
Náhodné generování českých vět
Karel Pala
[Articles]
Случайное генерирование чешских предложений / La génération au hasard des phrases tchèques
1. Úvod. Článek referuje o výsledcích experimentů s náhodným generováním českých vět na samočinném počítači. Oddíl 1 obsahuje několik úvodních poznámek a stručný obsah článku, v oddíle (2) probíráme tzv. nespojitou generativní gramatiku G1 (dále jen G1), která představuje generativní popis části českého syntaktického systému. Ačkoli jsme si dobře vědomi vztahů syntaxe k ostatním jazykovým rovinám, omezujeme se zde jen na čistě syntaktickou problematiku. Z této skutečnosti zejména plyne, že se nezabýváme problematikou morfologické syntézy; proto terminální slovník (VT) v G1 obsahuje celé slovní tvary. V oddíle (3) je hlavní pozornost věnována východiskům [46]a možnostem formalizace tradičních syntaktických pojmů při vytváření generativního popisu češtiny, tj. při sestavování gramatiky G1. Gramatika G1 umožňuje v současné době neúplně popsat strukturu jednoduché věty, některé typy vět tázacích, souvětí souřadných a podřadných.
Oddíl 4 obsahuje popis algoritmu syntézy a stručnou informaci o programu pro samočinný počítač. Program je zapsán v programovacím jazyce ALGOL-GENIUS a byl v červnu až srpnu 1967 úspěšně ověřen na samočinném počítači SAAB D 21 v Laboratoři počítacích strojů VUT v Brně. Během této doby bylo generováno více než 1300 vět a experimenty prokázaly spolehlivost programu i jeho univerzálnost. Současně se ukázalo, že programovací jazyk ALGOL-GENIUS je velmi vhodný pro programování lingvistických úloh logického typu. V oddíle 5 uvádíme ukázky získaných výsledků a některé stručné závěry.
2. Gramatika G1. Generativní procedura pro češtinu je tvořena dvěma relativně samostatnými částmi: 1. tzv. nespojitou gramatikou G1; 2. programem pro samočinný počítač, který udává přesná pravidla fungování gramatiky G1.
2.1. V současné době se sice často namítá,[1] že nekontextové gramatiky nejsou adekvátním modelem pro popis systémů přirozených jazyků, a jsou proto navrhovány modely složitější, zejména tzv. transformační gramatiky Chomského.[2] Pro všechny složitější modely je však typické, že obsahují nekontextové gramatiky jako své základní složky (nebo systémy s nekontextovými gramatikami slabě ekvivalentní). Proto soudíme, že má smysl i dnes pracovat na sestavení nespojité gramatiky popisující syntax češtiny.
Na generativní procedury klademe dva základní požadavky: (1) procedura má vymezovat (generovat) množinu gramaticky správných vět příslušného jazyka; (2) každé generované větě má tato procedura automaticky přiřazovat strukturní popis, kterým se podle N. Chomského[3] rozumí specifikování prvků, z nichž se věta skládá, tj. specifikování jejich pořadí a vzájemného uspořádání, vztahů a jakékoli další informace o tom, jak se věta chápe a užívá v syntaktickém slova smyslu. Splnitelnost požadavků 1 a 2 je komplikovaná záležitost; můžeme jen konstatovat, že požadavek 1 nebyl pro přirozené jazyky dosud nikdy splněn v žádné existující generativní proceduře v plném rozsahu a požadavek 2 je splňován u nekontextových gramatik jen do jisté míry, u gramatik transformačních se na těchto otázkách intenzívně pracuje. Podstatné je zde to, jak mají strukturní popisy z hlediska lingvistického vypadat, tj. jakou informaci o struktuře věty má strukturní popis obsahovat. Je např. zcela jasné, že zmíněná Chomského definice strukturního popisu není příliš přesná a neřeší jádro věci. Nesmíme dále ztrácet ze zřetele, že charakter informace o struktuře věty, která je nebo má být obsažena v strukturním popisu, má totiž zpětný přímý vliv na formulaci a podobu celé generativní procedury a na její formální vlastnosti. Budeme-li požadovat, aby strukturní popis obsahoval podrobné informace o struktuře věty (což je zcela [47]oprávněné), může být na druhé straně důsledkem nepříjemná skutečnost, že taková generativní procedura by byla velmi komplikovaná a prakticky nezvládnutelná.
Chomsky[4] řeší tuto otázku tak, že navrhuje vyjít z informace o struktuře věty, která je k dispozici v tradičních gramatikách, a prezentovat ji v podobě strukturního popisu, který lze generovat systémem explicitních pravidel, tj. např. nekontextovou nebo ekvivalentní nespojitou gramatikou. Poněkud jiné řešení téhož problému předkládá u nás nyní P. Sgall (o. c. v pozn. 1, s. 78—161), ale i u něho je východiskem pro sestavování strukturních popisů informace obsažená v tradičních českých gramatikách. Problematikou strukturních popisů v G1 se budeme znovu zabývat v odd. 3.
