
Nový vývoj teorie transformační gramatiky
Paul M. Postal
[Články]
Новейшее развитие теории трансформационной грамматики / Le développement nouveau de la théorie de la grammaire transformative
[*]I. Úvod. Teorie transformační gramatiky, vypracovaná začátkem padesátých let zejména N. Chomským na základě některých zárodečných myšlenek Z. S. Harrise, prochází v posledních letech význačnými změnami.[1] Některé z nich jsou motivovány výhradně vnitřními syntaktickými úvahami, některé úvahami souvisícími s vývojem generativního rámce pro sémantický popis[2] a několik vyplývá i z úvah týkajících se formy fonologického popisu.
Dřívější teorii transformační gramatiky nejlépe ilustrují díla toho druhu jako Chomského Syntactic Structures a Leesova Grammar of English Nominalizations.[3] Předpokládám, že čtenář je s tímto přístupem v základě obeznámen.[3a] Pokusím se tu stručně naznačit některé ze změn, které jsou v této teorii navrženy, i některé jejich motivy a zdůvodnění. V článku tohoto typu musí být přirozeně výklad těchto věcí omezen. Úplnější výklad najde čtenář v literatuře uvedené v poznámkách.
V dřívější podobě transformační teorie byl lingvistický popis pojímán jako popis mající dvě základní části, syntax a fonologii. Nezahrnoval systematický popis sémantické stránky, třebaže bylo znovu a znovu zdůrazňováno, že zevrubné syntaktické analýzy, jaké dovolují právě transformační pravidla, umožňují nahlédnout hluboko do sémantických otázek. Syntax sama měla v tomto pojetí dvě dílčí složky, složku frázovou, skládající se z konečného počtu jednoduchých přepisovacích (rewrite) neboli rozvíjejících [2](expansion) pravidel tvaru A → Z v X — Y, kde A je jednotlivý symbol a Z je nulový řetěz odlišný od A, a dále složku transformační. Frázová pravidla (phrase structure rules) generovala konečnou množinu ohodnocených uzávorkování (labelled bracketing) nebo ohodnocených stromů (labelled tree), označovaných jako základové frázové ukazatele (underlying phrase marker). O rekurzívní neboli neomezené síle gramatiky, o tom aspektu, který vysvětloval nekonečné vlastnosti jazyka, se říkalo, že leží v transformační části syntaxe, zvl. v těch transformacích, které byly nazývány generalizované. Ty se dále dělily na dva typy, zapouštěcí (embedding) transformace a spojovací (conjoining) transformace. Zapouštěcí transformace kombinovaly dva frázové ukazatele zapuštěním jednoho (nebo jeho části) do druhého, tvoříce vztažné fráze, komplementové[*] fráze atd. Spojovací transformace kombinovaly frázové ukazatele tak, že je sřetězovaly (string together), aniž podřizovaly jeden druhému, a vysvětlovaly různé druhy koordinačních vazeb. Jednoduché neboli singulární transformace zobrazovaly jednotlivé frázové ukazatele do nových odvozených frázových ukazatelů. Transformace mohly prvky přidávat, škrtat, permutovat a nahrazovat. Výsledkem provedení poslední transformace při odvozování každé věty je její maximálně povrchový frázový ukazatel, označovaný jako konečný frázový ukazatel (final derived phrase marker), který vysvětluje povrchové vztahy mezi složkami, uplatňující se v konkrétním řetězu slov, z nichž se věta skládá. Tento nejpovrchovější aspekt syntaktické struktury byl chápán jako vstup do fonologické složky lingvistického popisu, jejíž pravidla poskytovala fonetickou interpretaci, tj. množinu fonetických reprezentací pro každou takovou strukturu.
II. Vyloučení transformačních ukazatelů (transformational marker) a generalizovaných transformací. Třebaže teorie transformační gramatiky ve své dřívější podobě nezahrnovala systematický popis sémantické stránky, bylo jasné, že by sémantický popis vět založený na této teorii musel být podán v termínech úplné syntaktické analýzy každé věty, zahrnující nejen základové frázové ukazatele vyjmenované frázovými pravidly, ale také posloupnost transformačních operací zahrnutých v derivaci věty, tj. její tzv. transformační historii neboli transformační ukazatel.[4] V této dřívější teorii hrály transformační ukazatele úlohu při sémantické interpretaci jak ve vztahu ke generalizovaným, tak i ve vztahu k singulárním transformacím.
