
Větné faktory a jejich podíl na analýze věty II
Ladislav Nebeský
[Články]
Sentence factors and their role in sentence analysis
[*]Věnováno Pavlu Novákovi k jeho 70. narozeninám
1. V tomto příspěvku se vracím k společné stati s P. Novákem (1996), jež se týkala větného rozboru.[1] Kladli jsme si v ní za cíl položit mezi větu a její rozbor dílčí stadia, a to taková, která závisí na nějakém uceleném souboru faktů, jenž v obvyklé podobě psané věty dokážeme „zablokovat“ (dále bez uvozovek). Takový soubor faktů jsme nazvali větným faktorem. Zaměřili jsme se na tři větné faktory: slovosled, flektivní realizaci a lexikální realizaci věty. Flektivní realizací věty jsme rozuměli konkrétní výběr slovního tvaru ze všech slovních tvarů téhož lexému, a to pro každý lexém věty. Lexikální realizací konkrétní výběr lexému z těch všech lexémů, které patří k témuž vzoru deklinace nebo konjugace, a to pro každý ohebný lexém věty.
Slovosled ve větě (tedy v její obvyklé psané podobě) jsme zablokovali tak, že jsme slovní tvary věty uspořádali abecedně.[2] Flektivní realizaci věty jsme zablokovali tak, že každý slovní tvar jsme nahradili obvyklou podobou lexikálního hesla, k němuž patří. Lexikální realizaci věty jsme zablokovali tak, že každý tvar ohýbaného slova jsme nahradili odpovídajícím tvarem vzorového slova deklinace nebo konjugace (a ostatní tvary nechali beze změny). Uvažovali jsme i o současném zablokování dvou (nebo tří) větných faktorů. Větu se zablokovaným faktorem jsme přitom zapisovali tak, aby to, který faktor je zablokován, bylo zřejmé.[3]
V naší stati jsme si položili otázku, jak se různé faktory věty podílejí (či naopak nepodílejí) na konečném výsledku jejího syntaktického rozboru. Představme si, že lingvista Z provádí rozbory vět podle předem zvoleného syntaktického přístupu. Předpokládejme, že se rozhodl provést rozbor nějaké věty V; při jeho uskutečnění se může opírat nejen o znalost zvoleného přístupu větného rozboru, ale o souhrn všech svých poznatků o jazyce, tedy o něco, čím disponuje ještě dříve, než k rozboru vět V přikročil. Zvolme některý z tří uvažovaných větných faktorů, řekněme faktor F, a sledujme jeho podíl na výsledném rozboru věty V, k němuž lingvista Z dospěje. Je možné, že k provedení rozboru věty V faktor F vůbec potřebovat nebude. Pokud však ano, nemusí to znamenat, že ho bude potřebovat během celého procesu rozebírání věty V. Proto si lze klást otázku, pro jak nejmenší část procesu rozebírání věty V je přihlédnutí k faktoru F nezbytné. Jinak řečeno, lze se ptát po tom nejranějším stadiu Smin v procesu rozebírání věty V, o němž platí, že až po toto stadium lingvista Z k faktoru F přihlížet potřebuje, avšak počínaje tímto stadiem může již od faktoru F odhlédnout, a přesto rozbor věty V bezchybně dokončit.
[99]Vědomi si rozdílu mezi odhodláním od něčeho odhlédnout a schopností to opravdu učinit, popsali jsme myšlený pokus, v němž lingvistu Z nahrazují osoby dvě – A a B; obě zvolený syntaktický přístup spolehlivě ovládají. Osoba A rozebírá větu V jen po určité stadium. Poté, co je v tomto stadiu faktor F zablokován, snaží se osoba B rozbor dokončit. Při vhodné organizaci pokusu může být hledané stadium Smin objeveno.[4]
K demonstrování našich myšlenek nám posloužil především jeden závislostní přístup syntaktické analýzy. Popisu tohoto přístupu i způsobu, jak jeho výsledek zaznamenáváme, jsme v naší stati věnovali poměrně značný prostor. V jejím závěru jsme potom vyslovili přesvědčení, že smysluplnost naší otázky po podílu jednotlivých větných faktorů na výsledném rozboru věty by nemusela ohrozit ani volba jiného přístupu syntaktické analýzy, ani jiné vymezení větných faktorů. Dodávám, že toto přesvědčení jsem si uchoval.
K tématu stati, jejíž některé myšlenky jsem právě zpřítomnil, se nevracím poprvé. Týmž tématem jsem se zabýval i ve svém článku (1997) a s omezením na jediný faktor – totiž na slovosled – i v (2002). S využitím některých myšlenek z článků (1997) a (2002) na společnou stať s P. Novákem (1996) naváži. Z dvou spoluautorů původní stati jsem tím, který má mnohem blíže k formálním stránkám tématu; to ráz následujících poznámek zřetelně předurčuje.
2.1. Tážeme-li se, jak se různé faktory věty podílejí (či naopak nepodílejí) na konečném výsledku jejího syntaktického rozboru, vyslovujeme vlastně jen náčrt otázky, který je třeba zpřesnit. V společné stati s P. Novákem (1996) jsme jako pomůcku k takovému zpřesnění zvolili myšlený pokus, o němž jsem se zmínil v odd. 1. Jinou pomůcku jsem zvolil v článcích (1997) a (2002); k ní se nyní obrátím. Stejně jako v (1996) šlo v mých článcích (1997) a (2002) o české věty, které byly gramaticky správné a zároveň smysluplné. Avšak zatímco v (1966) jsme využili především jeden závislostní přístup syntaktické analýzy českých vět, v (1997) a (2002) jsem se omezil na přístup složkový; složky, do nichž se analyzované věty rozkládaly, byly neoznačené.
