
Počítačová lexikografie a čeština (počítačový fond češtiny)
František Čermák, Jan Králík, Karel Pala
[Discussion]
Computational lexicography and Czech language (computational fund of Czech)
Český jazyk je nejcennějším národním statkem, bezprostředním nositelem identity národa a v tom smyslu základní národní kulturní hodnotou. Povinnost a potřeba archivovat jeho poklad – lexikální i textový – stojí proto i v moderní době mimo jakoukoli pochybnost.
Současný stav
Uchování a výzkum existujících slovníků a textů, doplňování a neustálá aktualizace datového tezauru jsou dnes velmi efektivně dostupné pomocí počítačů. Třebaže stav, o kterém zde bude také řeč, se jeví více než nepříznivě, není naštěstí nezměnitelný, bez naděje na výhled. Změna však nenastane samovolně, ba je jisté, že si vyžádá extrémního úsilí. Tím spíš je však také jisté, že na ní nelze začít pracovat bez předběžného ujasnění a zmapování cílů a cest, které k nim mohou vést. Na rychlost tohoto řešení naléhá celkový kontext problému.
Dnešní vybavení české lexikografie, jež je doma na půdě Ústavu pro jazyk český (ÚJČ), je muzeum ručně psaných kartoték s více než 12 000 000 lístků, které sotva dávají tušit, že v civilizovaném světě – v západní Evropě a v USA – už dnes neexistuje lexikografie jiná než počítačová. Zatímco v ÚJČ je metoda práce v roce 1991 v podstatě táž jako před 80 léty při založení Kanceláře slovníku jazyka českého, významné slovníky větších i menších evropských jazyků (angličtiny, němčiny, francouzštiny, španělštiny, italštiny, nizozemštiny, maďarštiny) jsou dnes vytvářeny výhradně pomocí počítačů a zcela samozřejmě existují také v tzv. počítačově čitelné podobě, ať je to Longman Dictionary of Contemporary English, Collins Cobuild English Language Dictionary, Merriam–Webster English Dictionary, New Collegiate Dictionary, Oxford Advanced Learner’s Dictionary of Current English či mnohé další. Počítačově čitelné slovníky slouží jako východisko pro tvorbu rozsáhlých lexikálních databází, které se stávají zdroji dalších typů slovníků včetně běžných slovníků úzce účelových, specializovaných, oborových, dvojjazyčných i vícejazyčných. Do tohoto výčtu náleží rovněž slovníky pro počítačové zpracování přirozeného jazyka, včetně strojového překladu a oboru umělé inteligence.
U nás ojedinělé počítačově čitelné slovníky – Retrográdní slovník současné češtiny (Academia 1986) a Anglicko–český výkladový slovník výpočetní techniky (SNTL 1990) – získaly tuto svou podobu jen víceméně bezděčně, dík snaze autorů vyjít vstříc fotosazbě, a uchovaly si ji pouze pro usnadnění nové či alternativní edice. Retrográdní slovník přitom má v počítačově čitelné podobě také svou obvyklou abecední verzi, vydanou jako interní tisk (Frekvenční slovník češtiny věcného stylu). Třetím počítačově čitelným českým slovníkem bude nová verze Slovníku spisovné češtiny, připravovaná v ÚJČ s výhledem pro přepracované vydání.
