
Skladebná platnost některých zájmen a číslovek (Příspěvek k problematice větných vzorců)
Zdeněk Hlavsa
[Articles]
Синтаксическая функция некоторых местоимений и числительных (К проблематике моделей предложения) / Valeur syntaxique de certains pronoms et numeraux (Contribution au problème des modèles syntaxiques)
1. V tomto článku se budeme zabývat syntaktickými funkcemi nepříliš početné, ale z hlediska frekvence důležité skupiny slov, kterou tvoří (ve smyslu běžné klasifikace) zájmena ukazovací (např. ten), neurčitá (např. nějaký, některý, kdosi), vymezovací (např. každý, všichni), záporná (např. nikdo, žádný) a dále číslovky základní určité i neurčité (např. dva, pět, několik). Zdálo by se, že tak různorodé prvky není dost dobře možno popsat jako třídu výrazů s nějakými společnými rysy. Avšak tato pestrost plyne hlavně ze zdůraznění některých třídicích kritérií, především sémantického (i když sémantická analýza zvlášť v těchto případech často vede k mlhavým nebo „kruhovým“ významovým definicím a není proto náhodou, že i klasifikace dovolávající se měřítek významových právě u těchto slov se nezřídka neshodují), v menší míře morfologického (srov. však totožnost flexívního typu u zájmen ten a číslovky jeden, u neurčitého někdo a záporného nikdo, nebo naopak různost u zájmen neurčitých nějaký a kdosi, záporných nikdo a žádný atd.).
Pokud jde o vlastnosti syntaktické, řadí se zmíněné jednotky buď k adjektivům (např. nějaký, všichni, dva), nebo k substantivům (např. někdo, kdosi, nic).[1] Velká skupina číslovek se ovšem hodnotí jako heterosyntaktická (např. pět, několik), srov. zde odst. 2.2. Takový pohled zas celou věc nepatřičně zjednodušuje, neboť je možno najít závažné rysy, které odlišují syntaktické fungování všech těchto slov od funkce ostatních syntaktických substantiv a adjektiv. Pokusím se to ukázat pomocí analýzy aplikující větné vzorce, jak ji navrhl F. Daneš.[2] I když jde vlastně o formalizaci pojetí známého z našich základních prací o skladbě, jakmile začneme se systémem tohoto typu pracovat, jsme nuceni diferencovat pojmy podstatně přesněji než při použití metod, které si nekladou za cíl dospět k explicitnímu popisu zkoumaného předmětu. Očekáváme zajisté, že každé lexikální heslo by mělo být již ve slovníku opatřeno symbolem zařazujícím je do třídy, která je vymezena specifickým fungováním v syntaktických strukturách. (Jde tedy o morfologickou charakteristiku z hlediska potřeb skladebných, neboť vlastnosti, které nejsou syntakticky relevantní, se ponechávají stranou jako proměnné.) Z tohoto hlediska pak můžeme posuzovat, do jaké míry lze podtřídy zájmen a číslovek uvedené na začátku naší úvahy klasifikovat jako S, resp. A: pokud existují větné struktury, v nichž daný element není použitelný, ať volíme jakékoli lexikální obsazení vzorce, nebo naopak takové, v kterých se ho používá a formulace větného vzorce s tím nepočítá, mělo by jít o snadno postižitelné výjimky, které se zásadně nevztahují na celé třídy prvků. Jinak je třeba [34]zavést jemnější „slovnědruhovou“ klasifikaci; zde dojdeme k závěru, že pro analyzované elementy bude nutno takto předpokládat, že patří k samostatným třídám. Náš článek je zároveň — pokud je nám známo — prvním pokusem o propracování některé oblasti syntaxe v termínech větných vzorců.
2.1 Pokud jde o samy vzorce, symbol A se objevuje jen v typu
(S1 →) Vf → A
| ↑
(Chodí smuten po zahradě. Otec je nemocen)
a v typu
(S1 →) Vf → S4 → A
(Nohu měl bolavou).[3]
Srovnáním zjistíme, že jako A můžeme hodnotit i slova všechen, každý, žádný, mnohý, některý, oba, jeden apod. (Chlapci tam byli tři. Vrátili se jen někteří. Děvče to nedokázalo žádné. Pozval jsem je oba. Píseň uměl každou), avšak nepochybně k nim nepatří nějaký, jakýsi, ten(to) (v zmíněných vzorcích je ho možno však použít výjimečně ve větě uvozující výčet, souhrn, citát apod.: Závěr je tento, Výsledky uvedl tyto). Podtřídu těchto elementů označíme symbolem I.
Slov jako někdo, kdosi, nikdo, nic atd. lze užívat ve vzorcích většinou jako S: Nikdo nenaříkal. Leccos měl od té doby pochroumané. Někoho bolelo v krku. Hudba je cosi nevyslovitelného. Pokud jde o číslovky základní, na první pohled se zdá, že jedna, …, čtyři, mnohý, všichni, každý (pojali jsme je tu hodně široce, zahrneme k nim dokonce i některý) fungují zcela jako A.