2.2. Předpokládáme, že problematika generativních gramatik a jejich formální vlastnosti jsou všeobecně známy z prací N. Chomského, Y. Bar-Hillela a dalších, a přistoupíme proto přímo k definici G1.
Nechť je dána nespojitá gramatika G1 = (VT, VN, R, S), kde množinu VT interpretujeme jako terminální slovník, tj. jako množinu jednotlivých českých slovních tvarů (nepřihlížíme k morfologii). VT obsahuje v této verzi 322 slovních tvarů vyexcerpovaných z prózy J. Seiferta, a to 83 substantiv, 73 adjektiv, 52 slovesných tvarů určitých, 56 slovesných tvarů neurčitých (příčestí a infinitivů), 29 adverbií, 15 předložek, 10 spojek, 2 tázací slova, 2 zájmena.
Množinu VN interpretujeme jako nonterminální slovník, tj. jako množinu gramatických (přesněji syntaktických) kategorií popisujících část české syntaxe. VN čítá u nás 115 gramatických kategorií. Podrobný lingvistický rozbor množiny VN následuje v odd. 3.
R je konečná množina nekontextových přepisovacích pravidel majících tvar A → B, A → CD, D → CEB, kde A, B, C, D, E∊VN, E → a, kde E∊VN, a ∊VT, a pravidel majících tvar F → G … H, která se od předchozích nekontextových pravidel liší tím, že dovolují přesně stanoveným způsobem permutovat symboly (tím se přibližují spíše pravidlům transformačním), přesto však gramatiky obsahující tento typ pravidel (a tedy i G1) patří do třídy gramatik slabě ekvivalentních s nekontextovými gramatikami.[5] Dále platí, že R = R1∪R2 a R1∩R2 = ∅. Podmnožina R1 je tvořena všemi pravidly kromě pravidel tvaru E → a, která se nazývají lexikální, protože na pravé straně obsahují pouze terminální symboly, R1 čítá 46 pravidel, R2 — 69 pravidel. Tento rozklad na množině R vyplývá z formálních vlastností pravidel a je ho s výhodou využito v programu syntézy.
S je vyznačený počáteční symbol a platí, že S∊VN. Každá derivace v G1 musí začínat tímto symbolem.
3. Lingvisticka interpretace množiny VN. Jak jsme již řekli, množina VN představuje slovník gramatických kategorií, jejichž prostřednictvím popisujeme příslušnou (u nás syntaktickou) rovinu jazykového systému nebo její část. Sestavení VN a volba gramatických kategorií je čistě empirická záležitost, avšak lingvista se musí při zařazování gramatických kategorií do VN řídit formálními vlastnostmi generativní gramatiky, tj. musí být bezpodmínečně dodrženy požadavky explicitnosti a formalizovanosti popisu. Ostatní vodítka při sestavování VN jsou podle našeho názoru již čistě empirická; [48]jde tu o to, jak podrobný má být strukturní popis věty (tj. frázový ukazatel — FU), jaká informace je nutná a jaká nadbytečná, zda strukturní popisy, které mají být gramatikou generovány, budou dostatečně srozumitelné, přehledné a čitelné.[6]
Při sestavování množiny VN pro G1 jsme se opírali o citované názory N. Chomského a dalších a snažili jsme se, aby strukturní popisy vět odpovídaly tomu, co lze najít o struktuře věty v tradičních gramatikách češtiny.[7] Strukturní popis věty (zde jde o konkrétní gramatiku, proto budeme raději mluvit o frázovém ukazateli — FU) generovaný G1 obsahuje tedy údaj o typu věty (oznamovací, tázací, s větným záporem atd.), dále údaje o podmětové části věty a o její vnitřní stavbě (o rozvitosti a o složkách — členech, z nichž se skládá), údaje o přísudkové části věty, o typu přísudku a o tom, jak je rozvit. Generuje-li se věta s nevyjádřeným podmětem nebo věta jednočlenná, informace o podmětové části věty odpadá, zato přísudková část věty je specifikována poněkud jinak než v normálních dvojčlenných větách. Jistý problém, s nímž je třeba se při sestavování VN pro češtinu vyrovnat, spočívá v tom, že všechny existující tradiční gramatiky češtiny jsou budovány na závislostním pojetí české syntaxe. Tato okolnost způsobuje určité potíže, protože při přechodu od závislostní koncepce ke koncepci bezprostředních složek je nutno řešit některé nově vznikající problémy, např. při výskytu více adverbiálních určení u jednoho slovesa musíme rozhodnout, které budeme považovat za těsnější doplnění a které za volnější.