Různá akademická a univerzitní pracoviště si pro svou potřebu připravila celou řadu vlastních – i velmi rozměrných – slovníkových databází (pracovníky Výzkumného ústavu matematických strojů a Střediska výpočetní techniky ČSAV vypracovaný automatický korektor J. Hajiče a J. Drózda zahrnuje 100 000 českých lexikálních jednotek, [42]na katedře českého jazyka filozofické fakulty Masarykovy univerzity byl K. Palou a dalšími připraven automatický korektor se slovníkem tvořeným 170 000 českými kmeny, táž katedra má k dispozici kompletní heslář SSJČ v rozsahu 200 000 položek, v Ústavu teorie informace a automatizace bylo v automatizované bázi lexikálních jednotek soustředěno a sémantickým kódem opatřeno na 400 000 českých položek atd.). Nekoordinovanost a vzájemná neinformovanost však způsobily naprostou obecnou nekompatibilitu takových korpusů nejen v zápisovém kódu (vedle LATIN 2 a kódu bratří Kamenických se užívá i KOI–8 CS2 a množství dalších), ale také ve způsobu zpracování a uložení. Tím je praktické využití mnoha cenných dat omezeno vlastně jen na místo jejich vzniku. Koordinační úsilí „Iniciativní skupiny pro přípravu počítačových korpusů textů a slovníků”, ustavené 3. 10. 1988 nejprve se záštitou Kybernetické společnosti, posléze i v rámci Jazykovědného sdružení při ČSAV (za účasti zástupců matematicko–fyzikální fakulty Univerzity Karlovy, Ústavu pro jazyk český, Výzkumného ústavu matematických strojů, Videopressu Mezinárodní organizace novinářů, katedry češtiny filozofické fakulty Univerzity Jana Evangelisty Purkyně (nyní Masarykovy univerzity), Vysoké školy ekonomické, Čs. střediska výstavby a architektury a později i Ústavu vědeckotechnických a ekonomických informací aj.) se zatím mohlo uplatnit pouze jako pole pro vzájemné zprostředkování informací. Toto úsilí, navazující na předcházející zkušenosti uvedených pracovišť a na publikované diskuse (viz zejm. Králík, 1987; Panevová – Sgall, 1987; Hajičová, 1988; Bémová – Králíková, 1988), nemohlo tehdy ovšem padnout na úrodnou půdu.
Pohled do zahraničí je v tomto směru velmi poučný. Řada jazykovědných pracovišť má k dispozici plně kompatibilní počítačové vybavení, minipočítače i v lokálním propojení (LAN) i celé pracovní stanice, samozřejmostí je napojení na velké počítačové uzly evropských a celosvětových počítačových a informačních sítí (např. BITNET, EARN, EUNET, DFN aj.). Značně vyspělé a na běžné komerční bázi rozšířené je i programové vybavení lexikografických pracovišť, zejména programy MicroOCP (pro texty zapsané jako „ASCII–soubory”) a WordCruncher (pro texty zapsané editorem WordPerfect). Ze všeho nejpodstatnější je však plná koordinace a zřetelná snaha o sjednocování metodiky lexikografické práce.
Ze zahraničí v tomto směru působí nejen příklad, ale dokonce i aktivní tlak. V rámci Rady Evropy vytvořily země Evropského společenství v roce 1986 sdružení Language Industries (viz Deklarace z Tours, 1986), jehož cílem je uchovat dědictví evropských jazyků využitím současných metod zpracování informací a počítačové technologie. S tím spojené problémy v zemích střední a východní Evropy (Československo, Maďarsko, Polsko, Jugoslávie, Bulharsko, evropská část Sovětského svazu) mapovalo pravidelné sympozium sdružení Language Industries, konané v listopadu 1990 v Maďarsku. Část programu byla věnována hledání cest, které povedou k plnému začlenění zemí střední a východní Evropy do Evropského společenství právě i jejich úrovní počítačové lexikografie. Jednoznačně bylo konstatováno, že základní podmínkou začlenění ČSFR do sdružení Language Industries je existence kvalitních národních lexikografických projektů pro češtinu a slovenštinu, které jediné mohou být východiskem užitečné multilaterální spolupráce, a tím i základem pro společenstvím zaštítěnou finanční pomoc.
Za ČSFR byl na sympoziu prezentován projekt slovenský, připravený a již započatý Jazykovedným ústavem Ľudovíta Štúra, jehož jménem referoval V. Benko. Na rozdíl od něho referent z České republiky K. Pala z katedry českého jazyka FF Masarykovy univerzity v Brně musel bohužel konstatovat, že v oblasti počítačové lexikografie pro češtinu dosud žádný reprezentativní projekt neexistuje; k dispozici jsou pouze projekty dílčí, například na půdě ÚJČ souhrnně obsažené v interní informaci o současném stavu v oblasti počítačového zpracování češtiny (Zpráva pro vedení ÚJČ předložená 18. 6. 1990 J. Králíkem). Pokud nemá ČSFR úplně ztratit kontakty s evropskými aktivitami v oblasti počítačové lexikografie a ještě výrazněji než dosud zaostat po stránce [43]metodologické i technické a v důsledku toho i v kultuře jazyka a skrze ni i v kultuře nejširší společnosti, musí reagovat bez prodlení. Možnosti, které by se otevřely dosažením žádoucího stavu, předčí všechna běžná očekávání, odrazí se v pohledu na celou národní kulturu v evropském a světovém kontextu, a tím zpětně i v kvalitnějším uspokojení kulturních a materiálních potřeb celého národa. Nejde tedy jen o věc výhradně jazykovědnou.