Můžeme to ilustrovat následujícím způsobem. Uvážíme-li anglické věty
(1) the man who is tall likes the man who is short (muž, který je vysoký, má rád muže, který je malý)
(2) the man who is short likes the man who is tall (muž, který je malý, má rád muže, který je vysoký),
shledáme, že jsou založeny na stejných základových frázových ukazatelích neboli jednoduchých větných strukturách (simple sentence structure) (tj. jaderných řetězech (kernel string) podle dřívější, snad zavádějící [3]terminologie), totiž těch, které můžeme naznačit zjednodušeně a schematicky takto:[*]
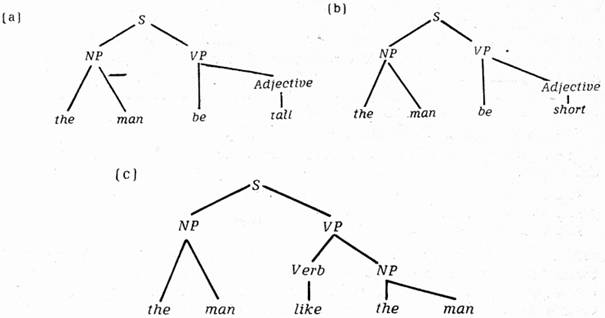
Avšak (1) a (2) zřejmě mají podstatně odlišnou sémantickou interpretaci. To se vysvětlovalo v dřívější teorii pouze po té stránce strukturního popisu vět, která byla dána jejich transformačními ukazateli. V těchto případech by musel transformační ukazatel věty (1) označovat, že frázový ukazatel (a) je zapuštěn jako věta vztažná do první NP ukazatele (c). Transformační ukazatel věty (2) by musel označovat opačné umístění (a) a (b). Je jasné, že potom jakýkoli systematický výklad sémantické stránky vět (1) a (2), a obecně vět tvořených generalizovanými transformacemi (a takových vět je naprostá většina), by se musel dovolávat transformačních ukazatelů těchto vět.
U singulárních transformací vyplývalo zahrnování sémantické interpretace do transformačních ukazatelů z faktu, že věty s podstatně odlišnými významy byly považovány za věty se stejnými základovými (neboli frázovým pravidlem odvozenými) frázovými ukazateli. Proto o větách jako
(3) is John in the house (je Jan v domě)
(4) John is in the house (Jan je v domě)
se říkalo, že mají týž základový frázový ukazatel a že se liší pouze v tom, že první je odvozena užitím tzv. tázací transformace, která způsobuje inverzi subjektové NP a části slovesné fráze obsahující pomocné sloveso. Potom je však jasné, že charakteristika sémantického rozdílu mezi takovými větami by musela odkazovat k transformačním ukazatelům, zvl. k faktu, že tázací transformace se vyskytuje pouze v transformačním ukazateli věty (3).
Transformační ukazatele jsou složité a těžkopádné formální prostředky a způsobily spoustu technických a teoretických problémů, které nikdy nebyly úplně vyřešeny. Bylo proto žádoucí je vyloučit. Toto vyloučení se stalo víc než pouhým přáním, když se ukázalo, že odvolávání na transformač[4]ní ukazatele vyžaduje nesystematické a složité dodatky k teorii sémantické interpretace, kterou by jinak bylo možno zcela zřejmě považovat za jednoduchý kombinatorický systém, pracující se základovými frázovými ukazateli a se slovníkovou neboli lexikální sémantickou informací.[5]
Vyloučení transformačních ukazatelů z lingvistické teorie vede k jejímu zjednodušení a zlepšení. Lze je provést následujícím způsobem. Generalizované transformace se vyloučí a rekurzívní síla se přesune do frázové části gramatiky pomocí dvou různých prostředků. Za prvé kromě vlastních frázových pravidel se připustí jediné frázové schéma neboli zařízení ke generování frázových pravidel, mající tento tvar:
S → (# S #)n, kde n je větší nebo rovno 2.
To pak poskytuje konečnou specifikaci nekonečné množiny frázových pravidel zahrnujících
S → #S# #S#
S → #S# #S# #S#
S → #S# #S# #S# #S#
atd. Tím, že připustí pouze jediné schéma pro koordinaci neboli spojování, teorie tvrdí, že všechny koordinace, i ty, které se jeví jako spojení NP, VP, adjektiv atd., jsou redukovanými podobami větných koordinací, vzniklými vesměs škrtáním opakujících se prvků. Tedy věty jako
(5) John and Bill came (Jan a Bill přišli) a
(6) Mary washed and dried the clothes (Marie prala a sušila šaty)
jsou pokládány za odvozené z vět:
(7) John came and Bill came (Jan přišel a Bill přišel) a
(8) Mary washed the clothes and Mary dried the clothes — — Mary washed and Mary dried the clothes (Marie prala šaty a Marie sušila šaty — — Marie prala a Marie sušila šaty),
a to škrtnutím opakovaného slovesa, resp. opakované NP. Toto odvození škrtáním vysvětluje výběrovou generalizaci, která vede od plných koordinací k redukovaným. Tak např. obecně nalézáme anglickou koordinaci tvaru NP1 + and + NP2 + VPx právě jen tam, kde existují nezávislé věty tvarů NP1 + VPx a NP2 + VPx. Nesetkáváme se tedy s větami jako
(9) *John and the time ate dinner (Jan a čas snědli oběd)
(10) *I shot Bill and the hour (postřelil jsem Billa a hodinu),
protože nemůžeme nalézt věty jako
(11) *the time ate dinner (čas snědl oběd)
(12) *I shot the hour (postřelil jsem hodinu).