Začnu faktorem, s nímž se z formálního hlediska pracuje nejobtížněji: se slovosledem.[5] To, co zůstane, je-li ve větě zablokován slovosled, nazvu její bezslovoslednou podobou. Bezslovoslednou podobu věty lze zpřístupnit jejím záznamem. Mohla by jím být jakákoli změna uspořádání slovních tvarů ve větě, která by byla opatřena sdělením „uspořádání slovních tvarů nemusí odpovídat slovosledu“; takové sdělení by ovšem mohlo být vyjádřeno dohodnutým symbolem. Je výhodné, když záznam, který zpřístupňuje bezslovoslednou podobu věty, je výsledkem obecného pravidla, a když uplatnění tohoto pravidla je zjevné. V (1996) jsme bezslovoslednou podoby věty zpřístupňovali záznamem, v němž byly slovní tvary věty abecedně uspořádány. Takový záznam budeme používat i zde; stejně jako v (1997) ho budeme uvádět písmenem α.[6] Potom tedy bezslovoslednou podobu věty
| [100](1) | váš pes je v boudě na zahradě za jejím domem |
zaznamenáme jako
| (α1) | α boudě domem je jejím na pes v váš za zahradě |
Nevylučuji však, že by se nějaké jiné pořadí mohlo ukázat pro záznam bezslovosledné podoby věty výhodnějším. Ostatně záznam bezslovosledné podoby věty nemusí být jednorozměrný. Mohlo by jím např. být dvourozměrné schéma, v němž jsou zleva doprava slovní tvary uspořádány podle délky měřené počtem písmen a shora dolů při stejné délce abecedně. Kdybychom takový záznam uvozovali symbolem α’, byla by bezslovosledná podoba věty (1) zaznamenána schématem
| (α’1) | α’ | v | je | pes | boudě | zahradě |
|
|
|
| na | váš | domem |
|
|
|
|
| za |
| jejím |
|
Různé záznamy bezslovosledné podoby téže věty jsou rovnocenné v podobném smyslu jako různé diagramy téhož grafu (grafu jako abstraktního objektu, který je předmětem teorie grafů). Avšak podobně jako rozdílné diagramy jednoho grafu i rozdílné záznamy bezslovosledné podoby jedné věty mohou být pro různá užití různě výhodné.
Slovosled lze zablokovat i v syntaktickém rozboru. To, co ze syntaktického rozboru zůstává, když v něm zablokujeme slovosled, nazvu jeho bezslovoslednou podobou. Pro jednoduchost budu místo o bezslovosledné podobě syntaktického rozboru většinou stručněji hovořit jen o bezslovosledném (syntaktickém) rozboru. Bezslovosledný rozbor lze zpřístupnit jeho záznamem. Budu využívat především takový druh záznamu bezslovosledného syntaktického rozboru, který se objevil již v (1996), uvedu však ještě jiný druh záznamu; využíval jsem ho v (1997).
Uvažujme nějakou gramaticky správnou a smysluplnou větu V. Mezi ní a jejím (dokončeným) syntaktickým rozborem se nacházejí různé části syntaktického rozboru. V duchu matematické terminologie by bylo vhodné považovat za část rozboru jak rozbor dokončený, tak ještě nezačatý, tedy i samotnou větu V. V témže duchu lze potom říci, že tou nejmenší částí bezslovosledného rozboru věty V je bezslovosledná podoba této věty. Pokud na takovou terminologii přistoupíme, můžeme otázku, jak se slovosled věty V podílí (či naopak nepodílí) na konečném výsledku jejího syntaktického rozboru, formulovat přesněji: jakou svou nejmenší částí Pmin se bezslovosledný syntaktický rozbor věty V liší od bezslovosledných syntaktických rozborů všech těch vět, které mají s větou V společnou bezslovoslednou podobu, ale od bezslovosledného rozboru věty V se různí?
2.2. Domnívám se, že právě zpřesněná otázka se stane průhlednější, bude-li předváděna na uměle utvořených příkladech. Opustíme tedy na chvíli češtinu a budeme uvažovat věty nějakého formálního jazyka J. Slovními tvary v nich budou písmena. V souladu s tím, co bylo řečeno v odd. 2.1., budeme jako záznam bezslovosledné podoby věty jazyka J užívat abecední uspořádání jejích slovních tvarů uvozené písmenem α. Zvolíme takový syntaktický přístup, v němž je věta jazyka J rozkládána do nepojmenovaných složek, a o každé z takových vět budeme předpokládat, že má (v uvažovaném přístupu) právě jeden syntaktický rozbor.