Tím spíše je třeba nejen co nejdříve ujasnit a dopracovat dosud pouze naznačený a velmi stručně načrtnutý lexikografický projekt, ale také podniknout veškeré možné kroky k získání finančních prostředků pro jeho realizaci. Naléhavost tohoto apelu je umocněna závazky vyplývajícími z přijetí ČSFR do Rady Evropy v únoru 1991.
Východiska
Pomiňme zatím nezbytná východiska lingvistická, ze kterých vychází opatřování slovních výskytů v textových korpusech kódy (značkami) mluvnických, stylistických, popř. dalších charakteristik jako podkladu pro počítačové slovníky. Vedle pojmových soustav vypracovaných pro tyto a podobné účely v Ústavu pro jazyk český ČSAV, na matematicko–fyzikální fakultě UK (v rámci funkčního generativního popisu), v Ústavu slovanských studií filozofické fakulty UK a na dalších našich pracovištích tu bude důležitá také experimentální automatická analýza české syntaxe, jež by byla použitelná pro semiautomatické zakódování syntaktických charakteristik. Toto vědomé zestručnění nám umožní soustředit pozornost na technickou stránku věci.
Technické vybavení ÚJČ jako centrálního lexikografického pracoviště je mnohem zanedbanější než kteréhokoli jiného akademického nebo vysokoškolského pracoviště. Oddělení lexikologie a lexikografie disponuje výpočetní technikou teprve od podzimu 1990 v podobě jediného osobního počítače ZENITH 386. Jediným legálním programovým vybavením (softwarem) je dosud pouze MS DOS 3.3 a editor T602.
Velkým vkladem a zárukou rychlé přizpůsobivosti jsou naopak dlouhodobé zkušenosti pracovníků ÚJČ ve využívání počítačů mimo ústav. Především je tu plných patnáct let denního kontaktu s počítači, udržovaného až do roku 1985 bývalým oddělením matematické lingvistiky, odkud vyšly nejen dva výše uvedené slovníky, ale také velmi cenné datové soubory: dosud unikátní korpus 180 textů o více než 540 000 slovech s téměř pěti milióny údajů o jejich morfologických a syntaktických charakteristikách. Nejen o výsledcích, ale i o metodice těchto prací existuje řada publikací (srov. zejm. Těšitelová, 1985; Králík, 1982, 1987). Vedle specifického využití počítačů na půdě ÚJČ ve fonetice tu stojí i zcela aktuální zkušenosti oddělení onomastiky (záznam, různá třídění hesláře pomístních jmen), oddělení jazykové kultury (záznam, třídění a rešerše v rejstříku Pravidel) a oddělení valenční syntaxe (záznam hesel valenčního slovníku) – to vše již pomocí osobních počítačů, byť zčásti mimo ÚJČ.
Na univerzitní půdě mají svůj význam pro lexikografické stejně jako pro gramatické zpracování výsledky a zkušenosti skupiny komputační lingvistiky koordinované P. Sgallem (viz zejm. Panevová a kol., 1981; Cejpek a kol., 1982; Panevová, 1982; Kirschner, 1983; Hajič, 1984; Sgall a kol., 1984; Oliva, 1989; Králíková – Panevová, 1990).
Cíl projektu
Základním cílem je vybudovat počítačový fond češtiny a radikálně modernizovat všechny lexikografické práce. Hlavním výstupem budou moderní edice různých typů slovníků výkladových, výběrových i oborových, dvojjazyčných i vícejazyčných (komparačních), jejich operativní obměny a aktualizace, zejména vydání a obnovování v mezinárodně standardizované počítačově čitelné podobě. Nepominutelnou důležitost má také efektivní metodologická integrace s celosvětovými trendy a vstup tezauru češtiny do mezinárodních informačních sítí.