2.2 To však neplatí o pět, šest a o číslovkách vyšších a o neurčitých několik, málo, mnoho atd. Kdybychom přijali koncepci, že v nominativě a akuzativě jsou řídícím členem a v ostatních pádech členem závislým,[4] musili bychom jednomu a témuž lexému připisovat dvojí syntaktickou funkci; v prvém případě bychom ho klasifikovali zřejmě jako S (pět mužů jako záležitost mužů, S → S2), v druhém jako A (pěti mužům jako odvážným mužům, S → A), což neodpovídá základnímu požadavku, aby každý lexikální element byl již v slovníku charakterizován symbolem vyjadřujícím jeho syntaktickou aplikovatelnost. Ze sémantických důvodů by bylo přirozenější, kdybychom všechny číslovky shrnuli do jedné třídy. Ukážeme později, že mají společné vlastnosti i z hlediska syntaktického. Proto se pokusíme uplatnit v systému vzorců názor Kopečného,[5] že základní číslovky jsou zásadně členem rozvíjejícím (určujícím). Vyčleníme je jako samostatnou podtřídu s prvky Q. Do systému pravidel by pak vstupovaly až rozvíjecím pravidlem S = S → Q, paralelním s S = S → A, nebo — pokud jde o pět, …, mnoho, … aj., substitucí S1,4/S2 → Q1,4 (pro ostatní pády vystačíme s obecně platným rozvíjecím pravidlem).
Existence dvou gramaticky definovaných podtříd uvnitř Q je však formálně nevýhodná a navíc pak pravidla nedovedou postihnout případy, kdy A významově rozvíjí Q1,4, ale závisí na S2 (kongruuje s ním), např. v spojení necelých pět hodin. Tu se nám hodí Kopečného pojetí, podle něhož substantivum počítaného předmětu v typu pět, mnoho hodin je v numerativě (který je for[35]málně shodný s genitivem plurálu); budeme je symbolizovat jako Sn. Pro potřebu větných vzorců se však pokusíme jít ještě dále: budeme i tvary pět, šest, mnoho, tolik apod. považovat za zvláštní tvary s morfologickou charakteristikou n. V důsledcích to znamená, že S (a tedy i A) by vedle indexů 1, …, 7 mělo navíc index n, naproti tomu některá Q by měla index n místo indexů 1,4 (nebo by prostě byla kongruentní s Sn). Pak lze vztah Sn → Q zahrnout do obecně platného pravidla S = S → Q. Do substitučních pravidel by pak přibylo S1,4/Sn → Q. Jeho uplatněním by se modifikovaly vzorce takto: [(S1 →) Vf] / [Q ← Sn → Vf3sgn]: Několik dívek zpívalo, [(S1 →) Vf → S4] / [(S1 →) Vf → Sn → Q]: Jan vyčistil pět oken,
[(S1 →) Vf → A / [Q ← Sn → Vf3sgn → A]:
| ↑ | ↑
Mnoho hostů sedělo zamlklých.
Objevuje se ovšem i varianta Dvacet žáků bylo zdrávo, což by odporovalo shodě v n. Je to však výjimečný případ, s kterým snad nemusíme ve vzorcích počítat. Adjektiva, která nemají jmenný tvar, se shodují jen s Sn: Dvacet žáků bylo průměrných; také obecná čeština má tu jen An, protože jmenné tvary nezná: Dvacet žáků bylo zdravejch. Něco jiného je Dvacet žáků bylo zraněno, což chápeme jako realizaci vzorce Q ← Sn → Vf3sgn, i když u dokonavých sloves (a proto i v tomto příkladě) jde o výsledný stav, nikoli o děj, takže slovnědruhová interpretace tvaru je sporná.[6] Obecně tu zřejmě platí, že Vf3sgn je závazné a Sn nemůže být redukováno (nevyjádřeno).
Jak již bylo výše naznačeno, spojení těchto číslovek se substantivem počítaného předmětu v pádech ostatních je postiženo rozvíjecím pravidlem S = S → Q, které se vztahuje na genitiv pěti žáků stejně jako čtyř žáků (ovšem žáků je i v prvém případě S2, nikoli Sn).
Popsaný postup se snad zdá být vyumělkovaný. Uvažme však, že paradigma číslovek jako pět, mnoho se dnes jen vzdáleně podobá kterémukoli substantivnímu vzoru a úvahy o směru závislosti se v podstatě zakládají jen na tvaru obou složek spojení. Sjednocení číslovek do jediného, závislého Q má v systému vzorců značné výhody.
Tvary Qn, které si vynucují užití Sn, lze dosti dobře popsat v termínech morfologie:[7] jsou to všechny tvary Q zakončené na -t, -k (pět, jedenáct, dvacet; několik, tolik); pokud jde o ostatní, nezbývá než uchýlit se k výčtu. Jsou to některé na -m (sedm, osm, ale nikoli třem, čtyřem; stem, tisícem nejsou pak vůbec tvary Q, jak ukážeme dále) a na -o (mnoho, sto, avšak sto je i homonymní forma pro všechny pády jedné varianty paradigmatu této číslovky, srov. o sto korunách).
Protože Sn a Qn mají tutéž pádovou charakteristiku, může tvar A záviset na obou, podle toho, která z nich skutečně rozvíjí. I zápisem pak dovedeme vyjádřit rozdíl v struktuře spojení pět trpkých hodin, a to jako Q ← [Sn → A] (hranatými závorkami naznačujeme postup, následnost derivací), a spojení necelých pět hodin, čemuž odpovídá Sn → [Q → A].