To znamená, že v rámci VN musíme formulovat některé gramatické kategorie, které jsou jistými obdobami tradičních větných členů, tj. podmětu, přísudku, přívlastku, předmětu, adverbiálního určení, dále je třeba definovat preterminální kategorie, které lze pokládat za obdobu slovních druhů. Máme tedy ve VN symboly označující substantiva a jejich pády (N1, …, N7 — singulár, N1M, …, N7M — plurál), adjektiva (A1, …, A7, A1M, … A7M), slovesné tvary určité (V3 — 3. os. sg. préz. akt., V1M — 1. os. pl. préz. akt. aj.), slovesné tvary neurčité (VI — infinitiv, VPAS — příčestí trpné, VL — příčestí minulé), zájmena (PRON), příslovce (AD), předložky a spojky, přičemž platí, že všechny uvedené symboly se vyskytují na levých stranách lexikálních pravidel. Kromě těchto gramatických kategorií je nutno ve VN zavést ještě některé další gramatické kategorie, jež nemají obdoby v tradičních gramatikách, ale zde jsou nutné pro splnění požadavku explicitnosti popisu. Např. v tradičních gramatikách bývá zpravidla uvedeno, jakými větnými členy může být rozvit podmět věty, žádná tradiční gramatika však neuvádí podrobně a systematicky jednotlivé stupně složitosti (rozvitosti) podmětu, protože počítá s tím, že uživatel gramatiky se opírá o své jazykové povědomí a je tedy s to chybějící údaje sám doplnit. V generativním popisu musí však být zachyceny všechny možnosti, má-li být popis explicitní.
Ve VN jsou rozlišeny tyto větné typy: S — věta oznamovací, SK — souvětí s koordinací, SN — věta obsahující větný zápor, STĀZD — věta tázací doplňovací, SY — kategorie neexistující v tradiční gramatice, ale ve VN nutná [49]pro derivování SK (souřadného souvětí), např. počáteční část nějakého daného frázového ukazatele může vypadat takto:
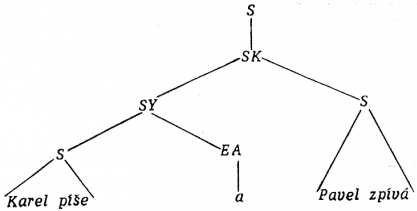
obr. 1
Větným členům odpovídají ve VN následující kategorie: NP — podmětová část věty nebo podmět sám (symbol NP je rekurzívní), NPM — podmětová část věty nebo podmět v plurálu (je to vyžadováno shodou), NPT a NPH jsou samostatné kategorie nemající tradiční obdoby, jsou nutné pro generování podmětu rozvitého několikanásobným adjektivním přívlastkem. Strukturu podmětu obsahujícího též symboly NPT a NPH ukazují např. dílčí FU na obr. 2 (EA označuje kategorii souřadicích spojek):
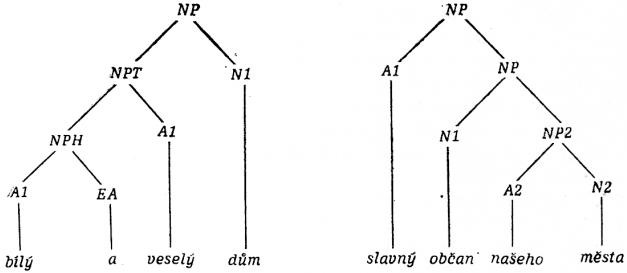 obr. 2
obr. 2
VP — přísudková část věty, přičemž VP je také rekurzívní a lze z ní generovat jednotlivé typy přísudku v tradičním slova smyslu, VPO — přísudek ve větě jednočlenné nebo ve větě s nevyjádřeným podmětem, VPN — přísudek se záporem, VPVN — přísudek verbonominální. Z těchto kategorií lze s použitím dalších kategorií, např. PVN, PREF1, PREF2 aj., generovat jednotlivé slovesné tvary určité, buď složené, nebo jednoduché, s jejich rozvíjejícími členy, tj. předmětem nebo adverbiálním určením. V této souvislosti jsme se pokusili ve VN třídit slovesa na podmětová a předmětová (přechodná a nepřechodná). I když toto třídění bylo velmi hrubé a bylo provedeno jen zkusmo, ukázalo se, že je velmi užitečné a závažné pro sémantiku věty a že by vyžadovalo podrobnějšího rozpracování (P. Sgall, o. c. v pozn. 1, s. 97—104). [50]Největší potíže činí zde postižení vztahů mezi slovesy a jejich adverbiálními určeními, zejména pokud jde o míru těsnosti a volnosti doplnění a o otázku, které typy adverbiálních určení jsou u jednotlivých tříd sloves nutné, možné nebo jen přípustné a v jakých vzájemných kombinacích (P. Sgall, o. c. v pozn. 1, s. 87—97). Tyto problémy nebyly ovšem v tradičním popisu soustavně zkoumány; zdá se však jasné, že v rovině formální syntaktické stavby věty nemůžeme najít spolehlivé řešení. Bude pravděpodobně třeba vyjít ze zákonitostí sémantické stavby věty a mezivětných vztahů jak kontextových, tak aktuálně členských.