[44]Obrys projektu
Účastníci několika konzultačních schůzek zainteresovaných lingvistů a odborníků v oblasti výpočetní techniky – schůzek iniciovaných K. Palou (z FF MU v Brně) – z ÚJČ J. Králík a V. Schmiedtová, z ÚJČ i z FF UK F. Čermák a z FF UK K. Kučera, potvrdili 21. 1. 1991 společný záměr a 14. 2. 1991 přijali za účasti P. Sgalla z FF UK, E. Hajičové z MFF UK a J. Hajiče z VÚMS myšlenku vypracovat a uvést v život základní verzi projektu lexikografického počítačového korpusu a tezauru češtiny („počítačový fond češtiny”), představující rozsáhlou a mnohovrstevnou databanku o desítkách miliónů slovních tvarů aj.
Na návrh J. Králíka byl projekt pracovně rozčleněn do tří úrovní procházejících třemi časoprostorovými řezy národním jazykem (jako triáda různých úrovní zpracování aplikovaná na tři oblasti užívání a vývoje jazyka):
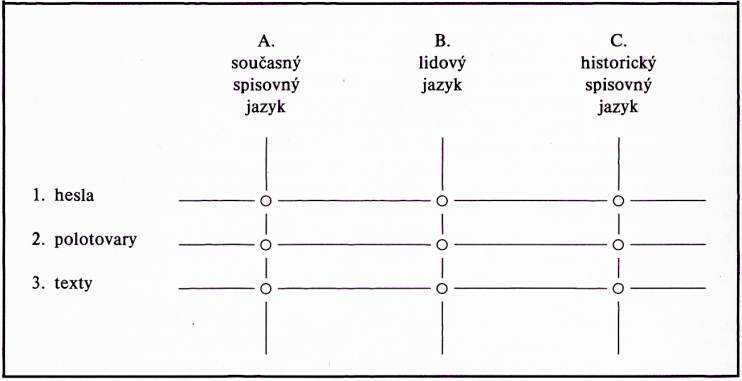
Ad 1: Slovníková hesla (typ: soubory konečných, korigovaných výstupů pro fotosazbu, databáze počítačově čitelných pracovních souborů, množin a podmnožin hesel a termínů různých druhů z různých zdrojů, včetně postupně budované databáze unifikované tvarem hesla daným celoevropskou normou; – vybavení: programy pro zpracování a analýzu slovníkových hesel aj.).
Ad 2: Polotovary hesel (typ: přepisy pracovních a archívních lístkových katalogů, pomocné rejstříky, tezaurus kmenů a kořenů slov, dílčí rešerše výskytů slov v rámci věty, kontexty, konkordance a frekvenčně a retrográdně uspořádané množiny slov i jejich tvarů, kód sémantických charakteristik; – vybavení: programy pro morfologickou a syntaktickou analýzu, lematizátory, programy pro sestavování frekvenčních seznamů, vyhledávání kontextů a sestavování konkordancí aj.).
Ad 3: Textová báze (typ: knihovna pokrývající v relativní úplnosti slovní zásobu moderní češtiny, archív pracovních textů, stratifikovaný výběr textů všech funkčních stylů, kopie nakladatelských verzí novin, časopisů, literárních děl a autorských kompletů; – vybavení: programy pro převod (konverzi) typografických souborů do čisté textové podoby v dohodnutém kódu a v jednotné struktuře aj.).
Ad A: Současný spisovný jazyk (beletrie (i poezie), publicistika, odborné texty, administrativa, mluvený jazyk, osobní jména atd.).
Ad B: Lidový jazyk (interdialekt i slangy a argot), územní dialekty (současné i zaniklé, případně z území mimo ČSFR), místní názvy a pomístní jména, vše psané i mluvené, atd.
Ad C: Historický spisovný jazyk (19. stol. a hlouběji až k památkám a pramenům staročeským tištěným i rukopisným, jazyk českých spisů Komenského, Bible kralické, Husových spisů atd.).
[45]Toto členění vymezuje devět uzlů, z nichž např. uzel 1A představuje přímé podklady pro edici nových slovníků češtiny (i vícejazyčných), uzel 3B by zahrnoval počítačový korpus současných mluvených textů, mezi uzly 2A a 2C by mohl být rozdělen eventuální převod lístkového katalogu archívu ÚJČ do počítačové databáze, zatímco uzel 3A by sloužil i základním analýzám pro vznik nových gramatických monografií a rozvoji textové lingvistiky atd. Pro praktické potřeby je nutno uvažovat i o úplném rejstříku, který by informačně pokryl všechny pracovní databáze.
