, jednak intenzitu korelace; obojí bude stanoveno podle vzorce pro korelační koeficient dvou proměnných, jenž je definován jako
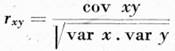
kde
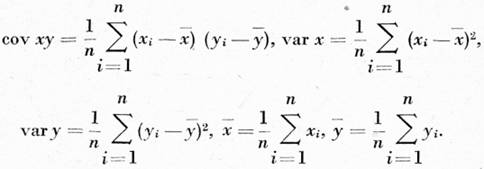
Hodnoty koeficientů vypočítané podle tohoto vzorce spolu s průměry rozložení xi, vi(2) a Hi(2) jsou uvedeny v tabulce 2.[13] Kladné hodnoty korelačních koeficientů prokazují v obou případech přímou (funkční) lineární závislost, těsnost závislosti je však různá. Z hodnot koeficientů korelace, rxv = 0,617 a rxH = 0,537, je patrné, že závislost mezi relativní četností grafémů a valencí je větší než závislost mezi relativní četností a entropií. (Koeficient rxv se ukázal významný na hladině významnosti α = 0,005 a koeficient rxH na hladině významnosti α = 0,01.) Tento rozdíl v těsnosti závislosti, který se však neobjevuje u jednotlivých tříd abecedy, je vysvětlitelný různým typem srovnávaných hodnot: entropie, na rozdíl od relativní četnosti a valence, není hodnotou grafému samého, nýbrž reprezentuje rozložení podmíněných pravděpodobností ve valenčním poli každého grafému. Proto grafémy, které mají téměř stejnou relativní četnost a valenci, např. É a Ž, se mohou značně lišit v hodnotách entropie valenčního pole: grafém É, v jehož valenčním poli má značně velkou pravděpodobnost spojení s mezerou (0,63480), je charakterizován malou entropií (2,07427), kdežto grafém Ž má entropii značně vyšší (3,10211), protože pravděpodobnosti spojení s jinými grafémy jsou v jeho valenčním poli rozloženy mnohem rovnoměrněji, jak je vidět z tabulky 3.
Také u tříd abecedy se ukazuje přímá lineární závislost mezi relativní četností a valencí a mezi relativní četností a entropií valenčního pole, přičemž těsnost závislosti je většinou vysoká. Korelační koeficienty pro třídy abecedy jsou shrnuty v tabulce 4.
Uspořadáme-li třídy podle klesajících hodnot průměrné relativní četnosti do posloupnosti: samohlásky krátké, souhlásky, samohlásky dlouhé, pak ve stejném pořadí klesají i průměrné hodnoty valence a průměrné hodnoty entropie. Neboli: čím vyšší je průměrná relativní četnost třídy, tím vyšší je její průměrná valence [171]a entropie. A současně s rostoucími průměrnými hodnotami relativní četnosti, valence a entropie roste také těsnost vztahu mezi nimi.
Významný je rozdíl v hodnotách relativní četnosti, valence a entropie mezi samohláskami krátkými a samohláskami dlouhými. Jednotlivé dlouhé samohlásky mají vždy nižší relativní četnost a nižší valenci než příslušné samohlásky krátké; rovněž celá třída samohlásek dlouhých má nižší průměrné hodnoty x̅, v̅, H̅(2) než třída samohlásek krátkých. Také těsnost vztahu mezi relativní četností a valencí a mezi relativní četností a entropií je menší u samohlásek dlouhých než u samohlásek krátkých.
5. Shrnutí výsledků. Korelace zjištěná mezi relativní četností grafému na jedné straně a jeho valencí, resp. entropií valenčního pole na straně druhé vyjadřuje statistickou závislost mezi výskytem grafému a jeho kombinatorními schopnostmi (funkčním zatížením). Statistický výpočet ovšem neurčuje směr této závislosti: můžeme stejně říci, že kombinatorní schopnosti grafému závisí na jeho relativní četnosti, jako že relativní četnost grafému je závislá na kombinatorních schopnostech. Zdálo by se na první pohled, že zjištění této závislosti je triviální; vždyť se zdá samozřejmé, že některé grafémy mají vysokou četnost výskytu právě proto, že vytvářejí mnoho skupin, jako na druhé straně to, že nízká četnost výskytu je způsobena malým počtem realizovaných skupin. Avšak toto uspořádání, třebaže je nepochybně „přirozené“, není zdaleka jediné možné. Lze si představit jazyk s jinou statistickou strukturou, např. takovou, že by u grafémů s vysokou četností byly výskyty nakupeny jen u jedné nebo několika mála skupin.