Pro jednoduchost výkladu jsem ovšem nebral zřetel na podrobnosti o shodě v čísle. Je pravděpodobné, že odvození všech koordinací škrtáním nebo deformací plných koordinací bude vyžadovat nový princip odvozené struktury složek (derived constituent structure), který vysvětlí ten fakt, že v původních strukturách (7) a (8) máme např. dva uzly NP a dva VP, ale v strukturách odvozených jsou po škrtnutí tyto dvě NP a dvě VP samy připojeny k novým uzlům NP, popř. VP, které v původních strukturách nejsou. Tedy např. pro větu (7) se vychází od této základové neboli hloubkové (deep) struktury
[5]
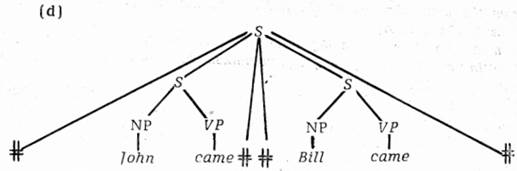
v níž jsou dva uzly NP pro subjektovou NP, totiž ty, které jsou vytištěny antikvou, ale dospívá se k odvozené struktuře jako
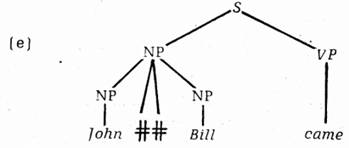
v níž jsou nyní tři uzly na místě subjektu. Zdá se, že princip spočívá zčásti v tom, že struktury hlavních složek tvaru #A# #A# #A… jsou připojeny k novému uzlu A. O tomto novém principu, kterého jsme se zde jen dotkli, musíme však říci mnohem více. Musíme rovněž vysvětlit odstranění nepočátečních (intermediate) uzlů S, ale to je součást obecného problému, jak zrušit řídící (dominating) uzly, jestliže se odstraňují nebo vylučují struktury nižších řádů.[6]
Rovněž zapouštěcí postupy je možno provádět bez generalizovaných transformací. Lze to učinit tak, že se připustí znovuzavedení symbolu S ve frázových pravidlech, a to v různých bodech u hlavních složek, a to právě v těch bodech, v nichž by podle dřívější teorie bylo bývalo vsunutí provedeno generalizovanými transformacemi. Pak můžeme dovolit cyklické opakování (cycling through) prvních n pravidel frázové části gramatiky, kde n-té pravidlo je poslední, které zavádí S. Bylo-li však užito n + 1-ho pravidla, nesmí být užito žádného pravidla j, kde j je menší nebo rovno n. Tak stálým zaváděním nových symbolů S můžeme získávat libovolně složité zapuštěné struktury; je-li stanovena složitost určité struktury, pak se struktura rozvíjí dalšími, necyklickými frázovými pravidly. Tento cyklický postup zavádění S dovoluje, aby na zapuštěné symboly S bylo použito pravidel generovaných koordinačním schématem a dále aby na symboly s koordinací bylo použito zapouštěcích frázových pravidel, takže je dovolena koordinace uvnitř zapouštění a zapouštění uvnitř koordinací, což se prokazatelně vyskytuje:
[6](13) I saw the man who bought the trailer and the car (viděl jsem muže, který koupil přívěsný vůz a auto)
(14) the man who lives in the big house and the woman who lives in the small house are getting married (muž, který žije ve velkém domě, a žena, která žije v malém domě, uzavírají sňatek).
Je třeba poznamenat, že původní argumenty proti popisování zapouštěcích postupů uvnitř frázové struktury spočívaly na závažném faktu, že — obecně — tvoření složené (complex) fráze se zapouštěním je závislé na podmínce totožnosti dvou jednodušších struktur, obvykle nějaké NP nebo jejího hlavního substantiva. Tato podmínka je nezbytná pro vysvětlení faktu, že se nesetkáváme se strukturami jako
(15) *I saw the man who elapsed (the time elapsed) (viděl jsem člověka, který uplynul [čas uplynul])
(16) *I know a woman who teems with life (the city teems with life) (znám ženu, která se hemží životem [město se hemží životem])
atd. na základě neexistence
(17) *the man elapsed (člověk uplynul)
(18) *the woman teems with life (žena se hemží životem) atd.
Ale takové podmínky totožnosti nelze formulovat frázovými pravidly.[7] V dřívější transformační teorii byla tato závažná vlastnost zapouštění s identitou (embedding with identity) řešena tak, že podmínka identity byla ukládána generalizované transformaci (ve výše uvedených případech pravidlo o vztažné frázi), která kombinuje dvojici frázových ukazatelů, a tím vytváří zapouštění. Aby bylo možno kombinovat dvojici frázových ukazatelů pomocí zapouštěcích pravidel, musely by frázové ukazatele obsahovat totožné substantivum. Protože však ve skutečných vztažných frázích atd. se vesměs neopakují totožná substantiva, bylo nutno k popisu zapouštění připojit škrtnutí opakovaného substantiva, a to buď jako součást zapouštěcího pravidla samého nebo jako samostatnou operaci, aby se tak dospělo k skutečným vztažným frázím jako (19) a (20) z takových, jako jsou (21), resp. (22):
(19) the man that I saw (muž, kterého jsem viděl)
(20) the house which burned down (dům, který vyhořel)
(21) *the man that man I saw (muž, kterého muže jsem viděl)
(22) *the house which house burned down (dům, který dům vyhořel)