Uvažovaných devět uzlů představuje řešení vycházející z přístupu sémaziologického. V budoucnu je však možno počítat i s obráceným přístupem onomaziologickým, analyzujícím primárně zejména sémantickou a pojmovou stránku jazyka.
V těchto prvních devíti sémaziologických uzlech se pak také rozpracuje a soustředí realizace projektu. Navržené členění přirozeným způsobem vymezuje význam, intenzitu zpracování i zájmové okruhy, v nichž obvykle jednoznačně dominuje konkrétní pracoviště, jež by se pro realizaci daného uzlu mohlo stát i garantem a koordinátorem.
Hlavním gestorem projektu by byl Ústav pro jazyk český ČSAV, dalšími řešiteli (v první linii) Ústav českého jazyka a slovanské jazykovědy při FF MU, Ústav formální a aplikované lingvistiky na MFF UK, katedra českého jazyka na FF UK, katedra knihovnictví a informatiky na FF UK, Ústav slovanských studií na FF UK, Ústav teoretické a komputační lingvistiky na FF UK, katedra bohemistiky a slavistiky na FF UP, spolupracovaly by Jazykovedný ústav Ľudovíta Štúra a Informačné centrum SAV, Spoločná pracovná skupina počítačovej lingvistiky (V. Benko). Jednota koncepce, garantovaná společným gestorstvím, by přitom měla zaručit jak vzájemnou informovanost, tak především kompatibilitu zpracovatelských přístupů a všem zúčastněným řešitelům také nekomplikovaný přístup k ostatním uzlům projektu.
Podmínky realizace projektu
1. Standardizace kódů záznamu (situace dosud není jednotná: v normě ISO 2022 je pro češtinu zakotven kód KOI–8 CS2 (ČSN 36 9102), v nové normě ISO 6659 je pro týž účel definován kód LATIN 2, existuje verze PCL2, připravuje se normalizace pod názvem KOI–8 L2, velmi rozšířený je však kód MJK = bratří M. a J. Kamenických).
2. Standardizace uložení a zpracování (je třeba sjednotit způsob zpracování typografických textových souborů přepisem ze systémů TeX, TRACT a jiných polygrafických standardů do dohodnutých typů „ASCII–souborů”; současně je třeba rozhodnout o univerzálně přijatelném způsobu uložení a o možnostech pořizování dílčích pracovních kopií (v úvahu přicházejí magnetické pásky a kazety, diskety a perspektivně nepochybně archivace pomocí systému WORM). Pro práci s datovou bází slovníkových hesel není zatím k dispozici vhodný specializovaný databázový systém, který by byl okamžitě a bez výhrad použitelný pro budování české lexikální databáze. Schůdné řešení by mohlo být inspirováno např. projektem TEI (Text Encoding Initiative, C. M. Sperberg – McQueen & Lou Burnard, 1990), který umožňuje ukládat slovníková hesla v textové podobě do běžných textových souborů a vyznačovat vnitřní hierarchie uvnitř hesel technikou SGML (Standard Generalized Markup Language).
3. Standardizace editorů pro komentáře edice (v úvahu připadá WordPerfect (5.1), Wordstar, Text 602, ev. Chiwriter, K–Edit, CSED, vždy z podmínkou konvertovatelnosti zapsaného textu do univerzálně kompatibilního tvaru „ASCII–souborů”) a sblížení pracovního softwaru (zřejmě FoxBase, dBASE IV, pod systémem UNIX databázový systém ORACLE nebo INFORMIX aj.); nově zaváděný úzus vede k čisté formě textových souborů.
4. Vyřešení právních vztahů (podmínky pořizování kopií a užívání již publikovaných textů, ujasnění vztahů k autorům a nakladatelstvím i na základě zahraniční zkušenosti, [46]vypracování vzorových smluv, jasné smluvní řešení práv a povinností řešitelů, ochrany a integrity soustředěných dat a výsledků výzkumu).