[101]Nejprve si povšimněme věty
| (2) | c | d | b | a |
a záznamu
| (α2) | a | b | c | d |
její bezslovosledné podoby. Budeme předpokládat, že v jazyce J existují celkem čtyři gramaticky správné a smyslupné věty, jejichž společnou bezslovoslednou podobu podává záznam (α2). Kromě věty (2) to jsou pouze tyto tři další věty:
| (3) | c | b | a | d | (4) | d | b | a | c | (5) | b | a | d | c |
Každá z vět (1)–(4) má v přístupu, který uvažujeme, právě jeden syntaktický rozbor. Rozbor každé z vět je určen vymezením všech netriviálních složek věty, tj. složek, které obsahují více než jeden slovní tvar, ale méně než všechny slovní tvary věty. Všechny netriviální složky v každé z vět (2)–(5) budou spojité, a proto lze větný rozbor vyjářit tak, že počátek/konec každé věty ohraničíme levou/pravou závorkou. Budeme předpokládat, že výrazy (2*)–(5*) jsou syntaktické rozbory vět (2)–(5):
| (2*) | c | (d | (b | a)) |
| (3*) | c | ((b | a) | d) |
| (4*) | (d | (b | a)) | c |
| (5*) | ((b | a) | d) | c |
Nyní představím dva druhy záznamů, jimiž lze zpřístupnit bezslovoslednou podobu syntaktického rozboru. Začnu tím, který se objevil již v stati (1996). Bude ho nazývat lineárním záznamem a uvozovat písmenem α. Tento záznam bezslovosledného rozboru vzniká postupným abecedním uspořádáním „dceřiných“ složek každé složky o alespoň dvou slovních tvarech. Jeho vznik předvedu na příkladu syntaktické rozboru (2*) věty (2). Postupné nahrazování nejprve slovosledu a potom stop po něm abecedním uspořádáním „dceřiných“ složek je patrné z následujícího diagramu, v němž umístění písmene α ukazuje nejvyšší úroveň, na níž až dosud k nahrazení slovosledu došlo:
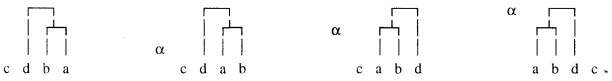
Vrátíme-li se k lineárnímu zápisu, získáme výraz
| (α2*) | α | ((a | b) | d) | c |
jako lineární záznam bezslovosledného rozboru věty (2).[7]
Druhý druh záznamu bezslovosledného syntaktického rozboru jsem využíval v článku (1997). Protože takový záznam přímo vychází z nahrazení slovosledu věty abecedním uspořádáním jejích slovních tvarů a protože je dvourozměrným schématem, mohu ho nazývat plošným záznamem a uvozovat např. symbolem α2. Záznam se skládá z horního řádku, na němž jsou abecedně uspořádané slovní tvary věty, a z dalších řádků, z nichž každý odpovídá netriviální složce. To, že slovní tvar patří do uvažované [102]složky, ukazuje značka x. Aby byl tento záznam jednoznačně určen, jsou složky řazeny abecedně (tento požadavek v (1997) chyběl). Je zřejmé, že schéma
| (α22*) | α2 | a | b | c | d |
|
|
|
| x | x |
|
|
|
|
| x | x | x |
je plošným záznamem bezslovosledné podoby rozboru věty (2).
Požadavek jednoznačnosti určení plošného záznamu je splnitelný, pokud se slovní tvary ve větě nevyskytují násobně. Tehdy jsou lineární a plošný záznam bezslovosledného syntatického rozboru zcela rovnocenné. Rozměrnost plošného záznamu může být přijímána jako nevýhoda, jeho menší „hustota“ však vede k větší přehlednosti. V dalších příkladech se omezím na lineární záznamy bezslovosledných syntatických rozborů.
Jak tedy rozbor věty (2) závisí na slovosledu? Snadno se přesvědčíme, že výraz (α2*) je záznamem bezslovosledného rozboru každé z vět (2)–(5). Bezslovosledné syntaktické rozbory vět (2)–(5) jsou tedy totožné. Protože nenacházíme žádnou větu, jejíž bezslovosledná podoba by byla totožná s bezslovoslednou podobou věty (2), ale její bezslovosledný rozbor by se od bezslovosledného rozboru věty (2) odlišoval, hledaná část Pmin bezslovosledného rozboru věty (2) je bezslovoslednou podobou věty (2). Syntaktický rozbor věty (2) je na slovosledu nezávislý.
Uvažujme nyní věty (6)–(9) jazyka J spolu s jejich syntaktickými rozbory (6*)–(9*):
| (6) | f | e | j | h | i | g | (6*) | ((f | e) | j) | (h | (i | g)) |
| (7) | i | g | h | f | e | j | (7*) | (i | j) | (h | ((f | e) | g)) |
| (8) | i | j | f | e | g | h | (8*) | (i | g) | (((f | e) | j) | h) |
| (9) | i | g | h | f | e | j | (9*) | ((i | j) | h) | ((f | e) | g) |
Je zřejmé, že
| (α6) | e | f | g | h | i | j |
je nejen záznamem bezslovosledné podoby věty (6), ale i každé z vět (7)–(9). Bezslovosledné syntaktické rozbory vět (6)–(9) jsou však navzájem různé, jak ukazují jejich lineární záznamy:
| (α6*) | α | ((e | f) | j) | ((g | i) | h) | (α7*) | α | (((e | f) | g) | h) | (i | j) |
| (α8*) | α | (((e | f) | j) | h) | (g | i) | (α9*) | α | ((e | f) | g) | (h | (i | j)) |
Připustíme, že jazyk J má ještě jiné gramaticky správné a zároveň smysluplné věty, jejichž bezslovosledná podoba je totožná s bezslovoslednou podobou věty (6). Budeme však zároveň předpokládat, že bezslovosledný syntaktický rozbor kterékoli takové věty se shoduje s bezslovosledným syntaktickým rozborem jedné z vět (6)–(9).