Přitom však unikalo pozornosti, že tato podmínka škrtat jedno ze dvou totožných substantiv znamená omezení identity u zapouštění nezávisle na tom, že existuje podmínka identity u kombinací frázových ukazatelů samých. Podle nové teorie se tedy mohou zapouštět zcela neomezené kombinace frázových ukazatelů tak, že frázová neboli základová (base) dílčí složka gramatiky generuje velkou třídu nesprávných struktur, které nejsou základem žádných vět. Avšak tím, že máme tutéž singulární transformační operaci pro vyškrtnutí opakovaného totožného substantiva, nesprávné struktury se formálně odliší od správných zapouštěcích struktur, protože u nesprávných struktur nelze užít pravidla škrtnutí. Je možno [7]navrhnout různé formální prostředky, jimiž se označí za odchylné ty zapouštěcí struktury, které nesplňují podmínku identity a v nichž proto nelze opakující se substantiva redukovat na jedno. Takovým způsobem se pak formálně rozlišují struktury jako
(23) *the house which book burned down (dům, který kniha vyhořel)
(24) *the house which house burned down (dům, který dům vyhořel),
které jsou obě generovány frázovými pravidly. Liší se tím, že druhá je základem skutečné vztažné fráze, kdežto první nikoli. Podle této koncepce transformační složka, která nyní obsahuje jen singulární transformační pravidla, dostává novou funkci, totiž filtrací vyřazovat (filter out) ty základové struktury, které nejsou správně tvořeny. Rozhodující význam má to, že se jeví obecně pravdivým, že toto filtrování lze provádět, jako ve výše popsaném případě, pomocí pravidel, která jsou motivována nezávisle, tj. pravidly, která skutečně byla v gramatice starší koncepce. Je tedy vidět, že generalizované zapouštěcí transformace jsou formálně vskutku redundantní.[8]
Na uvedené nové formulaci je nejzávažnější to, že pojem transformačního ukazatele, s nímž byla sémantika nucena kvůli generalizovaným transformacím počítat, je nyní v takových případech vyloučen. To znamená, že rozdíly mezi větami (1) a (2), které podle starší teorie byly dány pouze transformačními ukazateli, jsou nyní dány jednoduše, přímo a intuitivně faktem, že mají tyto různé základové frázové ukazatele, generované základovými neboli frázovými pravidly:
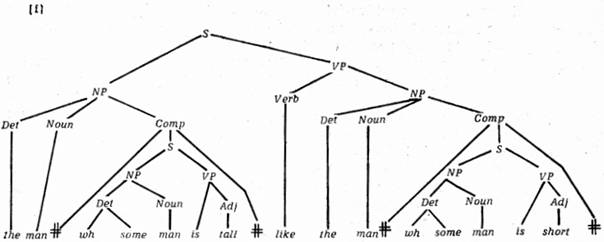
(g) je totéž jako (f), pouze tall a short si vymění místa. Sémantická složka může působit právě na těchto strukturách spolu se sémantickou informací poskytovanou slovníkovými hesly lexikálních jednotek v těchto strukturách. Pro souvětí podřadná pak můžeme zobecnit, že sémantická složka působí na jediném hloubkovém neboli základovém frázovém ukazateli věty.
Zdá se též pravděpodobné, že od užití transformačních ukazatelů se správně upouští u singulárních transformací, jako je tázací pravidlo, popisovaných [8]dříve tak, že se do základových struktur vkládaly morfémy, v tomto případě Q; ty jednak signalizují obligatorní operaci pro to, co bylo dříve pokládáno za fakultativní transformace, jednak i poskytují v základových neboli hloubkových ukazatelích informaci, jež je nezbytná pro sémantickou interpretaci bez užití transformačních ukazatelů. Proto základové frázové ukazatele všech tázacích vět budou obsahovat morfém Q.[9] Patrně tedy platí, že sémantická složka lingvistického popisu se uplatňuje výhradně u jediného hloubkového frázového ukazatele, daného základovými pravidly pro každou větu, a že transformace nehrají přímou úlohu při sémantické interpretaci. Je též pravděpodobné, že se všechny transformace mohou stát obligatorními tím, že ukazatele pro jejich fungování se umístí do základových struktur. Není tak třeba vyjmenovávat každou transformaci a určovat její obligatorní nebo fakultativní charakter, a každý správně tvořený hloubkový frázový ukazatel bude jednoznačně definovat větu, tj. konečný neboli maximálně povrchový frázový ukazatel.
III. Rekonstruovatelné škrtnutí. Dřívější verze transformační gramatiky připouštěly, aby byly odstraňovány prvky z frázových ukazatelů pomocí transformací pro škrtnutí nebo substituci. Avšak tyto způsoby nezaručovaly, že může být znovu zjištěna totožnost odstraněných jednotek, jsou-li dány výstupní (output) frázové ukazatele a popis transformací. Účel, proč vůbec sestavujeme teorie gramatiky nebo jazyka, je specifikovat ty univerzální rysy, které odlišují přirozené jazyky od libovolných možných znakových systémů. Chceme tedy, aby do teorie gramatiky byla pojata nejužší a nejsilnější omezení, protože tak teorie bude vyhovovat nejhlubším a nejvýznamnějším nárokům, vyplývajícím ze zkoumané skutečnosti. Kdykoli to bude možné, dodáme podmínky, které zúží třídu teoreticky možných gramatik tím, že vyloučí jisté typy pravidel atd.
Zdá se však, že v empiricky správných lingvistických popisech se nevyužívá možnosti odstraňovat položky z frázových ukazatelů takovým způsobem, aby je nebylo možno zpětně rekonstruovat, a že proto lze tuto možnost z teorie vyloučit, a tak významně zúžit třídu možných gramatik. Můžeme to ilustrovat několika poznámkami o anglických tázacích větách jako
(25) who did you see (kdo jsi viděl) a
(26) who baked the bread (kdo pekl chléb).