Vyšší číslovky mohou být většinou jak Q, tak S. Jako Q je budeme interpretovat tehdy, má-li substantivum počítaného předmětu tvary jednoznačně identifikovatelné jako S3,6,7 (stu, tisíci korunám, korunách; sto, tisíci korunami); pak však musíme [36]místo Q1,4 počítat v příslušném paradigmatu s Qn. Zůstává-li naopak toto substantivum ve všech pádech spojení ve formě S2, je nutno číslovku chápat jako S: stu, tisíci korun; tisícem korun. To odpovídá obvyklému genitivnímu přívlastku u substantiva. Samo „nominativní“ spojení sto, tisíc korun můžeme pak interpretovat dvojím způsobem, buď jako Sn → Q, nebo jako S1 → S2. Tyto rozdíly nemůžeme dobře vykládat jen jako varianty: v spojitelnosti tvarů existují totiž určitá omezení, která ukazují, že sto, tisíc mají paradigmata různá (aspoň v některých pádech) podle toho, mají-li syntaktickou funkci Q, nebo S: stu může být jak Q3 6, tak S3 a snad i S6 (ke stu korunám, o stu korunách — ke stu korun, o stu korun), ale tvar stem je jen S7: srov. se stem korun — *se stem korunami. Rovněž tak není *s tisícem korunami, nýbrž buď tisícem korun, nebo tisíci korunami (tedy tisícem je jednoznačně S7 a tisíci, pokud je to instrumentál, jen Q7).
Při tvoření složených číslovek, tj. tehdy, když se sta, tisíce počítají, zachází se s nimi jako se S. Rozvíjejí se tedy podle pravidla S = S → Q (dvě stě, dva tisíce; dvěma stům, dvěma tisícům), ve vymezeném počtu případů se uplatňuje substituce S1,4/Sn → Q (pět, tolik, mnoho set, tisíc). Avšak celá složená číslovka ve spojení se substantivem počítaného předmětu může být opět S, nebo Q (s Qn v paradigmatu): o dvou stech korun i korunách, o pěti tisících vojáků i vojácích. V paradigmatech složených číslovek opět najdeme určitá omezení, jež některý tvar vyhrazují jediné skladebné funkci: „nesklonné“ dvě stě, tři sta (vlastně homonymní pro všechny pády) může být jen Q, srov. s dvě stě korunami, nikoli *s dvě stě korun. Totéž platí pro složené číslovky se základem tisíc, pokud se v takových tvarech objevují. Tento dvojí syntaktický status mají dokonce i složené číslovky se základem milión (uvádívá se, že jde o jednoznačné substantivum!), i když řídce: je snad možné o dvou miliónech korunách vedle běžnějšího o dvou miliónech korun. Samostatně je však milión výhradně S: o miliónu korun, ne *o miliónu korunách. Teprve vyšší číslovky počínaje miliardou jsou S v jednoduchém použití i ve složené číslovce: o miliardě, o pěti miliardách korun, nikoli o dvou, pěti miliardách korunách. Zpravidla však mluvčí nedovede vždy rozhodnout, který ze sporných tvarů je ještě přijatelný a který už ne.
Tyto rozpaky, jakož i příznaky nejednotnosti syntaktické úlohy v případech jednoznačných ukazují na to, že číslovky opouštějí třídu Q a přecházejí k S tím zřetelněji, čím jsou vyšší. Ukazuje to i kongruence A rozvíjejícího taková spojení. Musíme předpokládat, že toto A kongruuje se základem celého spojení. V případě, že by složená číslovka byla vždy řídícím S, pak by vedle přijatelného instrumentálu se slíbenými třemi sty korun musel být i nominativ *slíbená tři sta korun (něco jiného je ovšem samostatné užití číslovky jako S, např. Poslal mi ta slíbená tři sta), naopak kdyby takovým řídícím členem bylo S počítaného předmětu a složená číslovka jen závislým Q, musilo by A vždy kongruovat s S, a to nejen v nominativě slíbených tři sta korun, nýbrž např. v instrumentálu *se slíbených tři sta korun.
Pokud jde o spojení sto, tisíc korun, uvedli jsme, že je lze interpretovat dvojím způsobem, buď jako S1 → S2, nebo jako Sn → Q. Ale rozvíjející A kongruuje stále ještě se substantivem počítaného, je-li užito sto; tedy sto se v tomto případě chová jako Q (slíbených sto korun, ne *slíbené sto korun), ani tisíc není jasné S (slíbených tisíc korun, snad i slíbený tisíc korun), teprve milión je S, ale vedle snad ještě možného Q: slíbený milión i slíbených milión korun. U složených číslovek je situace podobná, jen s tím rozdílem, že je-li jejím základem milión, číslovka jako celek je jen S: slíbené tři milióny, ne *slíbených tři milióny korun. Tu již nemůže být chápána jako závislé Q. Také výrazy jako spousta, trocha aj. jsou jen S, i když některými svými vlastnostmi mají blízko ke Q.