5. Vyřešení finančního krytí (doplnění počítačového vybavení (PC) jednotlivě i v lokální síti, centrální počítač typu RS 6000 (IBM), SUN 4 nebo MIPS 3000 s operačním systémem UNIX, s vnitřní pamětí od 8 MB a diskovou pamětí od 1 GB výše, s lokální sítí ETHERNET tvořenou 10 až 15 počítači PC AT 386 SX (s pevnými disky o kapacitě 40 až 80 MB), s řádkovou tiskárnou, se systémem PostScript a vhodnou laserovou tiskárnou, se zařízením CD ROM+WORM, kvalitním scannerem a s profesionálním programovým vybavením – sítě, transferů, scanneru i ryze pracovních lexikografických postupů (MicroOCP/Oxford Concordance Program, WordCruncher, nebo nestandardní Lexicographer Workstation Calzolari – Picchi); ke standardnímu vybavení náleží rovněž dva kancelářské kopírovací přístroje (xeroxy), dvě přímé telefonní linky a fax; v tomto smyslu je nutná proporcionální sponze všech zúčastněných řešitelů, zejména lexikografického oddělení ÚJČ).
Finanční vybavení
Osobní počítače, kvalitní řídící počítač, CD ROM+WORM a scanner, laserové tiskárny typu HPLJ II D nebo III, kopírovací a rozmnožovací přístroje typu Minolta EP 3215 (nebo podobné) a fax představují vybavení, jehož pořizovací cena by dnes neměla v úhrnu přesáhnout 2,5 miliónu korun.
Potřebné standardní i nestandardní programové vybavení (včetně operačního systému UNIX) lze získat s pořizovacím nákladem zhruba 500 000 Kčs (ať už by šlo o nákup programového vybavení firemního, nebo o úhradu honorářů programátorům). Dalším předpokladem je vytvoření osmi až deseti systemizovaných pracovních míst včetně dvou až tří míst pro inženýry programátory.
Celkové náklady na uvažovaný projekt by tedy nemusely přesáhnout 3,5 miliónu Kčs. Pro jazyk desetimilionového národa je to částka více než skromná. Bez zajištění sponzorů a dotací – pouze prostředky ÚJČ ČSAV a ostatních pracovišť – je však takový projekt neuskutečnitelný. Přípravná skupina odborníků, kteří vypracovali základní rozvržení tohoto projektu (Skupina pro počítačový fond češtiny, IČO 416 95917, bankovní spojení ČSTSP Praha 0800/2044 345-018, kontaktní adresa Letenská 4, 118 51 Praha 1-Malá Strana), se v současné době obrací na naše i zahraniční instituce. Pokud by pomoc nemohly poskytnout, zůstala by ve hře – vzhledem k povaze a naléhavosti projektu – pouze varianta obrátit se k národu a organizovat sbírky.
Mezinárodní souvislosti
Koordinačním pracovištěm sdružení Language Industries pro země střední a východní Evropy je v současnosti Jazykovědný ústav Maďarské akademie věd (Nyelvtudományi intézet), dalším blízkým aktivním pracovištěm LI je Institut J. Štefana v Lublani, který má jak vhodnou zeměpisnou polohu pro perspektivní koordinační postavení v celé východoevropské oblasti, tak velmi dobré technické vybavení (počítače typu VAX/VMS a zapojení do evropských sítí). Existují kontakty s dalšími pracovišti (Pisa, Paříž, Moskva, Krakov, Záhřeb).
Vzhledem k několika značně pokročilým vícejazyčným překladovým projektům je přitom třeba počítat s napojením tohoto projektu i na normu, která v Evropě převládne pro účely strojového překladu, podle projektů podporovaných Radou Evropy a Evropskými společenstvími.
[47]LITERATURA
Anglicko–český výkladový slovník výpočetní techniky. Ed. O. Minihofer. SNTL, Praha 1990.
Bémová, A. – Králíková, K.: K otázkám automatického zpracování českého tvarosloví. SaS, 49, 1988, s. 185–195.
Benko, V.: Slovak language lexical database. In: Conference on Computer Lexicography. Balatonfüred 1990.
Boguraev, B. – Briscoe, T. (eds.): Computational Lexicography for Natural Language Processing. Longman, London – New York 1989.
Calzolari, N. – Picchi, E.: Lexicographer’s Workstation. In: Conference on Computational Lexicography. Balatonfüred 1990.
Cejpek, J. – Hajičová, E. – Kirschner, Z. a kol.: Automatické vyhľadávanie informácií z úplného textu. Bratislava 1982.