Dále jsou ve VN rozlišeny tyto obdoby rozvíjejících větných členů: A1, …, A7 — adjektivní přívlastek shodný, čísla udávají jednotlivé pády adjektiv na základě shody s řídícím substantivem, např. kategorie A3 N3 lze při syntéze věty přepsat pravidly A3 → pěknému, N3 → děvčeti, takže dostaneme pěknému děvčeti, AP — přívlastek adjektivní rozvitý, např. velmi chytrý apod., NP2 — přívlastek neshodný genitivní, např. stavba domu, PP2, …, PP7 — přívlastky neshodné vyjádřené předložkovými pády, např. N1 PP7 — dívka s ptáčkem, N4 PP2 — člověka bez svědomí aj., NP4 — akuzativní předmět přímý, NP2 — genitivní předmět, např. V3 NP2 — dbá pravdy atd., NP3 — dativní předmět, NP7 — instrumentálový předmět nebo adverbiální určení, AD — adverbiální určení, je-li vyjádřeno vlastním příslovcem (s tříděním na ADL — určení místa, ADT — času, ADM — způsobu, ADC — příčiny, ADQ — míry); adverbiálnímu určení v tradičním pojetí odpovídají též nutně kategorie PP2, …, PP7 a některé z NP2, …, NP7, dále ADS — určení vyjádřené příslovečnou větou vedlejší.
Z toho, co jsme uvedli, je vidět, že se vědomě vyhýbáme tradičnímu problému „objekt nebo adverbiální určení“ a vycházíme jen ze skutečnosti, že jednotlivé třídy sloves mohou mít jako doplnění buď kategorie typu NP a AD, nebo NP a PP, nebo PP a AD, nebo jen AD či PP. Toto řešení se v rámci G1 ukázalo jako výhodné a předkládáme k úvaze, zda je za každých okolností nutno trvat na rozhodnutí „předmět nebo příslovečné určení“. Jsou-li potíže s klasifikací některých jazykových jevů, mělo by to vést jednak k přezkoumání jejich vnitřní povahy, ale především bychom měli znovu analyzovat svá klasifikační kritéria a položit si otázku: je tato klasifikace skutečně plně oprávněná?
3.1. Lingvistická interpretace množiny R. Sestavením množiny VN gramatických kategorií jsme však udělali teprve první krok při formulování generativního popisu české syntaxe. Dále je třeba učinit krok druhý: uvést zvolené gramatické kategorie do vzájemných vztahů, abychom mohli jednak generovat věty a jednak přiřazovat jim jejich strukturní popisy. Právě k tomu slouží množina R přepisovacích pravidel: postupným aplikováním pravidel z R přesně stanoveným způsobem lze generovat jednotlivé české věty s jejich frázovými ukazateli. Generování každé věty začíná vždy symbolem S, který je levou stranou jednoho pravidla z R; pak se symbol S nahradí jednou z odpovídajících pravých stran a symboly, které byly takto získány, se hledají opět na levé straně některého pravidla z R (postupuje se přitom např. tak, že se nahrazuje vždy nejlevější symbol v derivovaném řetězu, tím vznikne tzv. nejlevější derivace). Jakmile se hledaný symbol vyskytuje jako levá strana, opět se nahradí a tak se pokračuje, dokud použitím lexikálních pravidel nejsou všechny symboly nahrazeny terminálními. Pak je derivace ukončena a výsledkem je generovaná věta a její frázový ukazatel. Např. pravidlo 1 z R vypadá takto:
| [51]S → |
| STÁZD SN
SK
VPO | NP VP VP NP
NPM VPM
VPM NPM |
|
tj. v nezkráceném zápise: | S → STÁZD S → SN .... .... .... S → VPM NPM |
Jednoduchá derivace krátké české věty s použitím pravidla 1 vypadá pak takto (věta byla skutečně generována počítačem včetně frázového ukazatele):
| derivace: | S
VPO
V3
UMIRA | FU: S | VPO | V3 | umírá | použitá pravidla:
S → VPO (1)
VPO → V3 (24)
V3 → umírá (71) |
Podobně bychom mohli uvést pravidlo generující přísudkovou část věty (VP), které je ovšem složitější a je vlastně tvořeno 24 jednoduchými pravidly. V současné době lze v R pracovat také s pravidly tvaru VP → AD V3 NP4, která již dovolují větší úspornost popisu a jsou s to zachytit i některá kontextová omezení. Pravidlům popisujícím tzv. nespojité složky (např. PREF2 → V3 … AD) nebyla tentokrát věnována zvláštní pozornost, jejich fungování a vhodnost jsme si ověřili již dříve.[8] Otázky související s užitím těchto pravidel budou moci být v plném rozsahu řešeny až při podrobném empirickém zkoumání, které musí předcházet před sestavením relativně úplného generativního popisu české syntaxe.