Položíme-li nyní otázku, jak se slovosled věty (6) podílí na jejím větném rozboru, shledáme, že odpověď je snadná. Záznamy bezslovosledných rozborů vět (6)–(9) ukazují, že bezslovosledný rozbor věty (6) od bezslovosledných rozborů vět (7)–(9) odlišuje složka tvořená slovními tvary (v abecedním pořadí) g, h, i. V hledané části Pmin bezslovosledného rozboru věty (6) je vyznačena jediná složka. Rozšíříme-li (způsobem, který se samozřejmě nabízí) princip lineárního záznamu bezslovosledného syntaktickém rozboru i na jeho části, můžeme Pmin zpřístupnit záznamem
| (6.1) | α | e | f | (g | h | i) | j |
[103]Poté, co byla uskutečněna část syntaktického rozboru věty (6) spočívající v nalezení jediné netriviální složky (h i g), tedy část, kterou lze zaznamenat výrazem
| (6.1’) | f | e | j | (h | i | g) |
bylo možné slovosled v této části rozboru zablokovat, a tím získat Pmin.
V třetím příkladu budeme uvažovat věty (10) a (11) jazyka J spolu s jejich syntaktickými rozbory (10*) a (11*):
| (10) | o | l | m | n | k | p | (10*) | ((o | l) | m) | (n | (k | p)) |
| (11) | l | m | n | o | k | p | (11*) | (l | m) | (n | ((o | k) | p)) |
Zápis
| (α10) | k | l | m | n | o | p |
je společným záznamem bezslovosledné podoby vět (10) a (11). Jak však ukazují lineární záznamy, bezslovosledné syntaktické rozbory těchto dvou vět se navzájem liší:
| (α10*) | α | ((k | p) | n) | ((l | o) | m) | (α11*) | α | (((k | o) | p) | n) | (l | m) |
Připustíme, že jazyk J má ještě jiné gramaticky správné a zároveň smysluplné věty, jejichž bezslovosledná podoba se shoduje s bezslovoslednou podobou věty (10). Budeme však zároveň předpokládat, že bezslovosledný rozbor každé takové věty je shodný s bezslovosledným rozborem věty (10) nebo věty (11).
Jak se slovosled věty (10) podílí na jejím větném rozboru, je zřejmé. Záznam rozboru věty (10) od záznamu rozboru věty (11) se liší každou ze svých čtyř netriviálních složek. Pro hledanou část Pmin bezslovosledného rozboru věty (6) nalézáme čtyři možná řešení, která zpřístupňují jejich záznamy:
| (10.1) | α | k | (l | o) | m | n | p |
| (10.2) | α | k | (l | m | o) | n | p |
| (10.3) | α | (k | n | p) | l | m | o |
| (10.4) | α | (k | p) | l | m | n | o |
Poté, co byla uskutečněna část syntaktického rozboru věty (10) spočívající v nalezení právě jedné netriviální složky, tedy část, kterou lze zaznamenat jedním z těchto čtyř výrazů
| (10.1’) | (o | l) | m | n | k | p |
| (10.2’) | (o | l | m) | n | k | p |
| (10.3’) | o | l | m | (n | k | p) |
| (10.4’) | o | l | m | n | (k | p) |
bylo možné slovosled v této části rozboru zablokovat, a tím získat všechna čtyři řešení bez slovosledné části Pmin syntaktického rozboru věty (10).
Právě jsme se setkali se situací, kdy odpověd na otázku po hledané části Pmin není jednoznačná, ale má více řešení. Shledáme-li snad takovou skutečnost neuspokojivou, stojí za to nahlédnout do matematiky, např. do algebry: jak známo, algebraická rovnice může mít více různých kořenů (tedy řešení).
2.3. To, že jsme se v odd. 2.2. věnovali umělým příkladům, výklad nesnadno formulovatelné myšlenky ulehčilo. Umělost příkladů může však překrýt některé problémy. Na jeden z nich upozorním v odd. 5.
[104]Abych však nezůstal pouze u umělých příkladů, připojím jednoduchý příklad českých vět. Uvažujme větu
| (12) | Karel zná švagra jejího bratra |
spolu s jejím syntaktickým rozborem do (spojitých) neoznačených složek
| (12*) | Karel (zná (švagra (jejího bratra))) |
Bezslovoslednou podobu věty (12) lze zaznamenat jako
| (α12) | α bratra jejího Karel švagra zná |
a bezslovosledný syntaktický rozbor věty (12) jako
| (α12*) | α (((bratra jejího) švagra) zná) Karel |
Lze nalézt jinou českou větu, jejíž bezslovosledná podoba splývá s bezslovoslednou podobou věty (12), avšak jejíž bezslovosledný syntaktický rozbor se od bezslovosledného rozboru věty (12) liší.