Nejdůležitějším důsledkem našich zjištění je konstatování, že kombinatorní vlastnosti grafému, které samy jsou kvantitativní povahy, jsou závislé na jiné vlastnosti kvantitativní povahy, na četnosti výskytu grafému. Tak se vynořují autonomní vztahy mezi základními rysy kvantitativní struktury jazyka. Tyto vztahy bude ovšem třeba zkoumat a ověřovat i na jiných rovinách jazykové výstavby a teprve potom bude možno formulovat obecnější hypotézy.
R é s u m é
COMBINATORIAL PROPERTIES OF THE CZECH GRAPHEMIC SYSTEM
The present paper is a contribution to the quantitative analysis of the graphemic system of literary Czech taking up again the subject treated in a recent paper by L. Doležel, Předběžný odhad entropie a redundance psané češtiny (Preliminary estimation of entropy and redundancy of written Czech) (SaS 24, 1963). There is a definition of the grapheme valency ⟨vi(n)⟩ expressed as a ration of the number of graphemes admissible as the second element of the n-gram combination, and that of entropy of the valency field ⟨Hi(n)⟩ defined in terms of conditioned probabilities of graphemes combinable with the given letter.
The authors ascertain the relation between a) the relative frequency of graphemes ⟨xi⟩ and their digram valency ⟨Vi(2)⟩ (correlation coefficient rxv = 0.6) b) the relative frequency of graphemes and entropy ⟨Hi(2)⟩ (correlation coefficient rxH = 0.5). On the basis of the results obtained a hypothesis is proposed that the combinatorial capacity of graphemes (termed in the existing literature „the functional load“) is to a great extent dependent on their frequency. This observation seems to be a fundamental statistical law of the grapheme combinatorics and perhaps of other linguistic unit in Czech.
[172]Tabulka 1
ROZLOŽENÍ RELATIVNÍCH ČETNOSTÍ, VALENCÍ A ENTROPIÍ
| grafém | xi | vi | Hi |
| mez. E O A N V T S K I L U R P M D Í Á J Z Y Ň B H É C CH Ř Ž Ý Č Š Ť Ě Ú Ď F G X Ó W Q | 0,16586 0,07261 0,06866 0,05431 0,04036 0,03953 0,03870 0,03743 0,03368 0,03303 0,03293 0,02999 0,02932 0,02792 0,02788 0,02643 0,02490 0,02153 0,02088 0,01902 0,01623 0,01437 0,01363 0,01095 0,01046 0,01045 0,00974 0,00971 0,00956 0,00852 0,00784 0,00746 0,00652 0,00619 0,00546 0,00414 0,00194 0,00168 0,00062 0,00042 0,00011 0,00003 | 0,84444 0,84444 0,84444 0,78571 0,78571 0,78571 0,69047 0,71428 0,71428 0,85714 0,85714 0,71428 0,83333 0,66666 0,71428 0,80952 0,61904 0,59523 0,73809 0,78571 0,69047 0,30952 0,71428 0,57142 0,52380 0,54761 0,54761 0,47609 0,50000 0,54761 0,40475 0,52380 0,28573 0,52380 0,54761 0,26190 0,42857 0,38095 0,21428 0,14285 0,16666 0,04861 | 4,33909 3,81532 3,98109 3,78501 3,63517 4,24206 3,90334 3,77571 3,78538 3,79694 3,79087 3,43002 3,88935 3,12543 3,56125 4,07249 2,98174 3,96573 2,98945 4,22302 2,69584 1,83249 3,99233 3,09676 2,07427 2,92617 2,93964 2,43522 3,10211 2,96267 3,39764 3,33913 2,02880 3,75074 3,33305 2,09844 3,35411 3,20388 2,73319 1,70548 2,55035 0,91830 |
|
| 1,00000 | 24,53766 | 135,55727 |
[173]Tabulka 3
ROZLOŽENÍ PODMÍNĚNÝCH PRAVDĚPODOBNOSTÍ VE VALENČNÍM POLI GRAFÉMŮ É A Ž
| grafém | valenční pole | |
| É | Ž | |