2.3 Pokusili jsme se ukázat, že v syntaktickém popisu češtiny pracujícím s větnými vzorci je možno spojit mnoho kvantitativních výrazů pod symbol Q. [37]Vrátíme se nyní k naší základní otázce, v kterých vzorcích je možno zahrnout zkoumané prostředky též pod symboly A nebo S. Zatím jsme vyčlenili podtřídu I. Jak jsme uvedli v 2.1, Q se objevuje s A paralelně v typech
(S1 →)Vf → Q,
↑
Vrátili se dva, a v
(S1 →)Vf → S4 → Q,
| ↑
Pozval jsem je všechny.
Přijmeme-li morfologickou charakteristiku n, bude mít první vzorec podobu
Sn → Vf3sgn → Q,
| ↑
Vrátilo se jich pět, druhý pak
(S1 →) Vf → Sn → Q,
| ↑
Pozval jsem jich několik.
Repertoár vzorců bychom však měli rozšířit ještě o dva typy, v nichž se Q od A odlišuje. Jde o tzv. postupně rozvíjející doplněk nebo o doplněk k doplňku;[8] (S1 →) Vf ⇄ Q → A: Hosté seděli všichni zamlklí, Děti byly obě ušpiněné, Vrátili jsme se jen dva zdrávi, a
↓¯¯¯¯¯¯¯¯|
(S1 →) Vf → S4 → Q → A:
| ↑
Našli horníky málokteré živé.
Pro Qn má první vzorec variantu s Sn místo S1, druhý místo S4: Hostů sedělo mnoho zamlklých, Našli jich pět živých. Tyto vzorce jsou důležité, protože jen ony jsou vlastně „diagnostické“ pro Q jak vzhledem k A, tak k I, tj. žádné A ani I tu nemůže Q zastoupit (nejsou však diagnostické vzhledem k symbolům jiným). Bude proto užitečné věnovat jim pozornost.
Předpokládejme především, že mezi Hosté seděli všichni zamlklí a Všichni hosté seděli zamlklí je signifikantní rozdíl, který by měl syntaktický popis vyjádřit. Je-li ovšem uvedený typ opravdu „doplňkem k doplňku“, bylo by snad možné jeho specifikum popsat v termínech pravidel, nikoli vzorců: jako základní by fungoval již známý
(S1 →), Vf → Q, resp.
| ↑
|¯¯¯¯¯¯¯¯↓
(S1 →) Vf → S4 → Q,
do kterého je inkorporována struktura
Q → Vf A.
| ↑
V té jsou Q i Vf totožné s Q a Vf výchozího vzorce, v kterém je však Q členem závislým, zatímco v inkorporovaném celku je řídícím prvkem. Zřetelněji to snad naznačíme takto:
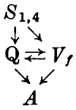
O. Uličný[9] vykládá tyto věty jako výsledek dvouzákladové transformace. Transformační postupy pro větné vzorce nejsou však zatím vypracovány. Pokud jde o chápání rozvíjecích vztahů, shoduje se s Kopečným a Šmilauerem; toto pojetí tu (snad zhruba) přejímáme. Námitky bychom však měli proti tomu, že „doplněk k doplňku“ je omezován toliko na adjektiva označující kvantitu, ač jako řídící element v inkorporované struktuře mohou fungovat např. někdo, nikdo, některá substantiva a mnoho příslovcí (Nebyli jsme nikdo spokojen, Cestujících bylo spousta raněných, Dívek chodilo hodně oblečených [38]podle poslední módy); k větnému typu, o němž je řeč, patří vlastně i případy jako Vrátila se celá opálená, takže vykládat je jako měrové určení adverbiální, jak činí Uličný, znamená vytrhávat je z širších souvislostí.
2.4. Zatím jsme srovnávali Q s A, je však nápadné, že jeho funkce je často paralelní s funkcí S. Máme na mysli věty jako Všichni dostali oběd, Jeden dosáhl času 10,5 vteřin atd. Můžeme takové typy ovšem též chápat jako eliptické (nebo „redukční“), tj. jako Q ← (S1 →) Vf → S4 apod., podobně jako se objevuje elipsa (S →) A: Rovnal knihy tak, že brožované byly vzadu a vázané vpředu. Ale mezi (S →) Q a (S →) A je rozdíl: jako redukované S, které řídí vyjádřené A, můžeme interpretovat jen takové substantivum, které lze z kontextu výslovně dosadit, u S řídícího Q to však nemusí být pravidlem. Představme si kontext Krajánkové, přadláci, drotaři se vždy zastavovali ve mlýně, za kterým následuje (a) Všichni dostali nocleh i najíst, (b) Unavení dostali nocleh a hladoví najíst. Všichni v (a) cítíme jako odkazující, vztahující se k rozšířenému podmětu předchozí věty, unavení, hladoví však spíše jako substantivizovaná adjektiva bez těsnějšího vztahu k předchozímu; jednoznačná volba S tu totiž není možná. V takových případech bychom symbol Q spíše měli do systému zavést substitucí S/Q, podobnou substituci S/PRON.[10] Podobnost Q se zájmeny nepřekvapuje u slov jako všichni, někteří, jež se k zájmenům řadívají, u určitých číslovek však nepochybně ano.