Takovou větou je např. věta
| (13) | Karel zná bratra jejího švagra |
jejíž bezslovosledný syntaktický rozbor lze zaznamenat jako
| (α13*) | α ((bratra (jejího švagra)) zná) Karel |
O každé gramaticky správné a zároveň smysluplné české větě, jejíž bezslovosledná podoba splývá s bezslovoslednou podobou věty (12), platí, že její bezslovosledný rozbor lze zaznamenat buď zápisem (α12*), nebo (α13*). Jak záznamy bezslovosledných rozborů vět (12) a (13) ukazují, nejmenší částí bezslovosledného rozboru (α12*), která tento bezslovosledný rozbor odlišuje od bezslovosledného rozboru (α13*), je ta, kterou zpřístupňuje záznam
| (α12.1) | α (bratra jejího) Karel švagra zná |
A tak tedy poté, co uskutečníme částečný rozbor
| (12.1) | Karel zná švagra (jejího bratra) |
věty (12), můžeme slovosled v tomto částečném rozboru zablokovat a být si přitom jisti, že pokračováním v bezslovosledném rozboru nezískáme jiný výsledek než ten, který jsme zaznamenali výrazem (α12*).
K usnadnění výkladu přispívá volba syntaktického přístupu: u složkovového rozboru věty, který je určen množinou svých netriviálních složek bez ohodnocení, lze jednoduše vymezovat jeho části; kromě toho lze jeho bezslovoslednou podobu i bezslovoslednou podobu jeho částí snadno zaznamenávat. Pokud bychom přešli k jiným syntaktickým přístupům, museli bychom pojmy, s nimiž jsme zde pracovali, těmto přístupům přizpůsobit. Jsem přesvědčen, že takové přizpůsobení, které zachovává smysl otázky zpřesněné v odd. 2.1., je možné.
3.1. V článku (1997) jsem k větným faktorům, o kterých jsme uvažovali v společné stati s P. Novákem (1996), přidal další faktor, totiž kontext věty. Zde však od kontextu, v němž je věta užita, abstrahuji. Tedy: o větě zde uvažuji až poté, co v ní byl faktor [105]kontextu zablokován. To mohu učinit, pokud ze svých úvah vyloučím věty, u niž zablokování kontextu vede k více syntaktickým rozborům.
Zaměřuji se tedy pouze na faktory, které by bylo možno nazvat vnitřními faktory věty. Nejvíce pozornosti věnuji slovosledu, tedy faktoru, jehož zablokování je z formálního hlediska nejobtížnější, protože je nedělitelné. Zablokování dalších dvou vnitřních faktorů, o které jsme se zajímali v (1996), totiž faktoru flektivního i lexikálního, dělitelné je. Až na výjimky lze zablokování flektivního nebo lexikálního faktoru ve větě chápat jako souhrn jeho zablokování v jednotlivých slovních tvarech věty.[8]
V odd. 2.1. jsem rozlišil bezslovoslednou podobu věty a bezslovosledný rozbor věty (a obecně bezslovosledné části rozboru věty) od jejich záznamů. Podobné rozlišení mohu provést u dalších dvou faktorů.
3.2. Záznam zpřístupňující bezflektivní podobu věty (tedy to, co z věty zůstane poté, co je v ní zablokována flexe) budu konstruovat podobně jako v (1996): slovní tvar nahradím základním tvarem lexému, k němuž patří (jde-li o jediný tvar neohebného lexému, ponechám tvar beze změny); takový záznam budu uvádět písmenem β.[9] Očekávaným způsobem mohu zavést bezflektivní syntaktický rozbor věty i jeho bezflektivní části. V následujícím příkladu opět využijeme syntaktický přístup vedoucí k rozboru věty do nepojmenovaných složek. Uvažujme větu
| (14) | bohatou večeři následovala nudná přednáška |
spolu s jejím syntaktickým rozborem
| (14*) | ((bohatou večeři) následovala) (nudná přednáška) |
Bezflektivní podobu věty (14) lze zaznamenat jako
| (β14) | β bohatý večeře následovat nudný přednáška |
a její bezflektivní syntaktický rozbor jako
| (β14*) | ((bohatý večeře) následovat) (nudný přednáška) |
S bezflektivní podobou věty (14) splývá bezflektivní podoba věty
| (15) | bohatá večeře následovala nudnou přednášku |
Její bezflektivní rozbor lze zaznamenat jako
| (β15*) | (bohatý večeře) (následovat (nudný přednáška)) |
Bezflektivní rozbor každé gramaticky správné a přitom smysluplné věty, jejíž bezflektivní podoba splývá z bezflektivní podobou věty (14), lze zaznamenat jako (β14*) nebo (β15*). Nejmenší část bezflektivního rozboru věty (14), která ho odlišuje od bezflektivního rozboru věty (15), lze zapsat
| (β14.1) | β (bohatý večeře následovat) nudný přednáška |
Zablokujeme-li tedy flexi v částečném rozboru
| [106](14.1) | (bohatou večeři následovala) nudná přednáška |
věty (14), k jinému bezflektivnímu rozboru než k bezflektivnímu rozboru věty (14) nedojdeme.
3.3. Kdybychom nyní chtěli přistoupit k blokování faktoru lexikálního, znamenalo by to přejít od vět, které jsou gramaticky správné a zároveň smysluplné, k větám pouze gramaticky správným. Přistoupíme-li na teoretický předpoklad, že množinu všech gramaticky správných vět jazyka známe, můžeme vysvětlení bezlexikální podoby věty opřít o pojem rodiny ve smyslu O. S. Kulaginové (1958):[10] přejít od věty k její bezlexikální podobě by znamenalo nahradit každý slovní tvar věty rodinou, do níž tento slovní tvar patří. Předpokládejme, že v každé rodině je vybrán právě jeden z jejích prvků jako její zástupce. Potom nahrazením každého slovního tvaru věty zástupcem rodiny, do níž slovní tvar patří, získáme záznam, jímž můžeme bezlexikální podobu věty zpřístupnit. Analogickým způsobem můžeme zpřístupnit bezlexikální syntaktický rozbor věty i kterékoli bezlexikální části rozboru.