Z lingvistického hlediska je důležité, že množinu pravidel, jakou je v našem případě R, lze vždy konstruovat několika různými způsoby při použití stejného nonterminálního slovníku (VN). Výsledky pak mohou být dosti odlišné, zejména pokud jde o praktickou efektivnost a přehlednost popisu, a lingvisté by měli ve svém zájmu konstruovat vždy několik množin pravidel (jako je R) a na základě porovnávání se rozhodnout pro nejlepší generativní popis.
4. Algoritmus syntézy. Při sestavování algoritmu syntézy, jehož fungování jsme již do jisté míry naznačili v odd. 3.1., opírali jsme se zčásti o známý algoritmus V. H. Yngveho,[9] zčásti jsme využili poznatků o zásobníkových automatech.[10] Algoritmus pracuje cyklicky v pěti krocích:
1. Vlož symbol S na vrchol zásobníkové paměti (dále jen ZP) a tiskni S ! (ZP si lze představit jako pásku, na niž lze zapisovat symboly pouze na jedné straně — levé, která se pak nazývá vrcholem ZP. Symboly se do ZP zapisují podle pravidla: „po[52]slední dovnitř, první ven“, tj. symbol, který byl do ZP zaznamenán poslední, musí být čten jako první, např. po provedení kroku 1 vypadá ZP se zapsaným S takto:
, tj. S je zapsán na vrcholu ZP.)
2. Symbol na vrcholu je terminální? Není-li, jdi na 3, je-li, vytiskni a vymaž terminální symbol z vrcholu ZP, jdi na 5! (Je-li ze ZP vymazán nejhořejší terminální symbol, platí, že vrcholem ZP se stává symbol, který byl uložen bezprostředně pod vymazaným symbolem.)
3. Je nejhořejší symbol v ZP levou stranou nějakého pravidla z množiny R (v odd. 3.1.)? Je-li, jdi na 4, není-li, chyba, přeruš generování dané věty, vymaž obsah ZP a jdi na 1.
4. Nahraď nalezenou levou stranu některou odpovídající pravou stranou! Vybranou pravou stranu ulož na vrchol ZP tak, že se v případě jednoho symbolu na pravé straně obsah ZP co do počtu nemění, pouze se nahrazuje jeden symbol druhým; v případě, že pravá strana obsahuje dva nebo více symbolů, zvětšuje se ZP o příslušný počet symbolů a nejhořejším symbolem v ZP se stává nejlevější symbol dané pravé strany. (Např. obsah ZP je
.) Nejhořejší uložený symbol vytiskni a jdi na 3!
5. Obsahuje ZP aspoň jeden symbol? Jestliže ano, jdi na 2, jestliže ne, generování věty je ukončeno, jdi na 1!
Je vidět, že se během práce algoritmu tiskne nejlevější derivace, která odpovídá jednoznačně ohodnocenému orientovanému grafu-stromu, tj. frázovému ukazateli generované věty. Po malé úpravě by bylo možno tisknout místo nejlevější derivace věty derivaci nejpravější, z technických důvodů však dáváme přednost levé derivaci, souvisí to s použitím pravidel tvaru E → F … H.
4.1. Program syntézy. Na základě uvedeného algoritmu byl sestaven program syntézy pro samočinný počítač SAAB D 21, který je napsán v programovacím jazyce ALGOL-GENIUS.[11] Program je rozšířen (proti uvedenému algoritmu) o úpravy dovolující pracovat s pravidly E → F … H. Výběr jednotlivých pravých stran pravidel a terminálních symbolů je v programu prováděn náhodně využitím standardní algolovské procedury „random“ (tj. standardního podprogramu), která produkuje posloupnosti pseudonáhodných čísel.
Např. obsahuje-li daná pravá strana 8 možností výběru, jak je tomu třeba u pravidla 1 v odd. 3.1., pak všechny možnosti jsou stejně pravděpodobné a výběr je prováděn zcela náhodně.
Program zajišťuje, že výsledky syntézy, tj. generované věty a jejich FU, jsou tištěny přímo v abecední podobě řádkovou tiskárnou počítače. FU se tisknou v bezzávorkové notaci a lze z nich snadno a jednoznačně odvodit strukturní popisy generovaných vět (viz dále v odd. 5). Pracovní rychlost počítače se pohybovala kolem 200 vět během 25—30 min. (i s kompilací programu), délky, struktury a lexikální obsazení generovaných vět byly ovlivňovány fungováním zmíněné procedury „random“.
Program je prakticky univerzální v tom smyslu, že může pracovat s jakoukoli generativní gramatikou, která má stejné formální vlastnosti jako G1 (stejný tvar pravidel v R). Z toho plyne, že programem lze ověřovat jak nekontextové gramatiky různých jazyků, tak i nekontextové popisy jednotlivých jazykových rovin, např. popis roviny syntaktické, roviny významové stavby věty aj., a to opět pro různé jazyky.