V Chomského Syntactic Structures a v jiných starších transformačních popisech angličtiny byly tyto otázky zčásti odvozovány pravidly, která spojovala morfém wh- s libovolnou NP ve větách a přesouvala ji na začátek jejich frázových ukazatelů. Později byla NP obsahující wh- nahrazena zástupnou formou who (kdo) nebo what (co) podle toho, zda základem bylo životné (osobní) jméno nebo nikoli. Podle toho mohly být věty jako (25) a (26) odvozeny ze struktur tvořících základ vět jako:
(27) you saw John, you saw the man, you saw the farmer who ate the bread, you saw an important individual (viděl jsi Jana, viděl jsi muže, viděl jsi rolníka, který jedl chléb, viděl jsi významnou osobu) atd.
(28) I baked the bread, the communist baked the bread, the fascists baked the bread (pekl jsem chléb, komunista pekl chléb, fašisté pekli chléb) atd.
[9]Jinými slovy, každá z tázacích podob mohla mít nekonečně mnoho různých základových NP a popis tak vlastně predikoval, že každá z nich bude nekonečně mnohoznačná, zatímco ve skutečnosti se pouze zdají nejasné, a mnohoznačnost a nejasnost jsou obvykle zcela odlišné vlastnosti. Kromě toho tvrzení, že nekonečná mnohoznačnost vždy znamená nejasnost, je formulováno ad hoc a není příliš přesvědčivé. Rozhodující je však to, že popis, který dovoluje spojovat wh- s libovolnou NP, je prostě empiricky neadekvátní, protože definuje chybnou třídu tázacích vět. Ve skutečnosti se zdá, že doplňovací otázky jako (25) a (26) mohou být utvořeny pouze spojováním wh- s určujícím some, které předchází před neurčitými zástupnými formami one, thing atd. Všimněme si proto, že v následujících případech, kde jsou otázky tvořeny chybně, jsou odpovídající neurčité zástupné formy oznamovací tvořeny rovněž chybně, i když odvození z libovolné NP by přípustnost těchto nesprávně tvořených otázek predikovalo:[*]
| (29) | a) he behaved toward John with great kindness (choval se k Janovi s velkou laskavostí) b) *he behaved toward John with something (choval se k Janovi s něčím) c) *what did he behaved toward John with (s čím se choval k Janovi) |
| (30) | a) John behaves himself (Jan se slušně chová) b) *John behaves someone (Jan někoho slušně chová) c) *who does John behave (koho Jan slušně chová) |
| (31) | a) I saw myself (viděl jsem se) b) *someone saw myself (někdo viděl mne) c) *who saw myself (kdo viděl mne) |
| (32) | a) that John came is a fact (je fakt, že Jan přišel) b) *that John came is something (je něco, že Jan přišel) c) *what it is that John came (co je to, že Jan přišel) |
| (33) | a) it is raining (prší) b) *something is raining (něco prší) c) *what is raining (co prší) |
| (34) | a) it seems that John is here (zdá se, že Jan je zde) b) *something seems that John is here (něco se zdá, že Jan je zde) c) *what seems that John is here (co se zdá, že Jan je zde). |
U tohoto druhu případů a u mnoha dalších, které lze nalézt a v nichž je wh spojeno s libovolnou NP, v nichž jde o popis angličtiny s vynecháním prvků, jež nelze zpětně rekonstruovat, je predikována nesprávná třída tázacích vět, kdežto spojení wh s neurčitými zástupnými formami someone (někdo) a something (něco) predikují, jak je patrno, z velké části správnou třídu. Čistě empirické úvahy nás proto nutí zvolit popis, který je v mezích vynechání rekonstruovatelného. Na hlubší rovině můžeme tento fakt vysvětlit, jestliže uložíme obecné teorii gramatiky to omezení, aby škrtnutí (a vynechání vůbec) byla rekonstruovatelná.
Zdá se, že můžeme rozlišit tři různé případy, v nichž lze vypustit jednotky z frázových ukazatelů. Za prvé mohou být vypuštěny posloupnosti jednotek, jsou-li nutně totožné s jinými posloupnostmi v témž frázovém ukazateli. Sem patří případy zdvojených substantivních složek v zapuštěných frázích (srov. věty [19]—[20] výše), o kterých bylo již pojednáno. Za druhé, mohou být [10]jednotky vypuštěny, jsou-li to určené nebo vyznačené členy kategorií, tj. zástupné formy. Sem patří právě probrané tvary otázek. Je důležité rozlišovat tázací who a who ve vztažných frázích. První who nebylo odvozeno z identity, a musí mít tedy původ v jediné vyznačené zástupné formě. Druhé who bylo odvozeno z identity, a může mít tedy nekonečný počet základových forem, protože jsou rekonstruovatelné. Konečně mohou být posloupnosti morfémů vypuštěny z frázových ukazatelů, jestliže transformace, která je sama vypouští, se o nich výslovně zmiňuje. Tak např. imperativní transformace v angličtině vypouští zájmeno druhé osoby you (ty, vy), modální will atd. a dospívá k větám jako
(35) drink the milk (pij to mléko)
ze základového řetězu morfémů imperativ + you + prézens + will + drink + the + milk. Avšak ve vymezení oboru imperativní transformace se explicitně uvádí vypuštěný řetěz.