V této souvislosti se však musíme zmínit o jedné pozoruhodné vlastnosti prvků třídy Q. Zkoumáme-li prediktabilitu gramatické osoby u závislého Vf, zjišťujeme, že řídící S omezuje volbu na Vf3, PRONp závislému Vf svou morfologickou charakteristiku předává, avšak Q, pokud samostatně řídí Vf, osobu většinou nepredikuje:
|
každý |
| dostaneš dostane
dostaneme dostanete |
dva, někteří |
|
dostaneme dostanete dostanou |
nocleh |
Tedy např. každý vylučuje jen Vf1sg a Vf3pl; obecněji lze formulovat omezení týkající se čísla, protože některá Q se chovají, jako by měla inherentní charakteristiku plur (např. číslovky určité). Jde tedy o závisle proměnné morfologické kategorie Vf, závislost je dána pak volbou Q. Proto by bylo přece jen výhodnější, kdyby se Q chápalo jako produkt redukce, avšak (PRONp →) Q. Nevýhodou takového řešení je to, že neredukované spojení nemusí být vždy přijatelné: je sice my dva dostaneme, dostanete, ale stěží ty každý dostaneš, nebo dokonce on jeden dostane (srovnáme-li však všechny ukazatele, které nás vedly k zavedení Q, zjistíme, že jeden se z této třídy dost výrazně vymyká). Na druhé straně v obdobných spojeních PRONn → Q je PRON obligatorní: Pět nás dostalo nocleh, takže se nabízí, aby Q bylo zásadně závislé. Odkaz na tento fakt ovšem ztrácí na účinnosti tím, že PRONn zákonitě predikuje jenom Vf3sg. Ať již však tento problém vyřešíme jakkoli, faktem zůstává, že i tyto vlastnosti odlišují Q od A; třebas je zásadně možné rozvíjení PRON = PRON → A, např. ty hloupá, my chudí apod., A po potenciálním [39]řídícím členu může predikovat jen Vf3: není možné Chudí jsme hladověli (aspoň ne jako realizace (PRONpl →) A → Vf), nýbrž jen My chudí jsme hladověli, nebo Chudí hladověli.
Zvláštní chování kategorie osoby ve větách jako Dva dostanete nocleh nevzbudilo zatím, pokud je nám známo, větší pozornost badatelů. Tento typ je většinou považován za doplňkový (srov. V. Šmilauer, o.c., s. 341 pro nikdo, žádný), tj. za realizaci struktury
↓¯¯¯¯¯¯¯¯¯|
Q ← (S1 →) Vf → S4.
Proti tomu mluví několik důvodů. Podle toho Oba jsme se vrátili zdrávi by musil být již „doplněk k doplňku“ a nebylo by možno rozlišit Oba jsme se vrátili zdrávi a Vrátili jsme se oba zdrávi. Je též nekonsekventní oddělovat Oba jsme se vrátili zdrávi a Oba se vrátili zdrávi, kde se oba za doplněk zpravidla nepovažuje, jen kvůli různosti gramatické osoby. Konečně pak kdyby Q při první a druhé osobě bylo zásadně doplňkem, pak bychom musili přiznat, že doplněk nezávisí běžně jen na nominativě a akuzativě, nýbrž i na jiných pádech, srov. např. Posloužilo to nám oběma, resp. Nám to posloužilo oběma, Zbavila se vás všech. Hlavní problém je asi v tam, že při klasifikaci syntaktických typů se předpokládá, že základním nominativním slovním druhem je substantivum; ve skutečnosti obecnější charakter má zájmeno. Bylo by asi jednodušší považovat Zbavila se vás všech a Zbavila se všech nápadníků za touž skladebnou strukturu. Podotýkáme, že tu nejde jen o teoretický problém; s větami jako Všichni jsme jeli na výlet zápolí žáci páté třídy národní školy, jak ukazují dotazy v jazykové poradně Ústavu pro jazyk český.
3.1 Předchozí úvahy nás dovedly k tomu, že detailnější propracování větných vzorců by vyžadovalo odlišení Q, I, A. Uvidíme, že je to užitečné i z hlediska rozvíjecích pravidel. Podotýkáme úvodem, že následující kapitoly vycházejí z předpokladu rekurzívnosti pravidel, tedy očekáváme, že pravidlo S = S → A lze aplikovat víckrát, a opakovat tak rozvíjení symbolu S na pravé straně. Tak mohou vznikat struktury S → A1, [S → A2] → A1, [[S → A3] → A2] → A1 atd.: hezký plášť, hezký béžový plášť, hezký béžový balonový plášť … (indexy se vztahují k pořadí operací a neříkají nic o významovém vztahu mezi A). V tomto pojetí A1 rozvíjí celé S → A2; všimněme si, že toto řešení, k němuž jsme vedeni spíše formálními důvody, má oporu v tom, že můžeme často nahradit rozvitý výraz S → A2 jediným: hezký béžový balonový plášť = baloňák. Z hlediska rekurzívnosti pak zjišťujeme, že jako A1 mají přednost prvky třídy I, dále v pořadí jsou Q a pak teprve ostatní A. Rozvíjecí pravidla budeme tedy formulovat asi takto:
(1) S = S → I
(2) S = S → Q, resp. substituce S1,4/Sn → Q
(3) S = S → A,
přičemž platí, že první dvě můžeme aplikovat jen jednou. Z těchto pravidel je možno některé vynechat, ale musí se zachovat jejich pořadí. Jsou tedy přijatelná spojení odpovídající vztahu S → I (tyto pláště), [S → Q] → I (tyto dva pláště), S → Q (dva pláště), [S → A] → I (tyto béžové pláště), ale nikoli [S → I] → A (*béžové tyto pláště), [S → I] → I (*tyto nějaké pláště), [S → Q] → Q (*mnoho několik plášťů).