Na závěr tohoto oddílu poznamenáváme, že programovací jazyk ALGOL-GENIUS umožňuje pracovat s množinou pravidel přímo v abecedním zápisu [53](viz pravidla 1 v odd. 3.1.) bez jakéhokoli kódování. Stejně tak výsledky jsou získávány přímo v abecední podobě, což v jazyce ALGOL není možno přímo zajistit. Naše zkušenosti s jazykem ALGOL-GENIUS (ačkoli jsme neměli možnost srovnávat s jazyky jako SNOBOL) ukazují, že tento jazyk je velmi vhodný pro programování lingvistických úloh jak logického, tak statistického nebo třídicího typu.
5. Výsledky a ukázky. Pro vyhodnocení výsledků jsme z celkového počtu asi 1300 generovaných vět vybrali vzorek 1178 vět generovaných během června—srpna 1967. Při hodnocení generovaných vět jsme především vycházeli z kritéria syntaktické správnosti vět a nepřihlíželi jsme k jejich smysluplnosti.
Za syntakticky správné byly proto považovány jak věty Umírá, Hlupáci se stříleli, Občan třese vládou morálky, tak i věty Rozvrat stolu miloval, Opakujeme dům smyslu, Bude vyvolávat charakter, který se nezavraždil, které nebudeme patrně považovat za smysluplné. Vět, které pokládáme za syntakticky správné, generoval počítač 775, tj. 64 09 % z celkového počtu 1178 generovaných vět. Mezi částečně syntakticky správné jsme řadili věty se zanedbatelnými (jsme si vědomi relativity tohoto výrazu) gramatickými chybami, např. s nesprávným postavením příklonného se nebo s opakováním stejných adjektiv nebo adverbií. Jsou to věty jako Se poznal dávno hlas za troudem, Pro vítězství nyní stojí nyní lascívní čas. Počítač generoval těchto vět 143, tj. 12,14 %. Za syntakticky nesprávné jsme považovali věty s chybným doplněním (pád objektu neodpovídal vazbě slovesa), věty s chybnými slovesnými reflexívními tvary a věty s celkově chybnou syntaktickou strukturou, např. Tam se umírali cizokrajní lovci, Mechaničtí zaschlí hlupáci vyplývají smíchu smyslu, Nikdy vedle leží poučně vyspělý postoj, Působí, že milenec při kouři bude objímat, líbezný a líbezný milenec. Těchto vět bylo generováno 280, tj. 23,77 % z celého vzorku.
Jsme si dobře vědomi, že termíny syntakticky správná věta, částečně syntakticky správná věta, syntakticky nesprávná věta mají předběžný a relativní charakter, že kritéria pro hodnocení stupně gramatické správnosti českých vět je třeba teprve rozpracovat a provést pokusy s informátory (ve spolupráci s psychology). To by však byl již další samostatný výzkum. Proto jsme se při hodnocení výsledků opírali pouze o své jazykové povědomí a snažili jsme se nepřihlížet k otázkám smysluplnosti vět. Tento postoj má své oprávnění už proto, že v tomto výzkumu se hlavní pozornost věnuje popisu formálně syntaktické stavby české věty a otázce, jak daleko lze v takovém popisu dojít bez širších syntakticko-sémantických úvah. Z našeho hlediska jsou získané výsledky cenné především proto, že každé generované větě je přiřazen FU popisující její strukturu a že na základě rozboru příslušného FU lze celkem bezpečně rozhodnout, zda daná věta je syntakticky správná nebo chybná, i když jazykové povědomí by nás mohlo nechat na pochybách.
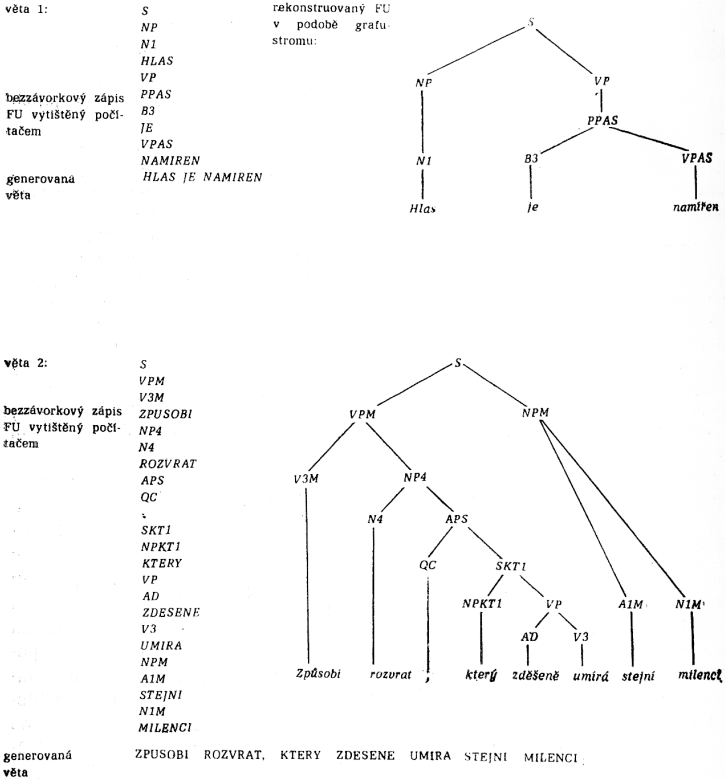
5.1. Ukázky. Aby si čtenář mohl udělat představu o formě výsledků, uvádíme dvě generované věty s příslušnými FU v té podobě, v jaké byly vytištěny řádkovou tiskárnou počítače SAAB D 21.