Princip rekonstruovatelného škrtnutí daný třemi výše uvedenými podmínkami se rovná univerzální přednostní podmínce, jíž musí vyhovovat definice transformačních oborů. Jedním jejím výsledkem je důležité omezení generativní síly[*] transformačních gramatik, tj. tříd morfémových řetězů, které jimi mohou být generovány. Transformační gramatiky splňující tuto podmínku generují pouze množiny, které se odborně nazývají rekurzívní, tj. takové, pro které existuje rozhodovací postup (decision procedure) pro zjištění větnosti, tj. konečný postup, který může pro libovolný řetěz stanovit, zda je nebo není větou.[10]
IV. Výběry, křížící se třídění (cross-classification) a syntaktické rysy (syntactic features). V dřívější teorii transformační gramatiky se předpokládalo, že pomocí frázových kontextových pravidel mohou být stanovena tzv. výběrová omezení (selectional restrictions). Výběrovými omezeními rozumíme omezení taková, že např. některá slovesa se pojí pouze se životnými subjekty, jiná s osobními subjekty, počitatelnými nebo látkovými subjekty, jiná pouze s osobními objekty, jiná se nepojí s adverbii místa, jiná s adverbii způsobu atd. Uznání faktu, že frázová kontextová pravidla nemohou adekvátně charakterizovat všechny druhy výběrových omezení, jež existují v přirozených jazycích, znamená v teorii transformační gramatiky význačnou změnu, jejíž důležitost a význam je nemenší než vyloučení generalizovaných transformací a transformačních ukazatelů. Bohužel důkaz tohoto faktu i vylíčení, jakého druhu je lingvistický aparát, který je s to pustit se do přiměřeného zpracovávání daných faktů, jsou tak spletité a složité a do jisté míry ještě zdaleka ne dost vypracované, že ve stručném článku tohoto druhu nemůžeme důkladně probrat žádnou z těchto otázek.[11]
Můžeme však problém stručně naznačit a formulovat bez velkého dokazování některé modifikace, jež jsou patrně nezbytné, aby se odstranily potíže v dřívější teorii. Základní problém vzniká z faktu, že vlastnosti, pro něž musí být formulovány výběrové vztahy, se překrývají (overlap) nebo že se kříží při třídění. Tak substantiva musí být charakterizována se zřetelem na vlast[11]nost životnosti, která hraje důležitou úlohu při výběru slovesa, i se zřetelem k takovým vlastnostem, jako jsou singulár a počitatelnost. Potíž je v tom, že tyto vlastnosti se značně překrývají, takže frázová pravidla se neúměrně množí a relevantní kategorie nelze jednotně vyjádřit. Uvažme např. pokus rozdělit substantivum do kategorií podle výše uvedených vlastností podle frázových pravidel. První pravidlo by mohlo být
|
substantivum → |
| životné substantivum
neživotné substantivum |
|
což říká, že existují dvě různé, vzájemně se vylučující možnosti, jak rozvíjet kategorie substantiva. Až potud je to správné. Nyní však uvažme další rozvíjení, a to singulár proti plurálu. Toto rozvíjení budeme muset uvést dvakrát, neboť ve frázových termínech jsou životné substantivum a neživotné substantivum zcela odlišné kategorie, které spolu nemají nic společného. Příští dělení do kategorií musí být tedy uvedeno redundantně takto:
|
životné substantivum → |
| životné substantivum v singuláru
životné substantivum v plurálu |
|
|
neživotné substantivum → |
| neživotné substantivum v singuláru
neživotné substantivum v plurálu |
|
A další dělení do kategorií bude nutno provést čtyřikrát, další osmkrát atd. Všimněme si — a to je věc ještě horší —, že tu nedostáváme správné jednotné dělení do kategorií, takže abychom mohli mluvit o substantivech v jednotném čísle, bude nutno se zmínit alespoň o dvou kategoriích, o singuláru neživotném a singuláru životném (a vlastně o daleko větším počtu, je-li dáno další dělení do kategorií) a stejně tak u dalších vlastností. Je jasné, že i v těchto maximálně jednoduchých případech jsou frázová pravidla neadekvátní pro stanovení přesahu při dělení do lexikálních kategorií. A situace, která je zlá v těchto případech, se stává zcela neuhajitelnou, uvážíme-li kategorie, jako je sloveso, jehož dělení do subkategorií není nekontextové, jako je tomu v případě substantiv, ale je omezeno se zřetelem na subjekty, objekty, adverbia atd. Redundance v popisu prováděném frázovými pravidly a nedostatek jednotné charakteristiky relevantních kategorií vedou k fantasticky neadekvátním popisům.
Řešení navržené Chomským záleží v tom, že se vzdáváme omezení, podle něhož symboly syntaktické složky jsou atomické neboli nerozložitelné, a připustíme na koncové (terminal) rovině reprezentanty syntaktických entit vyjádřené analogicky jako ve fonologii. Jestliže to připustíme a oddělíme slovník od rozvíjecích pravidel, můžeme začít adekvátně popisovat výběrová omezení. Slovník potom považujeme za množinu složených hesel takových, že každé heslo je souborem trojích rysů, syntaktických, fonologických a sémantických. Za konečný krok v odvození základových neboli hloubkových frázových ukazatelů se potom pokládá výběr příslušných slovníkových hesel a jejich uložení do neúplných hloubkových struktur. Výběrová omezení mezi kontextovými jednotkami, jako jsou slovesa, a jinými prvky, jako jsou subjekty, příslovce atd., se vysvětlují tak, že se slovesům přiřadí syntaktické rysy označující okolí, v nichž mohou stát bez násilností. Na problém dělení do přesahujících kategorií se tedy útočí tím, že se připouští existence syntaktické jednotky, jež se skládá z množiny nezávislých syntaktických vlastností.