[40]Případy jako dva tři pláště („dva až tři …“) jsou jistě výjimečné. Je však nepochybně nutno věnovat pozornost spojení jako všichni tři chlapci, kde je Q zřejmě aplikováno dvakrát. Tu jde o bližší specifikaci kvantity; podobným způsobem se užívá (ne)celý, např. (ne)celých padesát korun, které má zřetelně přechodné postavení mezi A a Q (srov. doplňkový typ v odst. 2.3). Výjimečně mohou takto fungovat i čistá adjektiva, např. dobrý, slabý apod.: slabých sto stupňů, dobrých dvacet bodů („přinejmenším dvacet bodů“). Od toho se zřetelně odlišuje užití dobrý jako jednoznačného A: dvacet dobrých bodů (tj. kladných, nikoli trestných).
Zdálo by se, že se tu zabýváme slovosledem, jak to chápe i Šmilauer (o.c., s. 196), domníváme se však, že je nutno rozlišovat umístění v pořádku slov a v postupu při rozvíjení. Ukazuje na to existence slovosledných variant téže struktury: blahoslavený ten člověk a ten blahoslavený člověk jsou jistě spojení s touž závislostní stavbou a chápeme je obě na pozadí vztahu [člověk → blahoslavený] → ten. (Blahoslavený ten člověk a tím spíše blahoslavený člověk ten mohou být ovšem i realizacemi neslovesné predikace, kterou bychom mohli zapsat jako
S1 → (Vf →) A;
| ↑
explicitní realizací tohoto vzorce by bylo např. Blahoslavený budiž ten člověk.)
V jiných případech však pořádek slov signalizuje i různost syntagmatické struktury a tím i významu: není synonymní těchto několik pravidel a několik těchto pravidel: užijeme-li věty Zapomněl jsem těchto několik pravidel, chceme asi říci, že jsem zapomněl všechna, o nichž se mluví, a že jich bylo několik, zatímco větu Zapomněl jsem několik těchto pravidel spíše interpretujeme tak, že jde o několik, část z větší skupiny pravidel, k níž odkazujeme, tedy asi ve smyslu „několik z těchto pravidel“. Taková skupina může být označena i počtem, jako „skupina S o počtu q“: přišli ohlášení tři návštěvníci (ve smyslu ‚přišla ohlášená trojice návštěvníků‘). Jako A tu však může fungovat dost omezený počet adjektiv.
Bez výrazného významového rozdílu lze zaměňovat pořádek I, Q v spojeních ten celý — celý ten, ti všichni — všichni ti. Jde opět o varianty, zčásti plynoucí z funkce výrazů celý, všechen, která zpravidla implikuje jednoznačné ukázání.
3.2 Danešova práce se podrobněji nezabývá rozvíjením symbolu PRON. Budeme-li se pokoušet formulovat odpovídající pravidla, zjistíme, že je přípustné, byť i pro omezený okruh, PRON → A (já ubohý), PRONpl → Q (my dva, málo nás (pochopilo …)), ale nebude PRON → I (*tito oni). Zdá se totiž, že substituce S/PRON by měla vlastně být formulována jako [S → I]/PRON; to odpovídá představě, že zájmena osobní implikují v sobě odkazování k jedinečnému, a proto také vylučují neurčité odkazování. Prvky I ve spojení s PRON (míní se tím PRONp) jsou tudíž buď nadbytečné, nebo protismyslné.
Snad by stálo za povšimnutí i to, že závislost S → A, S → I je poněkud jiného druhu než S → Q: zatímco v prvně uvedených vztazích jde o plnou kongruenci rodu, čísla i pádu, v poslední je gramatické číslo řízeno jinak závislým Q, a to jeho sémantikou. To znamená, že ve vztahu S → Q musí být ponechána neutrální charakteristika gramatického čísla až do stadia, kdy bude Q lexikálně obsazeno.
3.3 O slovech typu někdo, kdosi, kdokoli, leccos, nic atd., jsme v odst. 2.1 konstatovali, že z hlediska větných vzorců se chovají jako S. Pokud jde o rozvíjecí pravidla, existuje pro ně jedno omezení: nemohou být rozvíjena podle pravidla S → S1 (král Karel, ale *kdosi Karel). Jinak jsou substituce možné: (to [41]dokáže) kdokoli odvážný, (potřebujeme někoho) na těžkou práci, (dejte mi) něco pít, (tady je) něco otci, (požádej) kohokoli doma; (ten člověk je) schopný lecčeho, (byla to) ruka kohosi (neznámého), (nemám rád) řeči o ničem.