Čermák, F.: Nizozemský lexikografický projekt století. SaS, 48, 1987, s. 227–231.
Deklarace z Tours. Language Industries. Tours 1986.
Drózd, J. – Hajič, J.: Kontrola českého pravopisu na PC. In: Proceedings of AI’90. Praha 1990, s. 215–222.
Hajič, J.: KODAS – A Simple Method of Natural Language Interface to a Database. Praha 1984.
Hajič, J. – Drózd, J.: Spelling checking for highly inflected languages. In: Proceedings of COLING’90. Helsinki 1990, sv. 3, s. 358–360.
Hajičová, E.: Přejděme od diskuse k práci. JazAkt, 25, 1988, č. 3–4, s. 161–162.
Kirschner, Z.: MOSAIC – A Method of Automatic Extraction of Significant Terms from Texts. Praha 1983.
Králík, J.: Technika zpracování hromadných dat. In: M. Těšitelová a kol., Kvantitativní charakteristiky současné české publicistiky. Linguistica II. ÚJČ ČSAV, Praha 1982, s 72–80.
Králík, J.: Kapitoly o výpočetní technice / k problémům komunikace lingvista – programátor – počítač. ÚJČ ČSAV, Praha 1987.
Králík, J.: Počítače ve službách lingvistů v Budapešti. JazAkt, 27, 1990, č. 1–2, s. 12–18.
Králík, J.: Zpráva pro vedení ÚJČ. Přehled současného stavu a výhledu vztahů ÚJČ – počítače. Interní tisk ÚJČ, 18. 6. 1990.
Longman Dictionary of Contemporary English. Longman, London – New York 1989.
Malý staročeský slovník. SPN, Praha 1978.
Oliva, K.: A Parser for Czech Implemented in Systems Q. Praha 1989.
Pachl, Z.: Čeština v počítači. Abeceda v kódu. Elektronika, 1990, č. 3, s. 8–9.
Pala, K. – Osolsobě, K.: Czech stem dictionary for IBM PC XT/AT. In: Conference on Computational Lexicography. Balatonfüred 1990.
Pala, K.: Computer Lexicography in ČR. November 1990 (rukopis).
Pala, K.: Poznámky k počítačovému lexikografickému projektu pro češtinu. Brno 1991 (rukopis).
Panevová, J.: Random generation of Czech sentences. In: J. Horecký (ed.), COLING 82. Amsterodam 1982, s. 195–200.
Panevová, J. a kol.: Lexical Input Data for Experiments with Czech. Praha 1991.
Panevová, J. – Sgall, P.: Předpoklady počítačového zpracování češtiny. JazAkt, 24, 1987, č. 1–2, s. 58–60.
Pecinovský, R.: Čeština v počítači. Česká a slovenská standardní klávesnice. Elektronika, 1989, č. 10, s. 10–11.
Sgall, P. – Hajičová, E. – Piťha, P.: Učíme stroje česky. Praha 1982.
Sgall, P. – Appelová, A. – Bémová, A. a kol.: Využitie lingvistických metód vo VTEI. Bratislava 1984.
Sinclair, J.: Collins COBUILD English Language Dictionary. W. Collins Sons and Co. Ltd., London 1987.
Slovník spisovné češtiny pro školu a veřejnost. Academia, Praha 1978.
Slovník spisovného jazyka českého. Academia, Praha 1. vyd. 1960, 2. vyd. 1989 (v textu SSJČ).
Smetáček, V.: Automatizovaná báze lexikálních jednotek BALEX. Interní tisky ÚVTEI. Praha 1984–1986.
[48]Staročeský slovník. Díl 1 – 4. Praha 1903–1984.
Těšitelová, M.: Kvantitativní charakteristiky současné češtiny. Academia, Praha 1985.
Těšitelová, M. a kol.: Frekvenční slovník češtiny věcného stylu. Praha 1983. Interní tisk ÚJČ.
Těšitelová, M. – Petr, J. – Králík, J.: Retrográdní slovník současné češtiny. Academia, Praha 1986.
Slovo a slovesnost, volume 53 (1992), number 1, pp. 41-48
Previous Milada Hirschová: Neurčitost komunikačních funkcí ve spontánních mluvených projevech
Next Igor Němec: Vědecké a technické možnosti rozvoje české lexikografie
© 2011 – HTML 4.01 – CSS 2.1