Poznámka: Ve větě 2 a jejím FU je chyba, kterou čtenář jistě postřehne, chybí druhá čárka. Chyba je způsobena tím, že v G1 je místo pravidla APS → QC SKT1 QC pravidlo APS → QC SKT1.
Pro snadnější porozumění uvádíme vždy vedle FU tištěného v bezzávorkové notaci počítačem ještě ekvivalentní zápis v podobě grafu-stromu. Je jasně vidět, že výsledky v uvedené podobě jsou velmi přehledné a snadno analy[54]zovatelné, a to i u velmi dlouhých vět (počítač generoval i věty o více než 50 slovech).
5.2. Závěry. Přes to, že stupeň empirické adekvátnosti G1 nelze dosud pokládat za příliš vysoký, soudíme, že hlavní vytčené úkoly se nám podařilo
splnit: (1) Zkonstruovali jsme fragmentární generativní gramatiku G1 popisující část českého syntaktického systému a naznačili jsme vztahy mezi tradičním a generativním popisem jazyka. Naše poznatky lze stručně shrnout takto: Co obsahuje tradiční popis, musí být obsaženo i v generativním popisu, generativní popis nadto musí být zcela explicitní a formální, tj. předpokládá podstatně hlubší a detailnější poznání daného (českého) jazykového systému a vyžaduje jej. Z toho ovšem bezprostředně plyne, že generativní popis není, jak se mnozí domnívají, jen nazývání starých pojmů novými termíny, nýbrž tu jsou podstatné metodologické rozdíly v přístupu k popisu jazykových systé[55]mů.[12] — (2) Generativní proceduru pro češtinu jsme naprogramovali pro samočinný počítač a experimentálně ji ověřili, přičemž jsme získali i řadu cenných zkušeností při programování lingvistických úloh logického typu (využití počítačů v lingvistice je ostatně jinde běžnou věcí, a to i v oblastech, kde se jinak pracuje spíše tradičními metodami, na druhé straně si však uvědomujeme, že možnosti v ČSSR jsou velmi omezené).[13]
Naším dalším úkolem bude dále pokusit se o sestavení nespojité gramatiky, která by měla vyšší stupeň empirické adekvátnosti, a uplatnit v průběhu této práce některé poznatky pražské školy týkající se problematiky významové stavby věty[14] a funkční perspektivy větné,[15] popř. i problematiky nadvětných vztahů.[16]
R É S U M É
Random Generation of Czech Sentences
This paper gives the results of writing an incomplete Czech generative grammar and running a computer program which constructs Czech sentences.
The first part (§ 1., 2., 3.) of the paper deals with the used generative grammar, which describe a certain part of the Czech syntax (our attention is concentrated on the syntactic level only but we are well aware of the existing interconnections). We work here with a special type of “discontinuous” generative grammar which is equivalent to the normal context-free grammar and which is defined in the following way: G1 = (VT, VN R, S) where VT is interpreted as a set of terminal symbols, i. e. in our case — vocabulary of the Czech words. Set VT is finite and it contains 322 words, i. e. 83 nouns, 52 finite verbs, 38 participles, 18 infinitives, 73 adjectives, 29 adverbs, 2 pronouns, 15 prepositionals, 10 conjuctions, 2 interrogative words.
VN is interpreted as a set of nonterminal symbols, i. e. a set of the syntactic categories which are defined for the description of a part of the syntax of Czech. — R is interpreted as a finite set of context-free rules in the form S → VP NP, NP → N1, and discontinuous rules VP → AD … V3. — S is designated initial symbol with which the derivation of every generated sentence begins.
From the linguistic point of view the most interesting is the set VN, i. e. set of the syntactic categories which to a certain degree represent the formalization of the traditional syntactic categories, as e. g. subject, predicate, object, adverbial modifier, but also contains a number of categories that do not exist in the traditional syntax. Grammar G1 at present allows to describe incompletely the structure of the simple sentence and some types compound and complex sentences (subordinate clauses and coordinate sentences). In the grammar G1 we are trying to solve some special problems of the Czech syntax concerned also with semantics, e. g. semantic syntactical classification of verbs, problem of verb government.