Chceme upozornit na ten detail, že něco a jiná zájmena neosobová mají závislé A v genitivě, i když jsou sama v pádě prvém. Kdybychom použili způsobu zavedeného zde pro číslovky, mohli bychom tvary něco, nic, cosi, cokoli atd. rovněž označit indexem n a chápat vztah něco pěkného jako Sn → A. Tomu odpovídají i ostatní pády; máme podle očekávání gen. něčeho pěkného, dat. něčemu pěknému atd. Zdálo by se, že jako Sn tu může fungovat i mnoho, které je jinak Q; týká se to však jen tohoto tvaru; další pády se realizují skloňováním řídícího členu, zatímco závislý je v genitivě, např. 7. sg. množstvím neznámého, takže jde o paralelu k S → S2. Nejjednodušší výklad je takový, že neznámého je substantivizované adjektivum a mnoho — aspoň pro potřebu našeho popisu — tvarová varianta subst. množství, podobně jako trochu lze považovat za variantu subst. trocha; gen. je jen trochy jablek, dat. troše jablek …
V předchozích úvahách jsme došli k některým zpřesňujícím úpravám vzorců a pravidel. Je nyní nutno si ověřit, jak se v jejich světle projevují výrazy typu někdo. Zjišťujeme, že rozvíjecí pravidla S = S → I, S = S → Q nelze na ně aplikovat, chápeme-li zmíněné výrazy jako S: neobjevuje se *tento někdo, *nějaký kdokoli, *dvě cosi apod., nýbrž jen kdokoli odvážný, cosi zajímavého.
Ukazuje se tedy, že nemůžeme výrazy typu někdo zařadit mezi S bez nesnází. Nabízí se ještě možnost chápat je jako PRONp. (Je totiž zřejmé, že PRONp musí být zavedeno do vzorců a pravidel případ od případu a že substituce S/PRON neplatí obecně.) Zjišťujeme však, že neplatí PRONp = PRONp → prS, ani PRONp = PRONp → INF, rovněž ne S = S → PRONp2,3,7, kde všude může být zájmeno toho typu, kterým se nyní zabýváme, jako substitut S. Můžeme tedy říci, že zájmena typu někdo, cosi jsou co do syntaktické aplikovatelnosti přechodem mezi S a PRONp, aniž je lze do některé z těchto tříd bez omezení zahrnout. Odlišíme je jako PRONind (pronomina indefinita), přičemž některá pravidla bude možno formulovat pro PRON jako celek (např. PRON = PRON → A, kdokoli odvážný, já ubohý; S = S → prPRON, řeč o něčem, o něm).
4. V odstavci 3.2 jsme uvedli, že omezení ve výběru závislého symbolu můžeme též vyjádřit vhodně formulovaným substitučním pravidlem. Na témž principu nyní formulujeme i substituci zavádějící PRONind, a to jako [PRONp → Q]/PRONind. Kdybychom tyto vztahy pro názornost zapsali generativním stromem, zobrazili bychom fáze rozvíjení základového S — zároveň s dvěma potenciálními stadii pronominalizace — asi takto:
| S /\ I S … / PRONp /\ Q S … / PRONind /\ A S |
Přítomnost PRONp v substituovaném výrazu má za následek variaci osoby u Vf závislého na PRONind; konečně sama posloupnost PRONp → Q se již v našich úvahách objevila, a to jako hypotetický základ subjektu ve větách typu [42]každý dostaneš / dostane nocleh, dva dostaneme / dostane / dostanou nocleh (viz odst. 2.4). S tím je pak zcela ve shodě, že subjektem takových vět může být i PRONind: někdo, kdokoli dostaneš / dostane / dostaneme … nocleh, podobně nikdo nedostanete / nedostanou … Mohli bychom tedy i symbolu PRONind připisovat index osoby. Nejde ovšem o morfologickou charakteristiku samého zájmena, nýbrž o postižení „hloubkového“ elementu, kterým vysvětlujeme morfologickou vlastnost slovesa.
Z toho plyne, že ani v těchto případech bychom nemusili považovat výrazy někdo, kdokoli, nikdo za doplňky a např. větu Nikdo jsme nespali lze interpretovat jako PRONind 1pl → Vf, nikoli
S1 → (Vf →) PRONind.
| ↑
V doplňkové funkci se objevují tato zájmena jen v okrajovém typu vět jako Účastníci se vraceli někdo autem, někdo vlakem; je pochopitelně možný i „doplněk u doplňku“ Vraceli se někdo spokojen, někdo zklamán.
4. Pravidly rozšiřovacími se tu podrobněji zabývat nebudeme. Nepochybně by se však ukázalo, že i ona vyžadují odlišení A, Q, I a PRONp, PRONind. Zatímco pravidla A = A1 + A2 …, Q = Q1 + Q2 …, stejně jako PRONp = PRONp1 + PRONp2 … jsou zřejmě přípustná (srov. silný a odvážný, dva a tři, já a ty), stěží to platí o I = I1 + I2 (*tento a nějaký) a o PRONind = PRONind1 + PRONind2 (*něco a cosi). Některá omezení v tomto směru mají též charakter sémantické „idiosynkrasie“ (objeví se dva a tři, ale sotva dva a mnoho jako přívlastky téhož S), bude též nutno odlišovat, o jaký vztah mezi symboly při rozšiřování jde: srov. *měl žádné a málo zpráv, ale měl žádné nebo málo zpráv).