Jak si však s tímto teoretickým předpokladem poradit? Zaměříme-li se pouze na tvary slov ohebných a hledáme-li přitom řešení, které by bylo na dosah, může nás napadnout, že za ony zástupce rodin by bylo možné považovat tvary vzorových slov deklinace a konjugace. K nim, a to přímo (tedy bez úvahy o rodinách ve smyslu Kulaginové), jsme se obrátili v společné stati (1996) s P. Novákem.[11] Úloha, kterou vzory deklinace a konjugace (ať již vzory školních gramatik češtiny, nebo vzory mnohem podrobnější) plní, se však liší od toho, co bychom pro bezlexikální záznam věty potřebovali. Vzory (školní hruběji, podrobnější jemněji) reflektují to, co se při ohýbání děje uvnitř slova, ale na syntaktickou roli slovního tvaru ve větě se přímo nezaměřují. Otázku po nalezení vhodného nástroje k zaznamenání bezlexikální podoby věty a bezlexikálního syntaktického rozboru stavím jako otevřený problém.[12]
V odst. 2.1. jsem uvedl, že záznam bezslovosledné podoby věty by nemusel být výsledkem obecného pravidla (že však nevyužít snadno dostupného pravidla pro jeho konstrukci by bylo nevýhodné). V situaci, kdy podobně dostupné pravidlo pro tvorbu záznamu bezlexikální podoby věty chybí, se jako řešení nabízí záznam uváděný symbolem vyjadřujícím, že „v tomto záznamu věty mohl být kterýkoli slovní tvar x zastoupen takovým slovním tvarem y, jenž v rámci množiny všech gramaticky správných vět je s tvarem x vzájemně zaměnitelný“.
3.4. V stati (1996) jsme uvažovali i o společném blokování dvou (popř. i tří) faktorů ve větě. Aby byl záznam takového složeného zablokování možný, musí být záznam zablokování v pořadí druhého faktoru definován tak, aby byl aplikovatelný nejen na zápis věty, ale i na záznam věty po zablokování faktoru v pořadí prvního.
[107]Způsob, jímž jsme v (1996) signalizovali blokování flektivního faktoru (záznam psaný výhradně velkými písmeny), neumožňoval rozlišit mezi pořadím, v němž jsou faktory zablokovávány.[13] Zůstaneme-li u slovosledu a flektivního faktoru a vyjdeme-li z těch záznamů bezslovosledné podoby věty, které jsme uvozovali písmenem α, a těch záznamů bezflektivní podoby věty, které jsme uvozovali písmenem β, můžeme symbolem αβ rozlišit zablokování slovosledného faktoru následovaného zablokováním faktoru flektivního od zablokování těchto faktorů v opačném pořadí. Výsledky obou zablokování budou v případě těchto dvou faktorů často totožné, vždy však nikoli. Povšimněme si věty
| (16) | jsi hvězdou gymnastiky |
Záznamy (α16) a (β16) zpřístupňují její bezslovoslednou a bezlexikální podobu:
| (α16) | α gymnastiky hvězdou jsi |
| (β16) | β být hvězda gymnastika |
Záznamy (αβ16) a (βα16) zpřístupňují podobu věty (16) po zablokování obou uvažovaných faktorů, a to v dvou možných pořadích:
| (αβ16) | αβ gymnastika hvězda být |
| (βα16) | βα být gymnastika hvězda |
Zpravidla lze zablokování flektivního faktoru ve větě chápat jako souhrn jeho zablokování v jednotlivých slovních tvarech věty. Výjimkou jsou analytické slovní tvary. Způsob zaznamenání bezflektivní podoby věty, který používáme, bychom však mohli rozšířit tak, že základní podoba slova, o jehož analytický slovní tvar se jedná, bude zapsána tam, kde stálo určité sloveso uvažovaného tvaru. Tedy bezflektivní podoba věty
| (16) | zítra bych určitě přijel |
by byla zaznamenána výrazem
| (β16) | β zítra určitě přijet |
Společný výsledek zablokování flektivního faktoru následovaného zablokováním faktoru slovosledného by potom byl zaznamenán jako
| (βα16) | βα přijet určitě zítra |
Možnost zablokování slovosledu následovaného zablokováním flektivního faktoru ve větě obsahující analytické slovní tvary stavím jako otevřený problém.