V. Závěr. Můžeme uzavřít pozorováním, že z posledních prací v trans[12]formační teorii generativní gramatiky vzniká následující obraz lingvistického popisu. Lingvistický popis má tři hlavní složky, syntaktickou, sémantickou a fonologickou. Syntaktická složka sama má dvě hlavní dílčí složky. První složka neboli základ (base) se skládá z nekontextové frázové podčásti s rekurzí, která umožňuje cyklicky opakovat pravidla zavádějící a rozvíjející symbol S. Základ rovněž obsahuje množinu pravidel o rysech (feature rules), která umožňují vyjádřit některé kategorie složek v termínech syntaktických rysů, a slovník, který obsahuje morfémy, uvažované jako složité trojice syntaktických, sémantických a fonologických vlastností.[12] Generování hloubkových neboli základových frázových ukazatelů se dotváří tím, že některé množiny rysů, generované základovými pravidly o rysech, se nahradí slovníkovými hesly. Hloubkové frázové ukazatele generované základovou složkou (bází) tak, že pro každou větu je generován jeden, tvoří vstup do sémantické složky, jejímiž pravidly je každá složka hloubkového frázového ukazatele sémanticky interpretována.[13] Hloubkové frázové ukazatele tvoří rovněž vstup do transformační dílčí složky syntaxe, jejíž pravidla postupně odvozují čím dále povrchovější frázové ukazatele tak dlouho, dokud není generován poslední neboli konečný frázový ukazatel. Transformační složka obsahuje pouze singulární transformace a navíc má nyní přídatnou funkci vyřazovat filtrací ty hloubkové frázové ukazatele, generované základovou částí syntaxe, které nejsou správně tvořeny. Konečné frázové ukazatele produkované transformační dílčí složkou tvoří vstup do fonologické složky, jejíž pravidla udělují každému takovému objektu množinu fonetických interpretací, a to ve formě fonetické reprezentace vyjádřené univerzální abecedou fonetických rysů. Celkový lingvistický popis tak generuje nekonečnou třídu abstraktních objektů, skládajících se z trojic syntaktických, sémantických a fonologických vlastností. Na lingvistický popis je tak možno nahlížet jako na zařízení, které sdružuje sémantické interpretace s interpretacemi fonetickými tím, že obsahuje jednu rekurzívní neboli produktivní složku, syntax, která generuje nekonečnou třídu složitých syntaktických objektů, plus dvě interpretační složky, z nichž jedna udílí každé syntaktické struktuře sémantickou interpretaci a druhá jí poskytuje interpretaci fonetickou. Současná teorie transformační gramatiky však předkládá závažné empirické tvrzení, že tou stránkou syntaktické struktury, která je relevantní pro sémantickou interpretaci, je hloubkový frázový ukazatel generovaný samotným základem, zatímco stránkou relevantní pro fonetickou interpretaci je konečný frázový ukazatel generovaný činností transformační složky. Základní funkci této druhé složky tedy vidíme v zobrazování objektů pro poznání význačných, totiž hloubkových frázových ukazatelů, do jiných objektů, konečných frázových ukazatelů, které jsou slučitelnější s omezeními paměti, percepce, vynaložení energie atd. [13]u člověka, a proto vhodnější pro akustické zakódování a dekódování. Je pozoruhodné, že vzhledem k hloubkovým frázovým ukazatelům směřují konečné frázové ukazatele k větší jednoduchosti, krátkosti a menší strukturní složitosti.
(Z anglického originálu přeložila Ludmila Uhlířová)
R é s u m é
DEVELOPMENTS IN THE THEORY OF TRANSFORMATIONAL GRAMMAR
A linguistic description has three major components, syntactic, semantic, and phonological. The syntactic component itself has two major subcomponents.
The first or base consists of a context free phrase subpart with recursion handled by cycling through the rules which introduce and develop the symbol S. The base also contains a set of feature rules which provide a syntactic feature representation for some of the constituent categories and a dictionary which contains morphemes, considered to be complex triples of syntactic, semantic, and phonological properties. The generation of deep or underlying phrase markers is completed by substituting dictionary entries for some of the feature sets generated by the feature rules of the base.
The deep phrase markers generated by the base, one for each sentence, are the input to the semantic component whose rules provide each constituent of the deep phrase marker with a semantic interpretation. The deep phrase markers are also input to the transformational subcomponent of the syntax whose rules succesively derive more and more superficial phrase markers until the last or final derived phrase marker is generated. The transformational component contains only singulary transformations and now has the additional function of filtering out those deep phrase markers generated by the base part of the syntax which are not well formed.
The final derived phrase markers produced by the transformational subcomponent are the input to the phonological component whose rules provide each such object with a set of phonetic interpretations in the form of phonetic representation in terms of a universal alphabet of phonetic features.
The total linguistic description thus generates an infinite class of abstract objects consisting of triples of syntactic, semantic, and phonological properties. The linguistic description can thus be looked upon as a device which associates semantic interpretations with phonetic interpretations by containing one recursive or productive component, the syntax, which generates an infinite class of complex syntactic objects, plus two interpretative components one of which provides each syntactic structure with a semantic interpretation, the other of which provides each with a phonetic interpretation. The present theory of transformational grammar makes, however, the crucial empirical claim that that aspect of syntactic structure relevant to semantic interpretation is the deep phrase marker generated by the base alone, while that aspect relevant to phonetic interpretation is the final derived phrase marker generated by the operation of the transformational component.