5. Z našich úvah tedy vyplynulo, že pro potřebu syntaktického popisu v termínech větných vzorců bude nutno detailněji diferencovat některé symboly, ale zároveň že postulované třídy umožní — při malých úpravách morfologických charakteristik — provést některá prospěšná zobecnění. To je zajímavé z hlediska externí funkce jazyka: výrazy třídy Q vyčleňují v konkrétních výpovědních aktech z třídy pojmenovaných objektů množinu prvků, k nimž se vytváří vztah reference (třída „letadlo“ - tři letadla), zatímco slova klasifikovaná jako I specifikují typ tohoto vztahu (srov. tato tři letadla - jakási tři letadla - kterákoli tři letadla). Výrazy typu někdo jsou „zkratky“ frází složených z těchto prvků a z obecného pojmenování třídy např. živých bytostí. Existuje-li mezi touto funkcí a syntaktickou klasifikací jistý paralelismus, je to zjištění pozoruhodné, poněvadž ani nivelizující třídění na syntaktická substantiva a adjektiva, ani poněkud chaotická diferenciace na základě morfologicko-sémantickém neposkytují tak spolehlivé předpoklady pro třídění slov, jimiž jsme se tu zabývali.
R É S U M É
Syntactic Value of Some Pronouns and Numerals
The so-called demonstrative, indefinite, delimitative and negative pronouns and definite and indefinite cardinal numerals are said to constitute a varied group of [43]words in Czech, within which the limits are, in details, even not unanimously accepted. This variety roots, however, in the selection and treatment of morphological and semantical classificatory criteria. On the other hand, there exists a statement that in syntax, the given units behave like nouns or adjectives; we consider it oversimplified. The application of syntactic analysis in terms of sentence patterns and derivative rules (as proposed by F. Daneš) shows that for the syntactic purposes it is advantageous to constitute more homogenous word-classes, corresponding to classes based on the function of the given words in rendering extra-lingual reality in particular utterance acts. They are I (demonstrative and indefinite “adjectival“ pronouns like tento, nějaký), Q (numerals, delimitative and negative “adjectival“ pronouns, e.g. dva, pět, všichni, žádný) and PRONind (“substantival“ pronouns like někdo, kdosi, nikdo). Viewed from the point of patterns and rules, their behaviour is apparently distinct both from that of the other nouns and adjectives and from each other.
At the same time, a syntactic analysis of Czech numerals is suggested (most of them are usually interpreted as nouns, if the phrase is in Nominative — Accusative, and as adjectives in the other cases): it applies morphological characteristics n, either replacing Nominative-Accusative, or signalling homonym with Genitive. It was also necessary to touch the problems of substitution (esp. which type of pronominalization pertains to a given level of syntagm) and of potential ruling symbols in the phrases with Q, PRONind, whose introduction accounts for variability of person in verbum finitum depending on them.
[1] K otázkám křížení kritérií slovnědruhové klasifikace viz B. Havránek, Řadění slovních druhů v mluvnici, Rusko-české studie, sb. VŠP v Praze, Jazyk a literatura II, 1960, zvl. s. 466.
[2] F. Daneš, Syntaktický model a syntaktický vzorec, Čs. přednášky pro 5. mezinárodní sjezd slavistů v Sofii, Praha 1963, s. 115—124; týž, K systematickému syntaktickému popisu slovanských jazyků, SaS 26, 1965, 112—118.
[3] Podrobnější výklad symbolů viz první práce citovaná v pozn. 2. Zde uvádíme aspoň jako příklad: S1 … substantivum v nominativě, Vf … verbum finitum, S … substantivum v nepřímém pádě, pr PRONp … zájmeno osobní v pádě předložkovém. Šipky → označují směr závislosti v syntagmatu, lomítko / je symbolem substituce, rovnítko = spojuje základní a derivovaný (rozvitý) výraz.
[4] Např. Vl. Šmilauer, Novočeská skladba2, Praha 1966, s. 177 a 186.
[5] Viz F. Kopečný, Základy české skladby2, Praha 1962, s. 52 a 149.
[6] K tomu viz např. B. Havránek -A. Jedlička, Česká mluvnice, Praha 1963, s. 233.
[7] Viz I. Poldauf a K. Šprunk, Čeština jazyk cizí, Praha 1968, s. 233.
[8] Srov. F. Kopečný, o. c. v pozn. 5, s. 267. Jeho příklady jsme upravili do podoby pokud možno paralelní s vzorci.
[9] O. Uličný, O syntagmatické a transformační charakteristice doplňku, SaS 30, 1969, zvl. s. 19.
[10] V této souvislosti připomínáme, že v cit. knize I. Poldaufa a K. Šprunka Čeština jazyk cizí, s. 300, se uvádějí vedle substantiv a zájmen kvantitativa (číslovky a podobné výrazy) jako jeden ze slovních druhů, kterými se vyjadřuje podmět.
Slovo a slovesnost, volume 31 (1970), number 1, pp. 33-43
Previous Dell Hymes (USA): Lingvistická teorie a promluvové funkce
Next Slavomír Utěšený: K jazykovému vývoji v pohraničí českých zemí
© 2011 – HTML 4.01 – CSS 2.1