| A Á B C Č D Ď E É Ě F G H CH I Í J K L M N Ň O Ó P R Ř S Š T Ť U Ú V Y Ý Z Ž mez. Q W X | — — 0,00382 0,00096 0,01052 0,00095 — — — — 0,00574 — 0,13384 0,00096 — — — 0,02008 0,00382 0,07553 0,02103 0,00574 — — 0,00478 0,00574 — 0,00669 0,00095 0,02103 0,00096 — — 0,01816 — — 0,00382 0,02008 0,63480 — — — | 0,01674 0,02197 0,00418 0,00418 — 0,04812 0,01464 0,26255 — — — — — — 0,12761 0,07950 0,00105 0,02929 0,01360 — 0,03347 0,01151 0,02092 — — — — 0,01046 0,00628 0,00523 — 0,00941 — 0,00105 — — — — 0,27824 — — — |
| xi | 0,01046 | 0,00956 |
| vi(2) | 0,52380 | 0,50000 |
| Hi(2) | 2,07427 | 3,10211 |
[174]Tabulka 2
KORELACE KVANTITATIVNÍCH ZNAKŮ V ČESKÉ ABECEDĚ
|
| x̅ | v̅(2) | H̅(2) | rxv | rxH |
| A | 0,02380 | 0,58423 | 3,22755 | 0,617 | 0,537 |
Tabulka 4
KORELACE KVANTITATIVNÍCH ZNAKŮ V TŘÍDÁCH ČESKÉ ABECEDY
|
| x̅ | v̅(2) | H̅(2) | rxv | rxH |
| samohlásky krátké | 0,04565 | 0,78571 | 3,58781 | 0,802 | 0,795 |
| souhlásky | 0,01720 | 0,55182 | 3,21086 | 0,819 | 0,620 |
| samohlásky dlouhé | 0,01188 | 0,49602 | 2,91293 | 0,708 | 0,585 |
[1] F. Harary - H. Paper, Toward a general calculus of phonemic distribution, Language 33, 1957, 143—169.
[2] H. Spang-Hanssen, Probability and Structural Classification in Language Description, Copenhagen 1959.
[3] V. Mathesius, La structure phonologique du lexique du tchèque moderne, TCLP 1, 1929, 67—85; Úvod do fonologického rozboru české zásoby slovní, sb. Čeština a obecný jazykozpyt, Praha 1947, 62—87.
[4] J. Vachek, Poznámky k fonologii českého lexika, LF 67, 1940, 395—402.
[5] B. Trnka, A Phonological Analysis of Present Day Standard English, Praha 1935. — J. Krámský, Fonologické využití samohláskových fonémat, Linguistica Slovaca IV—VI, Bratislava 1946—1948, 39—43 a jeho další práce.
[6] K. Korvasová - B. Palek, Některé vlastnosti entropie českého slovníku, SaS 23, 1962, 58—66.
[7] K. Korvasová - B. Palek, Některé kvantitativní charakteristiky kombinací písmen v českém slovníku, AUC - Philologica, Slavica Pragensia IV, Praha 1962, 89—95.
[8] L. Doležel, Předběžný odhad entropie a redundance psané češtiny, SaS 24, 1963, 165—175.
[9] Srov. s obdobným pojmem „kombinační poměr (koeficient)“, který byl definován v studii L. Doležela Jména zdrobnělá (Kvantitativní rozbor), sb. Tvoření slov v češtině 2 (v tisku).
[10] V. Mathesius, o. c. v pozn. 3, s. 85.
[11] J. Vachek, o. c. v pozn. 4.
[12] Valenčním polem grafému v tomto článku rozumíme množinu všech grafémů, které s daným grafémem vytvářejí digramové variace. Všechny zde definované pojmy (valence, valenční pole, entropie valenčního pole) lze ovšem zobecnit pro případ n-gramových variací.
[13] Hodnota H̅(2) = 3,22755 je ekvivalentní s hodnotou entropie druhého řádu H2, počítané podle vzorce — ∑ pij log2 pij + ∑ pi log2 pi. V cit. článku L. Doležela na s. 168 je uvedena H2 = 3,8710 počítaná na základě tabulky digramových spojení, která je připojena k článku. Dodatečně se však ukázalo, že tato tabulka obsahuje několik nepřesností.
Hodnota H̅(2) = 3,22755 je tedy zároveň opraveným odhadem entropie druhého řádu psané češtiny.
Slovo a slovesnost, volume 25 (1964), number 3, pp. 166-174
Previous Jan Šabršula: Ke srovnávacím studiím slovosledným (Některé otázky větné perspektivy ve francouzštině ve srovnání s češtinou)
Next Oldřich Králík: Dvě kapitoly o Máchově jazyku
© 2011 – HTML 4.01 – CSS 2.1