4.1. Domnívám se, že stojí za to podat obecnou formulaci otázky, jíž jsem se zde zabýval. Uvažujme nějakou gramaticky správnou a smysluplnou větu V. Předpokládám, že v souladu se syntaktickým přístupem, který jsme zvolili, jsme s to určit syntaktický rozbor věty V. Mezi ní a jejím (dokončeným) syntaktickým rozborem se nacházejí různé části syntaktického rozboru; k částem syntaktického rozboru věty V řadím i obě krajnosti: větu V i její (úplný) syntaktický rozbor. Zvolme některý větný faktor F. Všimneme si množiny X všech gramaticky správných a smysluplných vět, které jsou po zablokování faktoru F nerozlišitelné od věty V, je-li zablokován faktor F i v ní. [108]U každé z vět množiny X určíme její syntaktický rozbor (podle zvoleného syntaktického přístupu) a potom v každém z těchto syntaktických rozborů zablokujeme faktor F. Množinu všech syntaktických rozborů se zablokovaným faktorem F, které takto získáme, označíme jako Y. (Může se stát, že při zablokování faktoru F slovosledné rozbory různých vět množiny X splynou. Potom má množina Y méně prvků než množina X.) Do množiny Y ovšem patří i syntaktický rozbor věty V, v němž byl zablokován faktor F; označme ho jako Y(V). Základní otázka zní: jakou nejmenší částí se Y(V) liší od všech ostatních prvků množiny Y? (Jak víme z odd. 2.2., tato nejmenší část nemusí být určena jednoznačně.)
Zodpovídáním položené otázky syntaktický rozbor Y(V) věty V, v němž je zablokovaný faktor F, analyzujeme, a tím nepřímo analyzujeme i syntaktický rozbor věty V (tj. její rozbor bez zablokování faktoru F). Vzhledem k větě V tedy vlastně provádíme jistou metaanalýzu.
4.2. Až na letmou zmínku o kontextu, uvažuji zde o stejných větných faktorech jako v stati (1996): o slovosledu, flektivním faktoru a lexikálním faktoru. Neuvedl jsem však žádný příklad bezlexikální podoby věty, jejího bezlexikálního rozboru (ani žádné jeho bezlexikální části), protože snadný a zároveň realisticky adekvátní záznam bezlexikální podoby slovního tvaru, tj. rodiny (ve smyslu Kulaginové), do níž tento tvar patří, považuji za otevřený problém. Avšak stejně jako o slovosledu a flektivním faktoru, i o lexikálním faktoru platí: můžeme-li při jeho zablokování od nějakého částečného rozboru věty dojít až k rozboru úplnému (v němž je ovšem tento faktor také zablokován), můžeme tak učinit jen díky tomu, co zůstalo ve větě nezablokováno. Toto triviální tvrzení nás přivádí k otázce, která již triviální není. Při její formulaci využiji symbolismu odd. 4.1.
Zablokováním faktoru F budeme mínit postupné zablokování tří uvažovaných faktorů v některém z možných pořadí (bude-li třeba, vyzkoušíme všechna pořadí, pokud ovšem v každém z šesti možných pořadí uvažované faktory zablokovat umíme). Budeme se tázat, zda existuje věta V taková, že (a) množina Y (vztažená k postupnému zablokování tří uvažovaných faktorů) obsahuje kromě Y(V) ještě alespoň jeden jiný objekt a (b) Y(V) má nějakou vlastní (tj. neúplnou) část, jíž se liší od všech ostatních prvků množiny Y.
Kdybychom došli ke kladné odpovědi, znamenalo by to, že jsme na větě objevili ještě další faktor. Existenci/neexistenci takového „zbytkového“ větného faktoru stavím jako další otevřený problém.[14]
4.3. Je přirozené se ptát, jak uvažované pojmy zobecnit nebo modifikovat. Především jak modifikovat uvažované větné faktory. Představme si kupř., že bychom za hranice slovního tvaru nepovažovali mezery, ale že bychom slovní tvar definovali tak, aby vždy začínal slovním přízvukem (přesněji: začínal tam, kde by byl slovní přízvuk, pokud bychom psanou větu vyslovili). Kdybychom této změně přizpůsobili vymezení uvažo[109]vaných tří faktorů, ztratily by část své dosavadní vzájemné nezávislosti. Domnívám se, že dobré modifikace větných faktorů by byly jen takové, které by jejich vzájemnou nezávislost nezmenšily (a lze-li, ještě ji zvětšily).
Pokud jde o zobecnění, domnívám se, že jedno se samo nabízí. Vázat naše postupy jen k celým větám může být někdy nepohodlné. Bylo by snadné je vztáhnout i k jiným funkčně uceleným frázím, např. k frázím nominálním.
Lze také uvažovat o částečné blokaci faktoru. Např. z flektivního faktoru zablokovat jen rozdíl mezi singulárem a plurálem. Nebo ze slovosledu věty zablokovat pouze pořadí adjektiv. Potom by např. bylo možno na jednom řádku uvést adjektivní slovní tvary v abecedním pořadí a na druhém řádku prezentovat slovosledné uspořádání ostatních tvarů spolu s pomlčkami na místě adjektiv; záznam by byl uvozen symbolem αadj. To znamená, že větu
| (17) | větší chlapec s bílou čepicí nese menší kufr s modrou visačkou |
poté, co v ní bylo zablokováno slovosledné pořadí adjektivních slovních tvarů, by zpřístupňoval záznam
| (αadj17) | αadj bílou menší modrou větší | |
|
| – chlapec s – čepicí nese – kufr s – visačkou | |
5. Závěrem se vrátím k jednomu rozdílu mezi statí (1996) a tímto příspěvkem. Myšlený pokus, o který se v (1996) opírá analýza míry závislosti syntaktického rozboru věty V na faktoru F, se snadno popíše, ale obtížně uskuteční. Avšak ani nalezení množiny X všech gramaticky správných a smysluplných vět, které jsou po zablokování faktoru F nerozlišitelné od věty V, není bez problémů. Především proto, že věty tvořící množinu X mohou být nestejné úrovně: zatímco některé zcela samozřejmě přijímáme, jiné třeba vnímáme jako neobratné a tolerujeme je jen s rozpaky. Z takové situace je však východisko, pro které lze v lingvistice nalézt vzory: nesrovnávat větu V s všemi ostatními větami množiny X, ale vždy jen s jednou, dobře vybranou větou.