[*] Z katedry moderních jazyků a Výzkumné laboratoře elektroniky Massachusettské vysoké školy technické, Cambridge, Massachusetts, USA.
[1] Tato práce vznikla zčásti za podpory institucí U.S. Army, U.S. Air Force Office for Scientific Research a Office for Naval Research, a zčásti za podpory National Science Foundation.
[2] Srov. J. Katz a J. A. Fodor, The Structure of a Semantic Theory, Language 39, 1963, 170—211; J. Katz a P. M. Postal, An Integrated Theory of Linguistic Descriptions, MIT Press, Cambridge, Massachusetts 1964.
[3] Srov. též N. Chomsky, On the Notion Rule of Grammar, Structure of Language and its Mathematical Aspects, Proceedings of the 12th Symposium in Applied Mathematics, ed. R. Jakobson, Providence, Rhode Island 1961; A Transformational Approach to Syntax, Proceedings of the Third Texas Conference on Problems of Linguistic Analysis in English, ed. A. A. Hill, Austin, Texas 1962.
[3a] Pro uvedení do transformační gramatiky viz B. Palek, Informace o transformační gramatice, SaS 24, 1963, 140—151. Pozn. překl.
[*] Komplementový je termín zahrnující všechny možné členy rozvíjející přísudkové sloveso (O, Ad, Atv atd.). Pozn. překl.
[4] Podrobný výklad o transformačních ukazatelích viz u Katze a Postala, o. cit. v pozn. 2.
[*] S = sentence, věta; NP = noun phrase, substantivní fráze; VP = verbal phrase, slovesná fráze. Pozn. překl.
[5] Srov. Katz a Postal, o. cit. v pozn. 2 a N. Chomsky, Some Aspects of the Theory of Syntax, vyjde v MIT Press 1964.
[6] Předpokládám zde ovšem, že koordinační ukazatele jako and, které se objevují na konečném výstupu, jsou prostě transtormační deriváty z dvojice větných hranic, které označují koordinaci.
[7] Ukazuje se nyní, že základový komponent syntaxe je zcela nekontextový a že všechna kontextová omezení jsou pojata do transformací a do syntaktických rysů. Srov. výklad dále uvedený a Chomského Some Aspects, cit. v pozn. 5. Z formálního hlediska je to velká výhoda, protože pojem kontextových frázových pravidel, nyní vypuštěný, s sebou nese řadu technických potíží. Výklad o tom viz u Postala Constituent Structure, Publication Thirty of the Indiana University Research Center in Anthropology, Folklore and Linguistics, Bloomington, Indiana, 1964, zejm. kap. 3.
[8] Protože frázová pravidla produkovaná koordinačním schématem odvozují větné koordinace zcela volně a bez omezení, bude též nutno mít vyřazovací (filtering) transformace, které by vyznačily nesprávně tvořené koordinace odvozené základovým komponentem, jako *go home and I came (jdi domů a přišel jsem).
[9] Nejde prostě o to, že se můžeme rozhodnout umístit ukazatele jako např. Q do základových struktur, ale spíše o to, že na dosud probraných případech můžeme ukázat, že učiníme-li tak, dostaneme i z jiných důvodů nejlepší syntaktický popis. Srov. výklad u Katze a Postala, o. cit. v pozn. 2.
[*] Některým anglickým nesprávně tvořeným větám při „doslovném“ překladu odpovídají české věty správně tvořené (např. 31 b, c a 32 e). Pozn. překl.
[*] Termínu weak generative power odpovídá v češtině termín generativní síla, termínu strong generative power termín explikativní síla. Pozn. překl.
[10] Srov. k tomu u H. Putnama Some Issues in the Theory of Grammar, Structure of Language and its Mathematical Aspects, 1961.
[11] Tyto věci naštěstí velmi podrobně vyložil Chomsky v knize Some Aspects, cit. v pozn. 2.
[12] I když pojmové rozdělení lingvistického popisu do tří složek je přirozené a sleduje několik jasných a formálně ohraničených předělů (break) v lingvistickém aparátu, bylo by možné a podnětné i jiné dělení. Mohli bychom rozlišovat základovou část syntaxe a sémantickou složku jako jednu základovou neboli poznávací složku, jez se zabývá generováním a sémantickou interpretací struktur s poznávacím dosahem. A pak bychom mohli pohlížet na transformační část syntaxe spolu s fonologií jako na jediný výstup (print out) neboli povrchovou strukturní složku, jejímž úkolem je programovat hloubkové a pro poznání význačné objekty do objektů slučitelnějších s fyzickými, percepčními a paměťovými omezeními na člověka.
[13] O popisech sémantických pravidel, sémantické interpretaci atd. viz Katz a Fodor, o. cit. v pozn. 2, Katz a Postal, o. cit. v pozn. 2.
Slovo a slovesnost, ročník 26 (1965), číslo 1, s. 1-13
Předchozí František V. Mareš: Souborné indexy slavistických časopisů
Následující Helena Křížková: Pojetí neutralizace v morfologii
© 2011 – HTML 4.01 – CSS 2.1