In the second part (§ 4.) of this paper there is a brief description of the computer [56]program that combined with the mentioned grammar G1 synthesizes Czech sentences. The program is based on the algorithm which is, strictly speaking, coincident with the algorithm of V. H. Yngve. The program is written in the programming language ALGOL-GENIUS.
Program has been run by the computer SAAB D 21 with very satisfying results: from June to August 1967 there were generated about 1 300 Czech sentences. Out of all the obtained sentences there has been chosen a sample containing 1 178 sentences out of which we consider 64.09 % as grammatical and 35.91 % as imgrammatical (but we do not take into account semantic deviations).
[1] Souhrnný přehled a rozbor těchto námitek je podán u P. Sgalla Generativní popis jazyka a česká deklinace, Praha 1967, 24—27, jinak viz N. Chomsky, Syntactic Structures, s’Gravenhage 1957 (čes. překlad, Praha 1966, 35—48).
[2] Přehlednou charakteristiku starší podoby transformačních gramatik podává u nás B. Palek, Informace o transformační gramatice, SaS 25, 1964, 274—282, informaci o novější podobě najde u nás čtenář v článku P. M. Postala Nový vývoj transformační gramatiky, SaS 25, 1965, 1—13.
[3] Viz N. Chomsky, Introduction to the Formal Analysis of Natural Languages, Handbook of Mathematical Psychology II, ed. Luce, Galanter, Bush, New York 1963, 285, srov. též rec. P. Novák - K. Pala - M. Sedláková, SaS 27, 1966, 71—81.
[4] N. Chomsky, Aspects of the Theory of Syntax, MIT 1965, s. 63n.
[5] Viz G. H. Matthews, Discontinuity and Asymmetry in Phrase-Structure Grammars, Information and Control 6, 1963, 137—146.
[6] Srov. E. Bach, An Introduction to Transformational Grammars, New York, 1964, 50n.
[7] Opírali jsme se o tyto gramatiky: B. Havránek — A. Jedlička, Česká mluvnice, Praha 21963; V. Šmilauer, Novočeská skladba, Praha 21966; J. Bauer — M. Grepl, Skladba spisovné češtiny, Praha 1966 (skriptum).
[8] V čl. Automatická syntaktická analýza českého textu bude otištěno v čas. Kybernetika (1968).
[9] V. H. Yngve, A Model and an Hypothesis for Language Structure, Proceedings of the American Philosophical Society, vol. 104, 1960, 444—466; Random Generation of English Sentences, Teddington, Middlesex, England, paper 6, 1961. Srov. též pro ruštinu N. G. Arsenťjeva, O sinteze předloženij russkogo jazyka pri pomošči mašiny Problemy kibernetiki 10, 1963, 227—240; O dvuch sposobach poroždenija předloženij russkogo jazyka, ib. 14, 1965, 189—218; poznamenáváme však, že články o syntéze ruských vět neobsahují popis algoritmu syntézy.
[10] S. R. Ginsburg, Mathematical Theory of Context free Languages, New York 1966; též S. Kuno, Computer Analysis of Natural Languages, Proceedings of the Symposium on Mathem. Aspects of Computer Science, April 5—7, New York 1966, 6n.
[11] Program v jazyce ALGOL-GENIUS napsala a ověřila pracovnice Laboratoře počítacích strojů VUT v Brně B. Kyliánová. Děkuji jí za obětavou pomoc a vedení LPS VUT za poskytnutí strojového času na počítači SAAB D 21.
[12] Viz např. u N. Chomského, o. c. v pozn. 4, s. 3—62.
[13] Máme zde na mysli využití počítačů např. v oblasti sestavování konkordancí a slovníků, srov. např. SaS 28, 1967, 329—332.
[14] Vycházím z čl. M. Dokulila - F. Daneše K tzv. významové a mluvnické stavbě věty, sb. O věd. poznání soudobých jazyků, Praha 1958, 231—246; o této dvojí stavbě v. i B. Havránek, Slavie 22, 1953, 248n. aj., v. i P. Sgall, o. c. v pozn. 1, s. 68—74.
[15] Návrh v tomto směru podává P. Sgall, Functional Sentence Perspective in a Generative Description, Prague Studies in Mathematical Linguistics 2, Praha 1967, 203 až 225; též stručně: Generativní popis jazyka a česká deklinace, Praha 1967, 64n.
[16] B. Palek, Cross-Reference: A Contribution to Hyper-Syntax, TEP III, 1968 (v tisku).
Slovo a slovesnost, volume 29 (1968), number 1, pp. 45-56
Previous Dana Konečná: K rekurzívnímu pravidlu v popisu přirozeného jazyka
Next Marie Ludvíková: Kombinatorika českých fonémů z kvantitativního hlediska
© 2011 – HTML 4.01 – CSS 2.1