LITERATURA[15]
KULAGINA, O. S: Ob odnom sposobe opredelenija grammatičeskich ponjatij na baze teorii množestv. In: Problemy kibernetiki, I. Fizmatgiz, Moskva 1958, s. 203–214.
NEBESKÝ, L.: An analysis of syntactic formulae. In: Proceedings of LP’96. Ed. B. Palek. Charles University Press. Prague 1997, s. 451–462.
NEBESKÝ, L.: The relationship between syntactic analysis and word order awareness. Proceedings LP2000. Ed. B. Palek. Charles University Press, Prague 2001, s. 367–375.
NEBESKÝ, L. – NOVÁK, P.: Větné faktory a jejich podíl na analýze věty. SaS, 57, 1996, s. 249–263.
SVOZILOVÁ, N. – PROUZOVÁ, H. – JIRSOVÁ, A.: Slovesa pro praxi. Valenční slovník nejčastějších českých sloves. Academia. Praha 1997.
[110]R É S U M É
Sentence factors and their role in sentence analysis II
In the article „Sentence factors and their role in sentence analysis“ (in Czech) (SaS, 57, 1996, p. 249–263), written in collaboration with P. Novák, the question was explored, to what extent the result of syntactic analysis of a separate sentence depends on the knowledge of its word order or of some other complex of facts which we can „block“ in the usual shape of the sentence; such complexes of facts were called sentence factors. In this article, I deal with the same topic, putting more emphasis on its formal aspects.
[*] Tato stať vznikla v rámci výzkumného záměru MSM 112100003 (MŠMT ČR). – Cenné podněty vztahující se někdy volněji, jindy těsněji k tématu této stati jsem nalézal v četných rozhovorech s P. Novákem; naše rozhovory trvají již čtyři desetiletí. Za další podněty k tématu vděčím i některým studentům FF UK v Praze.
[1] Výslovně jsme tam zdůraznili, že náš přístup nebude generativistický.
[2] V naší stati jsme ho nazývali uspořádáním lexikografickým.
[3] Zablokování slovosledu jsme signalizovali písmenem L, které záznam věty uvádělo. Zablokování flektivního faktoru jsme signalizovali zapsáním věty velkými písmeny. Zablokování lexikálního slovosledu jsme signalizovali podtržením.
[4] V popisu našeho pokusu se objevila ještě osoba C; ta pokus vede.
[5] V článku (2002) jsem se omezil pouze na tento faktor.
[6] Frekvence slovních tvarů ve větě je přitom zachována. Kupř. záznamem bezslovosledné podoby věty Eva a Karel cestovali po Rakousku a potom po Itálii bude zápis α a a cestovali Eva Itálii Karel po po potom Rakousku.
[7] Pouze pro jednoduchost jsou příklady představené v tomto oddílu voleny tak, aby všechny složky syntaktického rozboru byly spojité. I kdybychom však volili za příklad větu, jejíž syntaktický rozbor má i nespojité složky, v lineárním záznamu bezslovosledné podoby tohoto rozboru budou všechny složky zaznamenávány jako spojité.
[9] Pro jednoduchost teď ponechávám stranou případy, pro něž by bylo třeba zvolit zvláštní řešení, především vztažná zájmena.
[10] Řekneme, že slovní tvary x a y patří do téže rodiny, když pro libovolné (prázdné nebo neprázdné) řetězy P a Q slovních tvarů platí: řetěz PxQ je gramaticky správná věta, právě když řetěz PyQ je gramaticky správná věta.
[11] Že jsme si však byli vědomi přibližnosti takového řešení, lze vyčíst z pozn. 5 v cit. stati. Připomínám však, že jsme se tam zaměřili jen na slova ohebná.
[12] Při omezení na tvary sloves by cestu k takovému nástroji mohl ukazovat valenční slovník Svozilová – Prouzová – Jirsová (1997).
[13] Totéž lze říci o tom, jak jsme signalizovali zablokování faktoru lexikálního.
[14] Pokud bychom však takový „zbytkový“ faktor opravdu nalezli a přitom shledali, že je nesourodý, mohli bychom ho rozdělit na další faktory.
[15] Poměrně rozsáhlou literaturu citovanou v společné stati (1996) s P. Novákem chápu jako jakýsi horizont i pro tento svůj příspěvek. Zde cituji pouze tituly, k nimž bezprostředně odkazuji. V (1996) citovány nebyly (a až na jednu výjimku ani být citovány nemohly).
Ústav lingvistiky a ugrofinistiky FF UK
nám. Jana Palacha 2, 116 38 Praha 1
Slovo a slovesnost, ročník 63 (2002), číslo 2, s. 98-110
Předchozí Frederick J. Newmeyer: Formal linguistics and functional explanation: Bridging the gap
Následující Kamila Karhanová: Kritická analýza současného politického diskursu: Nový jazyk britských labouristů
© 2011 – HTML 4.01 – CSS 2.1